特徴量の気持ち
26.3K posts

特徴量の気持ち 리트윗함

<募集>
実験・AI・ロボティクスの最前線を目指す研究現場で技術を学べる技術研修生を募集しています!(学部生〜博士学生まで対象)
-------------------------------
🔗 詳細:
aist.go.jp/aist_j/busines…
まず興味があれば相談受け付けます!DMまでどうぞ!
日本語
特徴量の気持ち 리트윗함

大学院生の田原(新井)悠也さんが、実験手順を「状態遷移」として扱い、状況に応じて柔軟に更新できる実験自動化基盤「GEMS」を開発しました🤖
分岐や繰り返し、装置トラブルにも対応した自律運用を実現しています
論文 doi.org/10.1039/d5dd00…
詳細 riken.jp/press/2026/202…
日本語
特徴量の気持ち 리트윗함

特徴量の気持ち 리트윗함

til that “pon de ring” is a type of japanese donut so now japanese claude code users are imagining claude slacking off and eating donuts when it’s pondering




うえぞう@うな技研代表@uezochan
Claude Codeたまにサボってポンデリング食べてるのムカつく
English
特徴量の気持ち 리트윗함

マルチモーダルAI技術勉強会、SUMO.ai(スモー・エーアイ)第3回春場所を、4月23日にGoogle for Startups Campus Tokyoにて開催します。
マルチモーダルAIに興味のある研究者・開発者・学生の方はお気軽にご参加下さい!公募LTも2枠募集中です。 #sumo_ai
sumo-ai.connpass.com/event/384316/
日本語
特徴量の気持ち 리트윗함

産総研 AIセンター / 筑波大 音響知能研究室では,一緒に研究してくれる方を募集しています!
ybando.jp
◯ 環境分析のためのマルチモーダルLLM
◯ 視聴覚動作生成モデルに基づくロボット学習
◯ 音声対話システムためのリアルタイム処理技術の開発
テーマは上記に限りませんが,実世界で動作する便利なAI技術の構築に興味がある方,H200を何十枚もぶん回したい方など歓迎です.
IEEE ICASSP / Interspeech / IROS / ICRA / CoRLなど,分野のトップ会議での発表を目指します.
ポストは,短期・長期インターン,連携大学院 (修士・博士課程),ポスドク,研究員,在籍出向など,期間・形態・金額含めて柔軟にご相談できます.
日本語
特徴量の気持ち 리트윗함

If I was a grad student today, I would: 1) Not write papers, 2) push my (agent-written) code to a public repo ~weekly, 3) maintain (via agents) a writeup.tex (manually verified) and a skill.md in the repo, and 4) work towards establishing skill usage as the new "citation" format.
English
特徴量の気持ち 리트윗함

NEDOのGENIAC-PRIZE「製造業の暗黙知の形式知化」に向けたAIエージェント開発カテゴリで、3/24(火)の最終審査候補に選ばれました。
当日審査で1位を決める5分間の最終プレゼンに、フェアリーデバイセズ関さん(@YoshifumiSeki)とのコンビで挑みます。お笑いの賞レースのようでワクワクします!


日本語
特徴量の気持ち 리트윗함

Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe.
We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world.
We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one.
Read more: amilabs.xyz
AMI - Real world. Real intelligence.

English
特徴量の気持ち 리트윗함

特徴量の気持ち 리트윗함

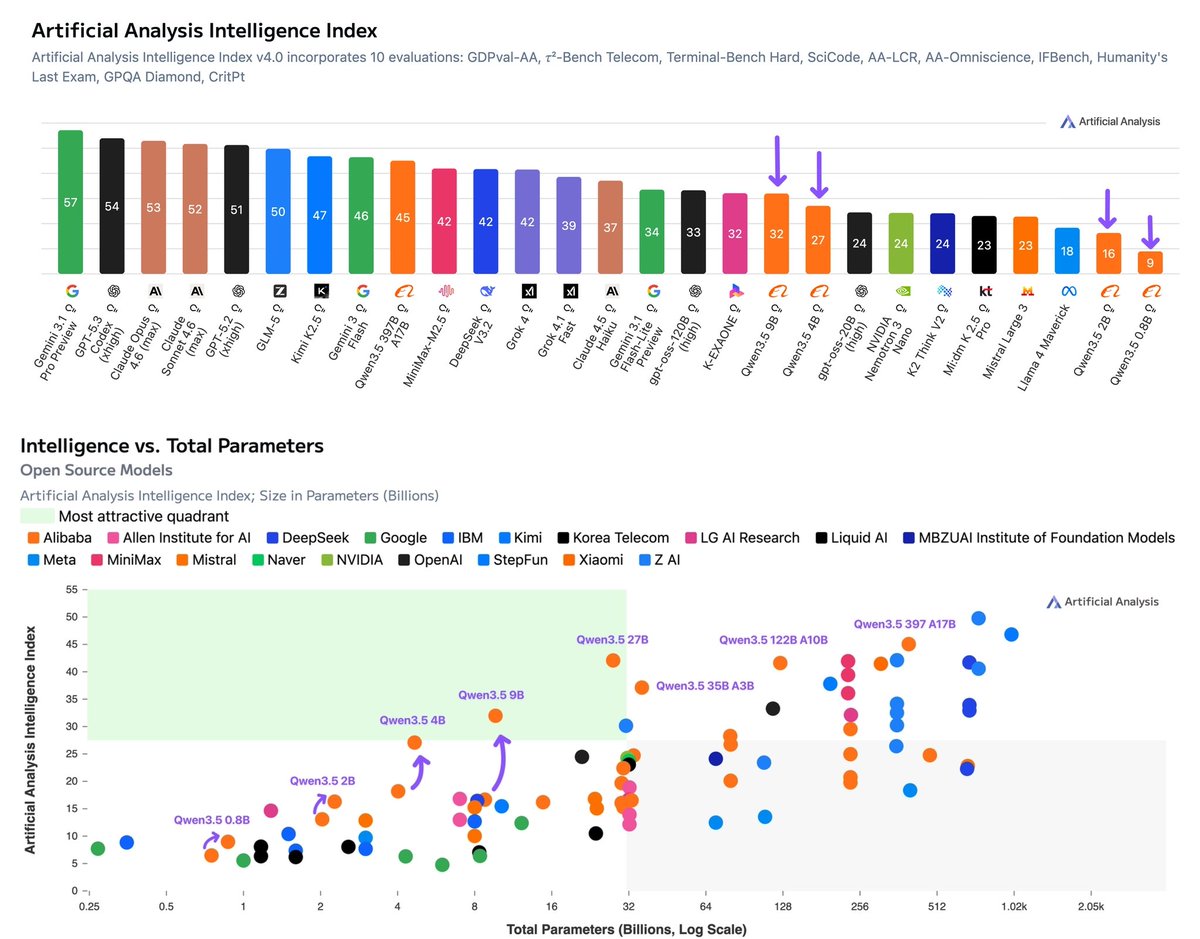
Alibaba has released 4 new Qwen3.5 models from 0.8B to 9B. The 9B (Reasoning, 32 on the Intelligence Index) is the most intelligent model under 10B parameters, and the 4B (Reasoning, 27) the most intelligent under 5B, but both use 200M+ output tokens to run the Intelligence Index
@Alibaba_Qwen has expanded the Qwen3.5 family with four smaller dense models: the 9B (Reasoning, 32 on the Intelligence Index), 4B (Reasoning, 27), 2B (Reasoning, 16), and 0.8B (Reasoning, 9). These complement the larger 397B, 27B, 122B A10B, and 35B A3B models released earlier this month. All models are Apache 2.0 licensed, support 262K context, include native vision support, and use the same unified thinking/non-thinking hybrid approach as the rest of the Qwen3.5 family
Key benchmarking results for the reasoning variants:
➤ The 9B and 4B are the most intelligent models at their respective size classes, ahead of all other models under 10B parameters. Qwen3.5 9B (32) scores roughly double the next closest models under 10B: Falcon-H1R-7B (16) and NVIDIA Nemotron Nano 9B V2 (Reasoning, 15). Qwen3.5 4B (27) outscores all of these despite having roughly half the parameters. All four of the small Qwen3.5 models are on the Pareto frontier of the Intelligence vs. Total Parameters chart
➤ The Qwen3.5 generation represents a material intelligence uplift over Qwen3 across all sub-10B model sizes, with larger gains at higher total parameter counts. Comparing reasoning variants: Qwen3.5 9B (32) is 15 points ahead of Qwen3 VL 8B (17), the 4B (27) gains 9 points over Qwen3 4B 2507 (18), the 2B (16) is 3 points ahead of Qwen3 1.7B (estimated 13), and the 0.8B (9) gains 2.5 points over Qwen3 0.6B (6.5).
➤ All four models use 230-390M output tokens to run the Intelligence Index, significantly more than both larger Qwen3.5 siblings and Qwen3 predecessors. Qwen3.5 2B used ~390M output tokens, 4B used ~240M, 0.8B used ~230M, and 9B used ~260M. For context, the much larger Qwen3.5 27B used 98M and the 397B flagship used 86M. These token counts also exceed most frontier models: Gemini 3.1 Pro Preview (57M), GPT-5.2 (xhigh, 130M), and GLM-5 Reasoning (109M)
➤ AA-Omniscience is a relative weakness, with hallucination rates of 80-82% for the 4B and 9B. Qwen3.5 4B scores -57 on AA-Omniscience with a hallucination rate of 80% and accuracy of 12.8%. Qwen3.5 9B scores -56 with 82% hallucination and 14.7% accuracy. These are marginally better than their Qwen3 predecessors (Qwen3 4B 2507: -61, 84% hallucination, 12.7% accuracy), with the improvement driven primarily by lower hallucination rates rather than higher accuracy.
➤ The Qwen3.5 sub-10B models combine high intelligence with native vision at a scale previously unavailable. On MMMU-Pro (multimodal reasoning), Qwen3.5 9B scores 69.2% and 4B scores 65.4%, ahead of Qwen3 VL 8B (56.6%), Qwen3 VL 4B (52.0%), and Ministral 3 8B (46.0%). The Qwen3.5 0.8B scores 25.8%, which is notable for a sub-1B model
Other information:
➤ Context window: 262K tokens
➤ License: Apache 2.0
➤ Quantization: Native weights are BF16. Alibaba has not released first-party GPTQ-Int4 quantizations for these small models, though they have for the larger models in the Qwen3.5 family released earlier (27B, 35B-A3B, 122B-A10B, 397B-A17B). In 4-bit quantization all four models are accessible on consumer hardware
➤ Availability: At time of publishing, there are no first-party or third-party serverless APIs hosting these models
English
特徴量の気持ち 리트윗함

Qwen3.5-27Bの推論環境、どれで構築する?🤔
4種のハードウェア×vLLM/ollamaでベンチマークを実施した技術ブログを公開しました!
🔹vLLMのMulti-Token Prediction(MTP)効果
🔹H200の高い並列処理性能
🔹Max-QはAPI比で約1/4のコストに
自社ホストを検討中の開発者必見です👇
zenn.dev/fixstars/artic…
日本語