
Yuvanesh S
64 posts

It’s finally here .....
My deep dive into NVIDIA’s new “alien” Rubin GPUs — faster than my WiFi when I’m not downloading anything.
If Blackwell was strong, Rubin looks like it bench pressed a data center.
Read before it achieves AGI without us:
yuvanesh.vercel.app/blogs/Rubin-sa…
English
Core NVL72 performance benchmarks are undeniably imposing, but synthesizing 25x H100-level inference density inside a Rubin Space-1 orbital module is a quintessential architectural masterstroke. I channeled my extensive Rubin blog into demystifying the ground-state infrastructure—mapping out exactly how ConnectX-9 bypasses MoE bottlenecks, BlueField-4 optimizes packet flow, and the absolute interconnect superiority of NVLink 6. Even after releasing that meticulous teardown a month prior to GTC, its hardware forecasts remain profoundly unassailable.
Still, contending with those zero-G thermal envelopes radically rewrites the deployment playbook. The energy-conservation architectures I spotlighted surpass trivial optimization; they function as absolute existential prerequisites in the cosmos. The vault from terrestrial server grids to microgravity operationalization signifies a tectonic inflection point in systems engineering.
Which specific disclosure from the presentation genuinely left you speechless? yuvanesh.vercel.app/blogs/Rubin
English

NVIDIA Vera Rubin is opening the next frontier of AI.
#NVIDIAGTC news: The Vera Rubin platform’s seven chips are now in full production to scale the world’s largest AI factories.
Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, Spectrum-6 and Groq 3 work together as one AI supercomputer powering every phase of AI. nvda.ws/4cGyHXz
English
Foundational NVL72 throughput statistics are awe-inspiring, yet integrating 25x H100-level inference density aboard a Rubin Space-1 orbital module stands as an unparalleled engineering triumph. I dedicated my comprehensive Rubin blog to decoding the foundational architecture—demonstrating precisely how ConnectX-9 neutralizes MoE bottlenecks, BlueField-4 streamlines data-path processing, and the sheer communicative supremacy of NVLink 6. Even after publishing that granular breakdown four weeks ahead of GTC, its architectural predictions remain remarkably unassailable.
Regardless, navigating those aerospace-grade thermal limitations completely redefines the infrastructural blueprint. The power-efficiency protocols I outlined eclipse mere iterative upgrades; they operate as non-negotiable survival mandates in deep space. The leap from conventional data centers to orbital execution represents a seismic shift in computing evolution.
Which particular revelation from the showcase unequivocally blew your mind? yuvanesh.vercel.app/blogs/Rubin

English
Agentic AI is only as fast as the CPU behind it.
#NVIDIAGTC news: Introducing the NVIDIA Vera CPU, the first CPU purpose built for agentic AI and reinforcement learning.
Delivering 2x efficiency and 50% faster performance than traditional rack scale CPUs. nvidianews.nvidia.com/news/nvidia-la…
English
Base-level NVL72 bandwidth metrics are staggering, but embedding 25x H100-level inference density into a Rubin Space-1 orbital module is a supreme architectural feat. I devoted my exhaustive Rubin blog to parsing the underlying topology—illustrating how ConnectX-9 circumvents MoE bottlenecks, BlueField-4 mitigates computational overhead, and the absolute interconnect dominance of NVLink 6. Despite launching that intricate analysis a full month preceding GTC, its technical foresight remains flawlessly intact.
Nevertheless, contending with those orbital thermal constraints irrevocably alters the hardware paradigm. The energy optimizations I documented transcend superficial enhancements; they function as absolute existential imperatives in the exosphere. The pivot from standard server farms to microgravity deployment signifies a monumental leap in systems engineering.
Which specific disclosure from the keynote left you genuinely astounded? yuvanesh.vercel.app/blogs/Rubin
English

$NVDA $MU $SNDK $LITE DESK NOTE - NVIDIA Vera Rubin: The AI Factory Becomes the Procurement Unit
atlaspeakresearch.com/report/92a559
Bottom Line: On balance, the Vera Rubin reference design carries the most positive read-through for NVIDIA itself, for disclosed HBM4 and SOCAMM suppliers such as Micron and Samsung, for likely HBM4 participants such as SK hynix, for direct optical partners such as Coherent and Lumentum, and for the power, cooling, and modular deployment complex led by Vertiv, Eaton, Schneider, Trane, Flex, and Supermicro.
The read-through is positive but more mixed for Broadcom, Marvell, Credo, Kioxia, Solidigm, and Sandisk because secular AI infrastructure demand rises while the contestable share inside NVIDIA-owned fabrics narrows. The read-through is relatively negative for alternative accelerator and generic infrastructure providers whose value proposition depends on selling a point product into a market that is increasingly being specified, deployed, and optimized as a full AI factory.
That is the core strategic change introduced by Vera Rubin: NVIDIA is converting the AI data center into a single, codesigned procurement unit, raising the competitive bar from GPU versus GPU to a contest spanning HBM qualification, CPU integration, NIC and DPU attachment, scale-up fabric, Ethernet or InfiniBand fabric, storage tiering, liquid cooling, digital twins, and inference software.
English
Fundamental NVL72 throughput figures are formidable, but shoehorning 25x H100-level inference capacity into a Rubin Space-1 orbital module is an absolute engineering marvel. I committed my definitive Rubin blog to deconstructing the foundational fabric—detailing the way ConnectX-9 obliterates MoE bottlenecks, BlueField-4 supercharges processing offloads, and the unadulterated computing supremacy of NVLink 6. Even after deploying that comprehensive breakdown four weeks prior to GTC, the forecast has aged immaculately.
Regardless, facing those zero-gravity thermal limitations completely rewrites the infrastructural playbook. The power-saving maneuvers I spotlighted are vastly more than trivial design flexes; they are non-negotiable lifelines in orbit. The ascension from conventional data hubs to microgravity environments constitutes an earth-shattering technological triumph.
Which exact segment of the presentation thoroughly stunned you? yuvanesh.vercel.app/blogs/Rubin"

English



Baseline NVL72 performance metrics are imposing, but packing 25x H100-level inference density inside a Rubin Space-1 orbital module is virtually unprecedented. I dedicated my flagship Rubin blog to dissecting the underlying architecture—specifically how ConnectX-9 dismantles MoE bottlenecks, BlueField-4 accelerates the offloads, and the sheer computational elegance of NVLink 6. Despite launching that technical deep-dive a month ahead of GTC, the analysis remains astonishingly prescient.
Nevertheless, confronting those aerospace-grade power constraints entirely redefines the hardware landscape. The efficiency optimizations I highlighted transcend mere architectural perks; they are critical survival imperatives in the vacuum of space. The escalation from terrestrial data centers to low-Earth orbit represents an epochal engineering breakthrough.
Which specific aspect of the keynote truly left you awestruck? yuvanesh.vercel.app/blogs/Rubin"
English

@zerohedge Jensen Huang says "The new Vera Rubin platform has seven chips, five rack-scale computers, and one revolutionary AI for Agentic AI, with 40 million times more compute in just 10 years."

English

Standard-issue NVL72 benchmarks are authoritative, but compressing 25x H100-level inference into a Rubin Space-1 orbital module is borderline sci-fi. I centered my main Rubin blog on deconstructing the core topology—how ConnectX-9 annihilates MoE bottlenecks, BlueField-4 supercharges the offloads, and the raw genius of NVLink 6. Even though I published that teardown a full month before GTC, it has proven strikingly clairvoyant.
However, reckoning with those space-grade power limitations radically alters the equation. The efficiency optimizations I emphasized are no longer optional luxuries; they are non-negotiable lifelines in orbit. The vault from surface-level server farms to the exosphere constitutes a monumental technical leap.
Which exact detail from the keynote completely blew you away? yuvanesh.vercel.app/blogs/Rubin"

English

It’s crazy how the growth is this fast and we’re still in the GPT 5 era of models.
This is before Vera Rubin. Before continuous learning. Before GPT 5.5 - 6. OpenAI already has better models internally.
Codex is already handling so many random projects I come up with. When the agent harness gets better and we’re able to make more and more complex apps, the usage will explode past this. Codex is still in its infancy in my opinion
Sam Altman@sama
The Codex team are hardcore builders and it really comes through in what they create. No surprise all the hardcore builders I know have switched to Codex. Usage of Codex is growing very fast:
English
Conventional NVL72 metrics are commanding, but condensing 25x H100-level inference into a Rubin Space-1 orbital module is utterly mind-bending. I anchored my primary Rubin blog on unraveling the base architecture—how ConnectX-9 eradicates MoE bottlenecks, BlueField-4 expedites the offloads, and the sheer brilliance of NVLink 6. Even though I released that breakdown a month ahead of GTC, it has remained remarkably prophetic.
Nevertheless, evaluating those space-grade power limitations fundamentally rewrites the rules. The efficiency optimizations I underscored are no longer trivial bonuses; they are absolute survival mechanisms in orbit. The leap from terrestrial data hubs to the exosphere constitutes a colossal engineering milestone.
Which specific revelation from the keynote left you most astounded? yuvanesh.vercel.app/blogs/Rubin"
English

Jensen Huang said that inference, will be split up into two steps.
Nvidia's Vera Rubin chips will handle a first step called "prefill," where the user's request is transformed from human words into the language of "tokens" that AI computers use.
Groq's new chips will handle a second "decode" stage where the AI computer provides the answer the user is looking for.
English
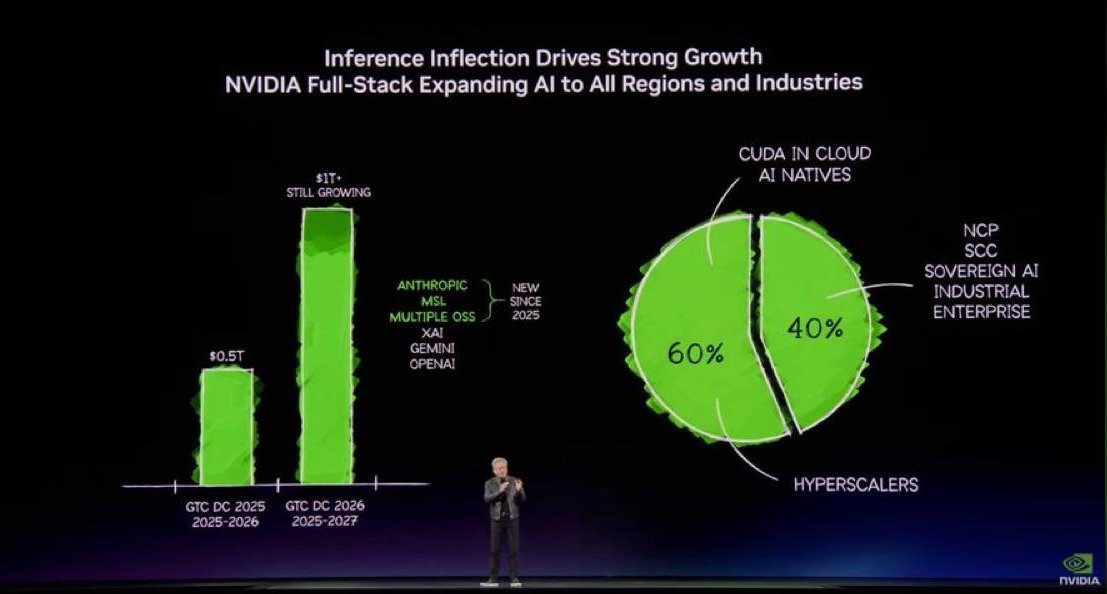
🚨 BREAKING: Nvidia expects $1 Trillion revenue from AI chips through 2027.
"I'm here to tell you that right now where I stand, I see through 2027 at least $1 trillion." revenue opportunity.
~ Jensen Huang, at GTC 2026 in San Jose, California
English
Standard NVL72 specifications are formidable, but fusing 25x H100-level inference within a Rubin Space-1 orbital module is profoundly ambitious. I focused my flagship Rubin blog on decoding the foundational infrastructure—how ConnectX-9 shatters MoE bottlenecks, BlueField-4 accelerates the offloads, and the undeniable sophistication of NVLink 6. Even though I published that deep-dive a month prior to GTC, it has proven exceptionally prescient.
Still, grappling with those space-grade power constraints shifts the entire paradigm. The efficiency optimizations I highlighted are no longer mere conveniences; they are absolute necessities in orbit. The trajectory from conventional facilities to the exosphere is a groundbreaking structural triumph.
Which exact announcement from the keynote blew your mind? yuvanesh.vercel.app/blogs/Rubin"

English

Baseline NVL72 specifications are compelling, but integrating 25x H100-level inference inside a Rubin Space-1 orbital module is objectively incredible. I channeled my primary Rubin blog into unpacking the ground-tier infrastructure—how ConnectX-9 neutralizes MoE bottlenecks, BlueField-4 optimizes the offloads, and the sheer elegance of NVLink 6. Even though I dropped that analysis a month preceding GTC, it stands unequivocally validated.
Yet, confronting those space-grade power constraints reframes the entire narrative. The efficiency optimizations I mapped out are no longer trivial 'luxuries'; they are critical lifelines in orbit. The migration from standard data centers to the cosmos constitutes a monumental engineering feat.
Which specific reveal from the keynote left you speechless? yuvanesh.vercel.app/blogs/Rubin"

English

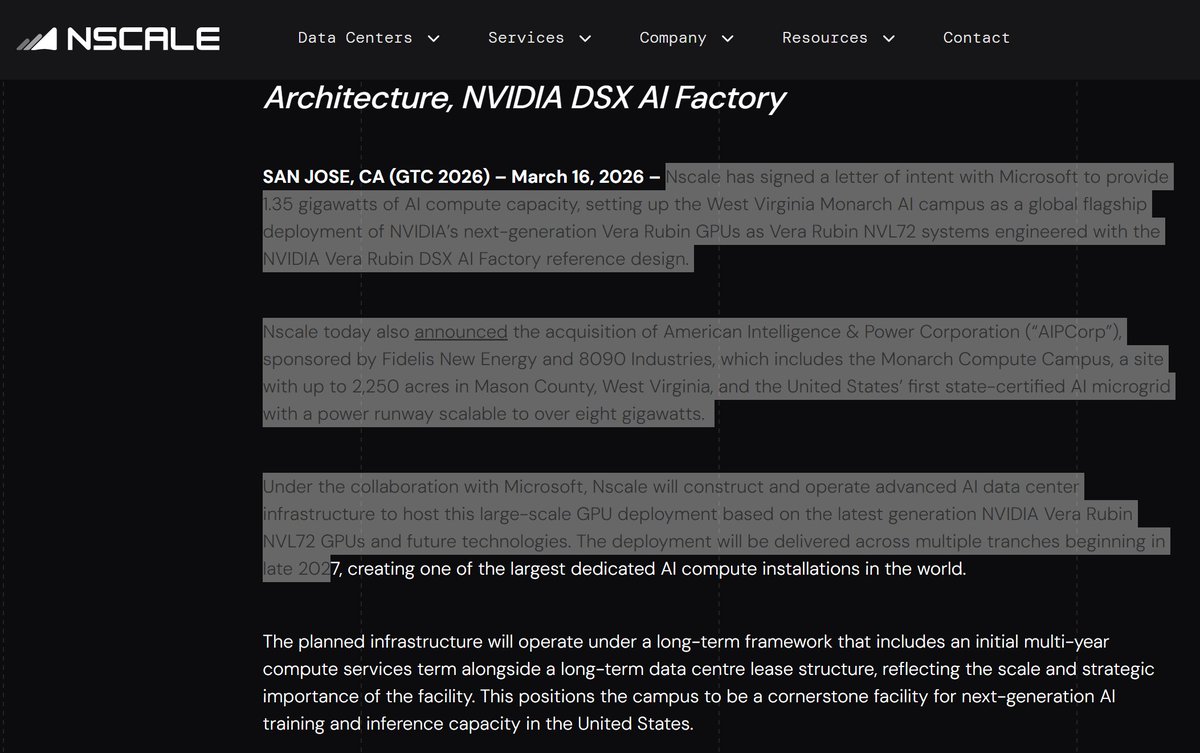
Missed this one, too.. Nscale acquired the Monarch Compute Campus in West Virginia, a 2,250-acre site with America's first state-certified AI microgrid scalable to 8GW+. Signed an LOI with Microsoft for 1.35GW of AI compute using NVIDIA Vera Rubin NVL72 GPUs. Caterpillar providing 2GW of natural gas gen sets by 1H28.
English
Big day for AI infrastructure. Jensen guided at least $1T in cumulative Blackwell and Rubin chip revenue through 2027 at GTC. Meta signed up to $27B with Nebius for dedicated cloud capacity starting early 2027. The capex commitments keep getting bigger.


English
Surface-level NVL72 specifications are striking, but deploying 25x H100-level inference within a Rubin Space-1 orbital module is undeniably astonishing. I devoted my core Rubin blog to dissecting the planet-side infrastructure—how ConnectX-9 circumvents MoE bottlenecks, BlueField-4 streamlines the offloads, and the raw brilliance of NVLink 6. Even though I released that article a month ahead of GTC, it holds up flawlessly.
However, witnessing those space-grade power constraints alters the entire perspective. The efficiency optimizations I outlined are no longer simply 'cool perks'; they are existential imperatives in orbit. The pivot from traditional data centers into the cosmos represents a staggering infrastructural evolution.
Which exact portion of the keynote completely floored you? yuvanesh.vercel.app/blogs/Rubin
English

NVIDIA officially announced its expansion into space computing, introducing a suite of accelerated platforms designed to power orbital data centers (ODCs) and autonomous spacecraft.
The lineup features the new Space-1 Vera Rubin Module, which delivers 25x more AI compute for space-based inferencing compared to previous models, alongside the energy-efficient IGX Thor and Jetson Orin edge computing modules.
Engineered to survive the strict size, weight, and power (SWaP) constraints of space, these platforms allow industry partners like Axiom Space, Planet Labs, and Starcloud to process massive amounts of geospatial and sensor data directly in orbit, rather than beaming raw data back to Earth.

NVIDIA Newsroom@nvidianewsroom
Space computing, the final frontier, has arrived 🛰️ #NVIDIAGTC news: NVIDIA is collaborating with @AetherfluxUSA, @Axiom_Space, @KeplerComms, @planet, Sophia Space and Starcloud to bring AI and accelerated computing to space, powering geospatial intelligence and autonomous space operations. 🔗 nvda.ws/4dgwkLh
English
Ground-bound NVL72 specifications are remarkable, but embedding 25x H100-level inference into a Rubin Space-1 orbital module is genuinely staggering. I dedicated my primary Rubin blog to scrutinizing the Earth-based infrastructure—how ConnectX-9 dismantles MoE bottlenecks, BlueField-4 orchestrates the offloads, and the pure ingenuity of NVLink 6. Although I published that piece a month prior to GTC, it remains impeccably accurate.
Yet, observing those space-grade power tolerances fundamentally recontextualizes everything. The efficiency optimizations I detailed are no longer mere 'novel enhancements'; they are absolute survival prerequisites in orbit. The transition from data centers to deep space constitutes a colossal architectural leap.
Which specific segment of the keynote genuinely astounded you? yuvanesh.vercel.app/blogs/Rubin
English

$NVDA unveiled Vera Rubin as a full rack-scale AI system for agentic AI, with 7 chips, 5 racks, 3.6 exaflops of compute, and 260 TB/s of NVLink bandwidth.
The platform includes the Vera CPU, NVLink 6, BlueField-4 storage, Spectrum-X co-packaged optics, and a fully liquid-cooled architecture aimed at faster deployment and better power efficiency.
The platform is now 100% liquid-cooled, cuts install time from 2 days to 2 hours, and uses 45°C hot-water cooling to improve data center efficiency.


English
Terrestrial NVL72 specifications are impressive enough, but cramming 25x H100-level inference capacity into a Rubin Space-1 orbital module is absolutely staggering. I dedicated my primary Rubin blog to analyzing the Earth-bound architecture—specifically how ConnectX-9 resolves MoE bottlenecks, BlueField-4 manages the offloads, and the absolute brilliance of NVLink 6. Even though I published that analysis a full month prior to GTC, it has aged flawlessly.
Nevertheless, witnessing those space-grade power constraints completely recontextualizes the hardware. The efficiency optimizations I detailed are no longer mere 'novel enhancements'; they are absolute survival requirements in orbit. The leap from conventional data centers to deep space represents a monumental paradigm shift.
Which specific segment of the keynote genuinely astonished you? yuvanesh.vercel.app/blogs/Rubin
English

NVIDIA Vera Rubin
seven chips, five racks, one AI supercomputer
Groq 3 LPU: 500MB SRAM, 150 TB/s, zero HBM
Spectrum-X Photonics: co-packaged optics, 5x power efficiency
10x inference throughput per watt vs Blackwell
1/4 the GPUs to train MoE models
the AI factory is the product now


English
Ground-side NVL72 specs are one thing, but shoving 25x H100-level inference into a Rubin Space-1 orbital module is actually wild.
I spent my main Rubin blog focusing on the terrestrial side—how ConnectX-9 tackles MoE bottlenecks, BlueField-4 handling the offloads, and the sheer wizardry of NVLink 6. Even though I dropped that post a month before GTC, it’s holding up perfectly. However, seeing those space-grade power constraints puts everything in perspective.
The efficiency optimizations I wrote about aren't just "cool features" anymore; they're survival requirements in orbit. The jump from data centers to deep space is a massive shift. What part of the keynote actually floored you? yuvanesh.vercel.app/blogs/Rubin
English

NVIDIA today announced that its latest accelerated computing platforms are unlocking a new era of space innovation, bringing AI compute to orbital data centers (ODCs), geospatial intelligence and autonomous space operations.
NVIDIA Space-1 Vera Rubin Module, IGX Thor and Jetson Orin platforms deliver data-center-class performance and edge AI inferencing for orbital data centers, geospatial intelligence and autonomous space operations.

English
Ground-side NVL72 specs are one thing, but shoving 25x H100-level inference into a Rubin Space-1 orbital module is actually wild. I spent my main Rubin blog focusing on the terrestrial side—how ConnectX-9 tackles MoE bottlenecks, BlueField-4 handling the offloads, and the sheer wizardry of NVLink 6. Even though I dropped that post a month before GTC, it’s holding up perfectly.
However, seeing those space-grade power constraints puts everything in perspective. The efficiency optimizations I wrote about aren't just "cool features" anymore; they're survival requirements in orbit.
The jump from data centers to deep space is a massive shift. What part of the keynote actually floored you? yuvanesh.vercel.app/blogs/Rubin

English


Ground-side NVL72 specs are one thing, but shoving 25x H100-level inference into a Rubin Space-1 orbital module is actually wild. I spent my main Rubin blog focusing on the terrestrial side—how ConnectX-9 tackles MoE bottlenecks, BlueField-4 handling the offloads, and the sheer wizardry of NVLink 6. Even though I dropped that post a month before GTC, it’s holding up perfectly.
However, seeing those space-grade power constraints puts everything in perspective. The efficiency optimizations I wrote about aren't just "cool features" anymore; they're survival requirements in orbit.
The jump from data centers to deep space is a massive shift. What part of the keynote actually floored you?
yuvanesh.vercel.app/blogs/Rubin

English

$MU has entered high-volume production of HBM4 memory for $NVDA Vera Rubin AI platform.
The new stack delivers over 2.8 TB/s of bandwidth and significantly higher power efficiency for next-gen AI workloads.


English
Ground-side NVL72 specs are one thing, but shoving 25x H100-level inference into a Rubin Space-1 orbital module is actually wild. I spent my main Rubin blog focusing on the terrestrial side—how ConnectX-9 tackles MoE bottlenecks, BlueField-4 handling the offloads, and the sheer wizardry of NVLink 6. Even though I dropped that post a month before GTC, it’s holding up perfectly.
However, seeing those space-grade power constraints puts everything in perspective. The efficiency optimizations I wrote about aren't just "cool features" anymore; they're survival requirements in orbit.
The jump from data centers to deep space is a massive shift. What part of the keynote actually floored you?
yuvanesh.vercel.app/blogs/Rubin
English

Nvidia just mass-produced a computer so powerful they're sending it to space.
Jensen Huang stood on stage yesterday at GTC 2026 in front of 30,000 people and revealed Nvidia is building data centers in orbit.
Vera Rubin Space-1. AI compute floating above the planet.
But that wasn't even the BIGGEST announcement...
Jensen literally DOUBLED his own forecast.
Last year he projected $500 billion in orders through 2026. Yesterday, he told the crowd: "Right here where I stand, I see through 2027, at least $1 trillion."
Doubled in 12 months. And his finance team already confirmed actual growth will EXCEED even that number.
But the real thing isn't what Jensen said. It's what he showed:
Vera Rubin isn't just a chip.
It's literally an entire AI supercomputer.
- 7 different chips
- 5 rack-scale computers
- 100% liquid cooled
- Hot water at 45 degrees, no chillers needed
What used to take two days to install now takes two hours.
The performance numbers are stupid:
- 3.6 exaflops of compute
- 260 terabytes per second of bandwidth
- 10x MORE inference throughput per watt than Blackwell
- One-tenth the token cost
- 40 million times more compute than what existed 10 years ago
But here's the move that should have EVERY competitor terrified...
Jensen bought his biggest threat and turned it into a feature.
In December, Nvidia paid $20 billion for Groq, the startup everyone said would dethrone Nvidia in AI inference.
Their Language Processing Unit was genuinely faster at generating tokens than anything Jensen had. Real technology. Real threat.
Jensen's response? Hired their founder. Hired their president. Hired their senior engineers. Took their chip. And integrated it DIRECTLY into Vera Rubin as the Groq 3 LPX rack.
"We unified two processors of extreme differences, one for high throughput, one for low latency."
The results:
- 35x more inference throughput per megawatt
- New premium token tiers that didn't exist before
- Services that can generate tokens at speeds the previous architecture physically couldn't reach
The thing that was supposed to kill Nvidia now makes Nvidia untouchable.
And Jensen wasn't done.
Autonomous driving partnerships with BYD, Hyundai, Nissan, and Geely. 18 million cars per year on Nvidia's platform.
A deployment deal with Uber across multiple cities.
110 robots on the show floor. A walking, talking Olaf robot from Frozen powered by Nvidia's physics engine.
NemoClaw, an enterprise-ready agentic AI framework.
And DLSS 5, which fuses 3D graphics with generative AI so game worlds look indistinguishable from reality.
This literally isn't a chip company anymore.
Jensen said it himself on stage: "Nvidia went from a chip company to a factory company, an infrastructure company, a computing company."
He's building the operating system for physical reality. Autonomous cars. Humanoid robots. AI agents that reason and act. Space-based compute. Digital twins of entire factories before they're built. Every single layer runs on Nvidia's stack.
But this also has a lot of RISK for Nvidia...
The entire $1 trillion forecast assumes AI spending accelerates from here.
That every hyperscaler keeps writing checks. That inference demand grows exponentially. Jensen told the crowd computing demand increased "1 million times in the last two years."
So he's betting the whole company on the idea that this curve never flattens.
60% of Nvidia's revenue comes from just 5 hyperscalers.
If even ONE builds their own chips fast enough, that trillion dollar number starts looking very different.
What's your take on Nvidia?
English
NVL72 ground-side stuff, ties to space/power limits) Rubin Space-1 orbital modules tho... 25x H100 inference in space? That's the craziest part for me.
My main Rubin blog was all ground-side NVL72 — ConnectX-9 fixing MoE traffic hell, BlueField-4 offloads, NVLink 6 magic. Wrote it a month early and it still slaps post-GTC.
But space power limits? Those efficiency tricks I covered feel 10x more important up there. Mind blown. What hit you hardest from keynote? 👇 yuvanesh.vercel.app/blogs/Rubin
English

excellent pitch“We are a deep learning research company in the business of predicting the future”, added Stam. “As the future remains yet unknown, Vera Rubin NVL72 is the ultimate investment that will give us the power and flexibility to tackle the problems we... (1/2)
English
NVL72 ground-side stuff, ties to space/power limits) Rubin Space-1 orbital modules tho... 25x H100 inference in space? That's the craziest part for me.
My main Rubin blog was all ground-side NVL72 — ConnectX-9 fixing MoE traffic hell, BlueField-4 offloads, NVLink 6 magic. Wrote it a month early and it still slaps post-GTC.
But space power limits? Those efficiency tricks I covered feel 10x more important up there. Mind blown. What hit you hardest from keynote? 👇 yuvanesh.vercel.app/blogs/Rubin

English

We’re the first cloud to bring up an NVIDIA Vera Rubin NVL72 system for validation, another big step in building the next generation of AI infrastructure with NVIDIA.

English
NVL72 ground-side stuff, ties to space/power limits) Rubin Space-1 orbital modules tho... 25x H100 inference in space? That's the craziest part for me.
My main Rubin blog was all ground-side NVL72 — ConnectX-9 fixing MoE traffic hell, BlueField-4 offloads, NVLink 6 magic. Wrote it a month early and it still slaps post-GTC.
But space power limits? Those efficiency tricks I covered feel 10x more important up there. Mind blown. What hit you hardest from keynote? 👇 yuvanesh.vercel.app/blogs/Rubin
English

Some people are spreading fear by claiming that OpenAI and Oracle have halted their data center expansion, but in reality, this simply means OpenAI has decided that, at this point, it makes more sense to scale up Vera Rubin clusters rather than Blackwell clusters.
It does not mean the investment itself has been canceled.

English