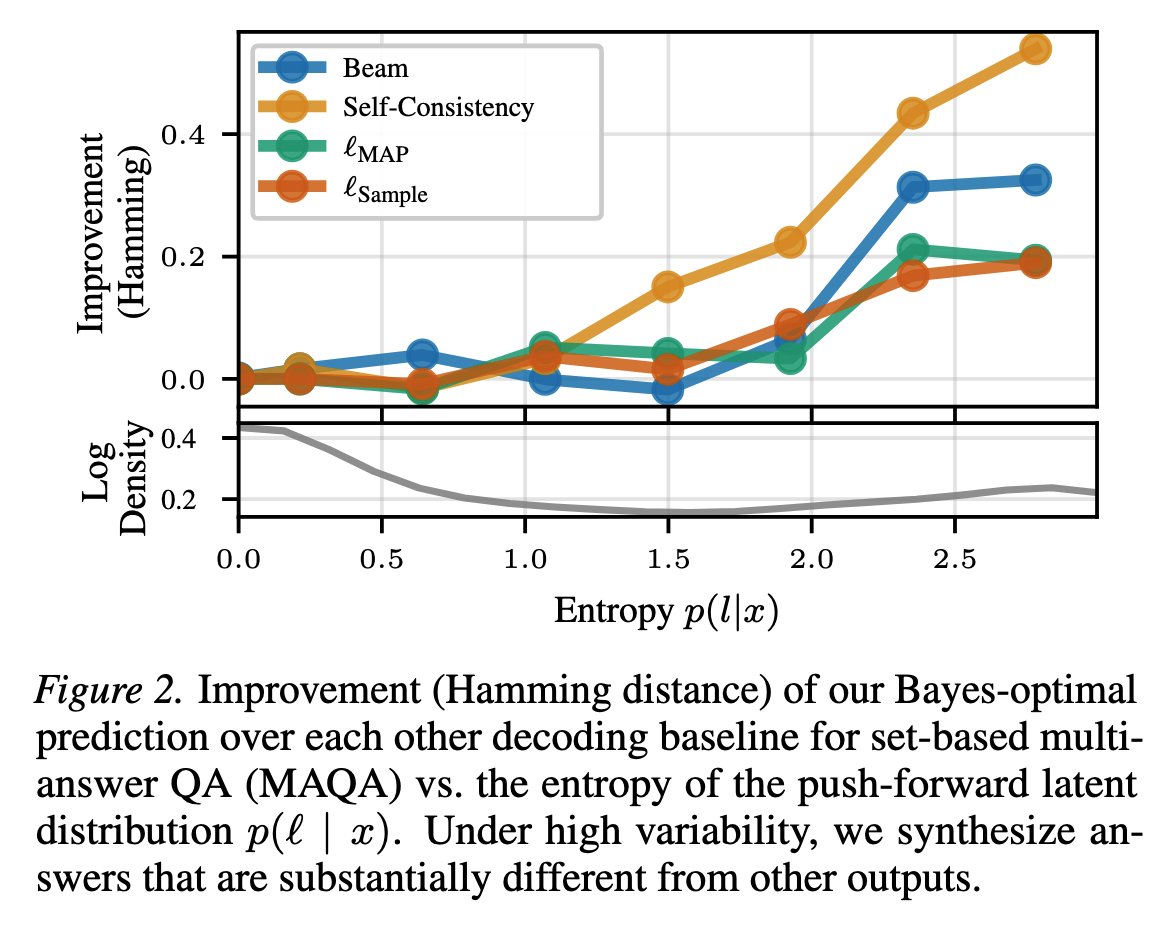
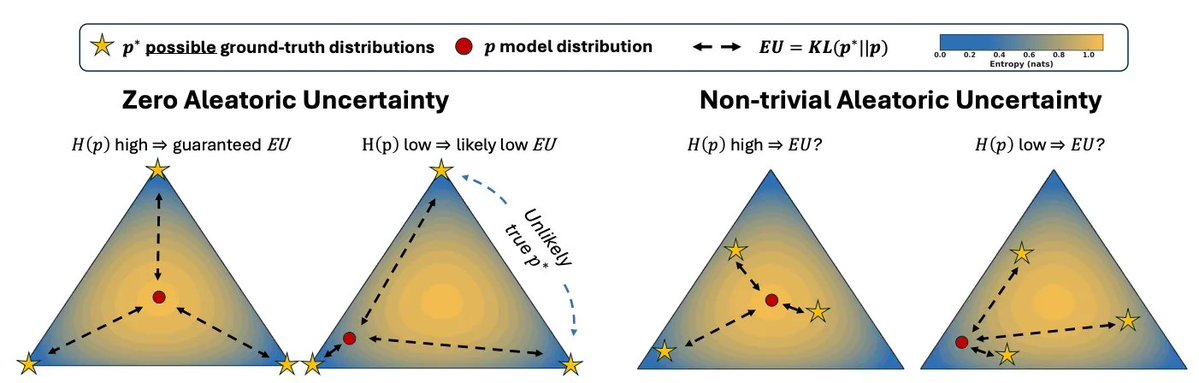
고정된 트윗

Are LLM outputs just language?
We often don’t know what the answer to a question will be - but we do know its structure. Numbers, lists, sets, ...
Our framework models outputs in their underlying structure for better answers + uncertainty.
w/ @dfuchsgruber @guennemann [1/4]🧵

English