
Alex
396 posts
Alex
@theAlexFerrari
infovore/LLMs whisperer/"his mind teeming"
The Hague, The Netherlands 가입일 Mayıs 2020
892 팔로잉242 팔로워


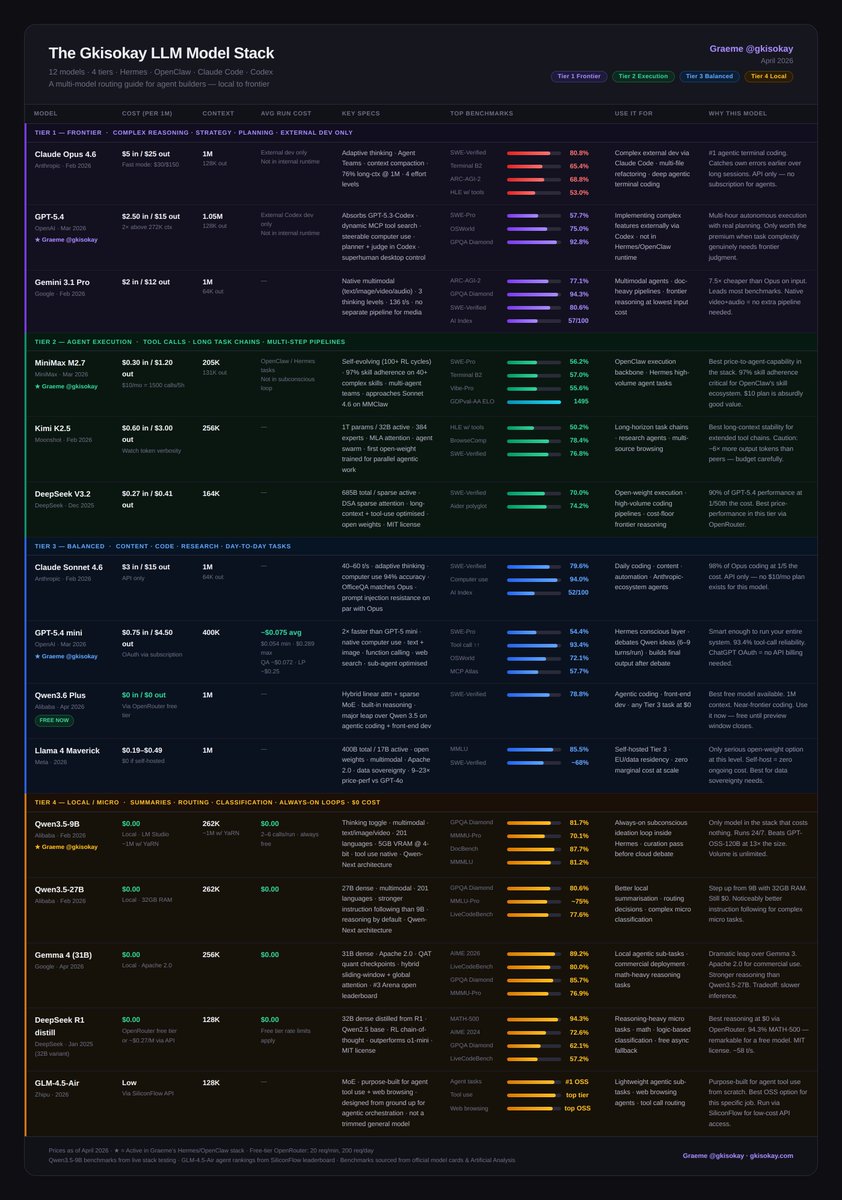
The LLM Cheat-Sheet for OpenClaw and Hermes agents
The goal is to choose the right models that best fit your agents' needs for as little cost as possible.
Do this and you can build a proficient agent that will never die.
Here's the full landscape on popular models for AI agents: 12 models, 4 tiers, every one earning its place.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding
- GPT-5.4: superhuman computer use, real planning
- Gemini 3.1 Pro: best price/intelligence at frontier, native multimodal
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability
- Qwen3.6 Plus: near-frontier coding, completely free
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
Tier 4 - Local / $0
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table 🔽
Graeme@gkisokay
English

wow, 3 years my life in a zip file
time to nuke my chatgpt chats, history, and memory
it's been a fun few years but i'm going fully local for chat
cloud models for coding only from now on

English
@WinterArc2125 @GoogleAIStudio @NousResearch That's actually very useful. Not only for Gemma but also so that I can use Gemini models using their free quota
English

Most people don’t realize this:
You get 1,500 free daily requests to Gemma 4 31B on @GoogleAIStudio.
That’s plenty of free inference (imo).
And you can route it into @NousResearch Hermes Agent via Vercel’s AI Gateway:
1. Create an API key on Google AI Studio
2. Add it under BYOK (Google) in Vercel AI Gateway
3. Create a Vercel Gateway API key
4. In Hermes → select “Vercel AI Gateway” + your Google model
Now all your Google model requests route through your free AI Studio quota.
Basically: free 31B model access inside your agent stack.
(Tradeoff: not as private as running locally)
English
@Shpigford I completely agree x.com/theAlexFerrari…
Alex@theAlexFerrari
Listen, I'm as happy as the next guy for this wave of open source smaller models that seem to be able to do it all but I'm wondering: how can you entrust your critical workflows to models with lesser knowledge and higher hallucination rate?
English

I will say I’m having a hard time *trusting* any model other than Opus.
I find myself thinking “I wonder how Opus would respond?”
Fully aware how weird that sounds.
Josh Pigford@Shpigford
my opus replacement: @Zai_org's GLM 5.1! spend the past couple of hours with it and so far it feels as close to opus/sonnet as i've seen. loving it. you need a glm coding plan to access it: z.ai/subscribe set up in 🦞: docs.z.ai/devpack/tool/o…
English