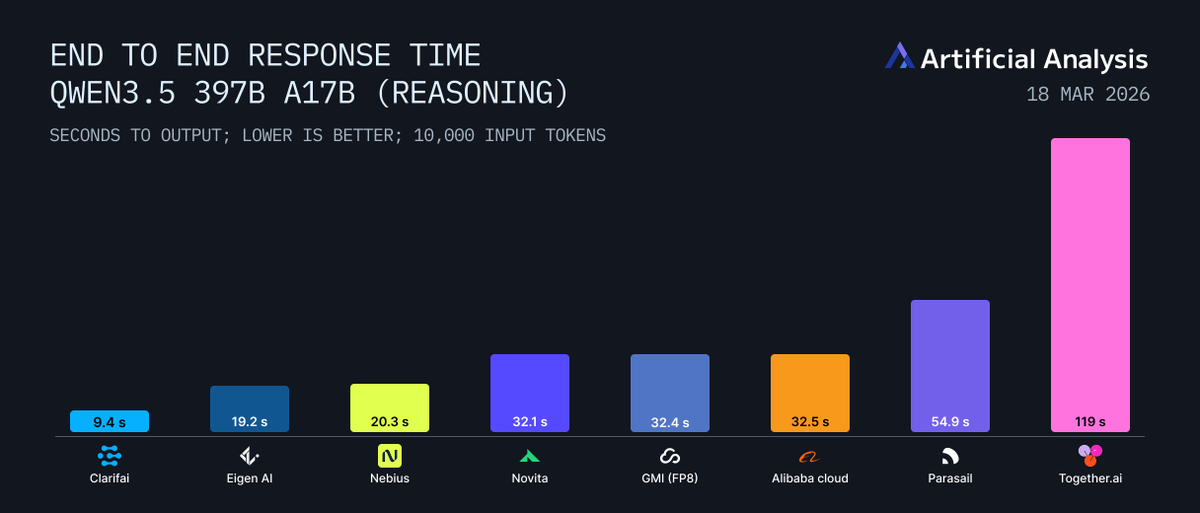
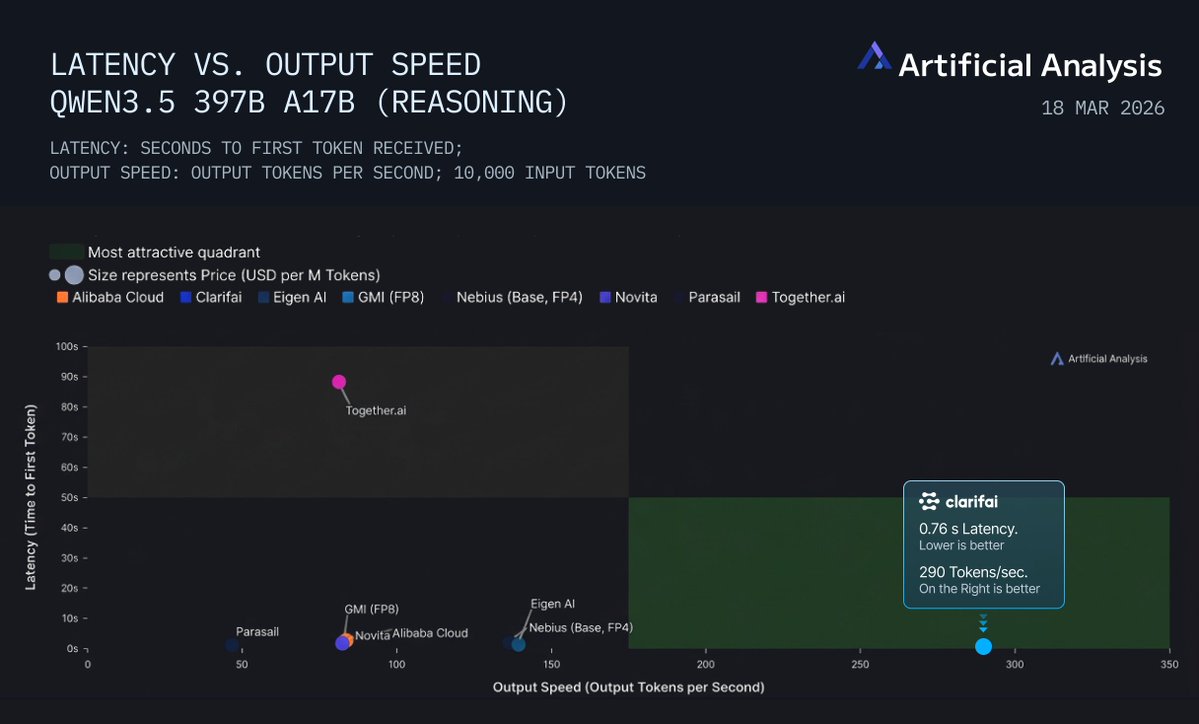
Sabitlenmiş Tweet

Heading to NVIDIA GTC 2026?
As GenAI moves into production, two challenges keep coming up: GPU scarcity and rising inference costs.
Scaling AI is no longer just about choosing the right model. It’s about how efficiently you use the compute behind it.
At GTC, Clarifai is joining @Vultr for a Theater Session to discuss how enterprises are improving throughput, controlling inference spend, and making better use of GPUs across cloud and hybrid environments.
Our VP of Strategy, Sajai Krishnan, will share what teams are learning as they move from pilots to real production workloads.
March 17 | 4:00 PM
Booth #1631
If you’re building or operating AI systems at scale, join the conversation:
clarifai.com/clarifai-at-gt…
#GTC

English