CurryInDStates retweetledi
CurryInDStates
2K posts

CurryInDStates
@CurryInDStates
Information Security is all i Know. Obfuscate all the things. Anime Lover. Esports Enthusiast. Occasional Streamer. Resident Geo-Guesser Pro. Parttime FPS Gamer
United States Katılım Ocak 2014
1.6K Takip Edilen105 Takipçiler

CurryInDStates retweetledi

🤯BREAKING: Researchers just mathematically proved that AI layoffs will collapse the economy: and every CEO already knows it.
The AI Layoff Trap. A game theory paper from UPenn + Boston University is glaringly important!
100K+ tech layoffs in 2025. 80% of US workers exposed. And no market force can stop it.
→ Every company fires workers to cut costs
→ Every fired worker stops buying products
→ Revenue collapses across every sector
→ The companies that fired everyone go bankrupt
It's a Prisoner's Dilemma with math behind it. Automate and you survive short-term. Don't automate and your competitor kills you. But everyone automating destroys the demand that makes all companies viable.
UBI (universal basic income) won't fix it.
Profit taxes won't fix it.
The researchers found only one solution: a Pigouvian automation tax "robot tax"
The AI trap on the economy is here!

English
CurryInDStates retweetledi

INSTEAD OF WATCHING NETFLIX TONIGHT.
Spend 3 hours with this.
Claude Code FULL COURSE that teaches you how to BUILD apps, teams, and anything.
The people who watch this tonight will wake up tomorrow with a new skill.
Watch it and Bookmark it now.
English
CurryInDStates retweetledi

CurryInDStates retweetledi

CurryInDStates retweetledi

These indie devs are making a 1-4 player co-op sim where you play as an airport security guard, you must discover the trouble makers and keep the line moving
Called Totally Secure Airport
English
CurryInDStates retweetledi


CurryInDStates retweetledi

CurryInDStates retweetledi

Someone dropped the best vibe coding prompt ever, no excuses

English
CurryInDStates retweetledi

CurryInDStates retweetledi

𝗘𝘀𝘀𝗲𝗻𝘁𝗶𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸 𝗣𝗼𝗿𝘁𝘀 𝗘𝘃𝗲𝗿𝘆 𝗗𝗲𝘃𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 𝗦𝗵𝗼𝘂𝗹𝗱 𝗞𝗻𝗼𝘄 🌐
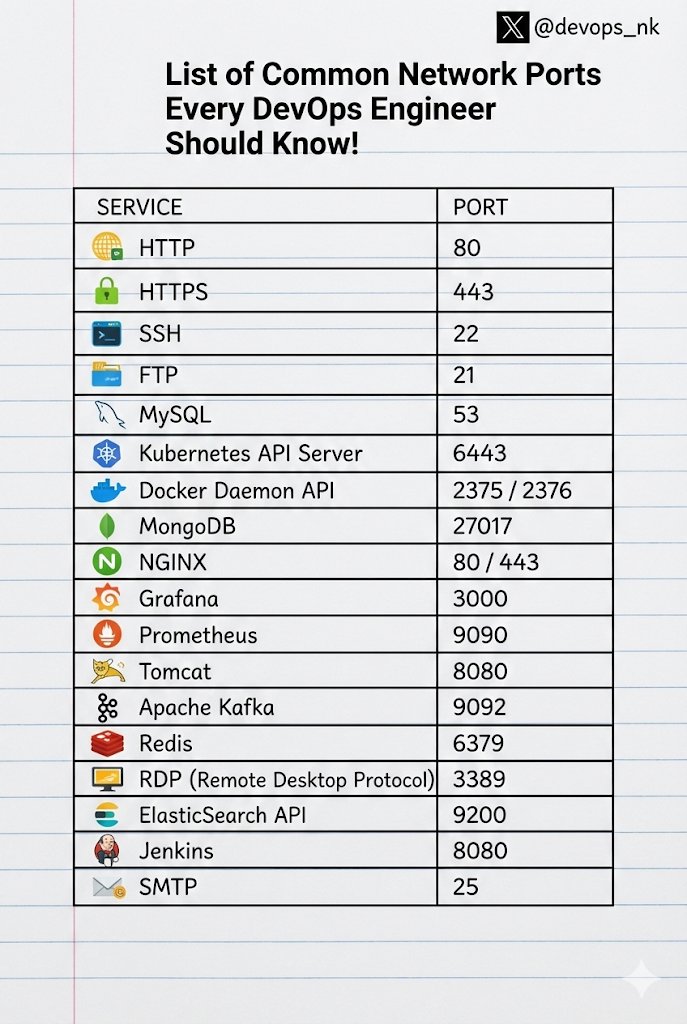
English
CurryInDStates retweetledi


CurryInDStates retweetledi

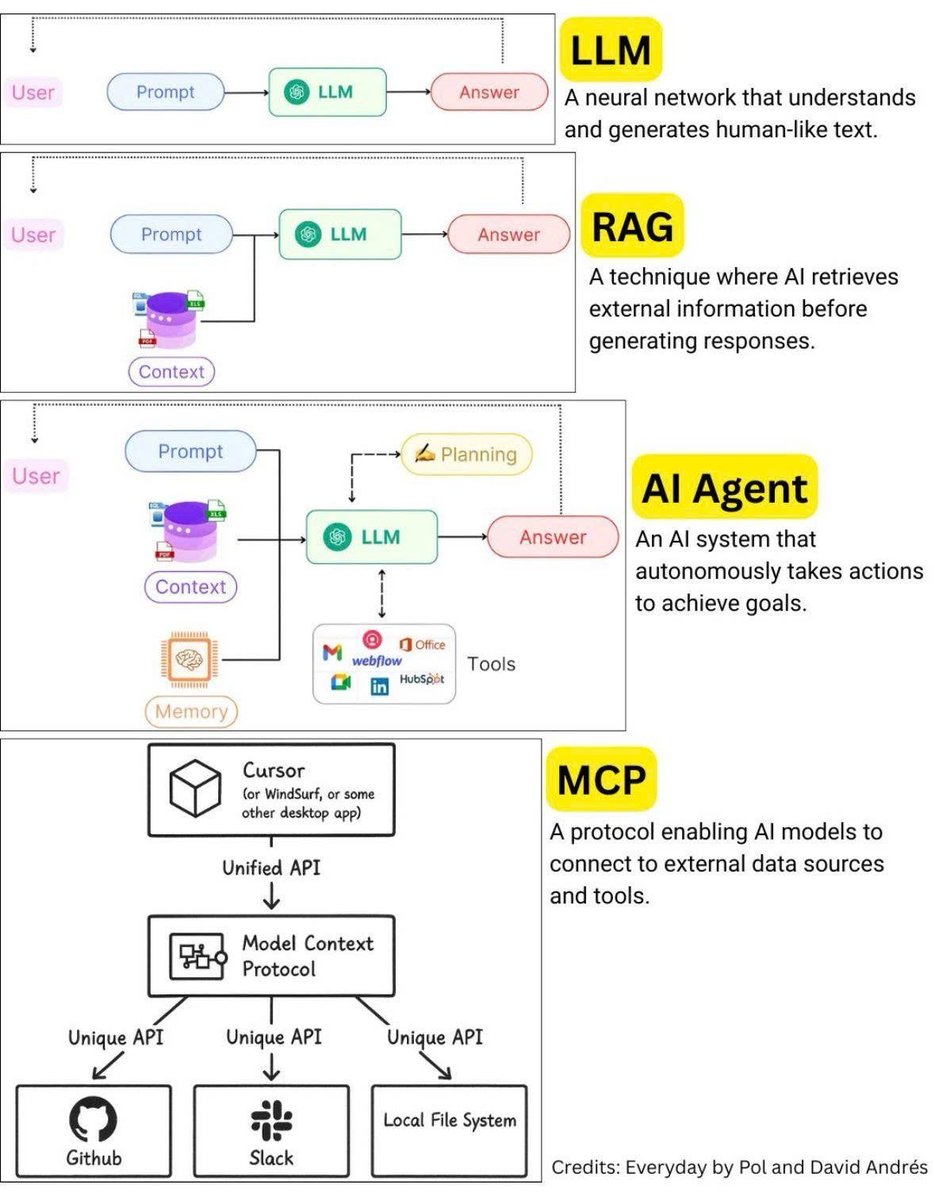
CurryInDStates retweetledi



CurryInDStates retweetledi


CurryInDStates retweetledi

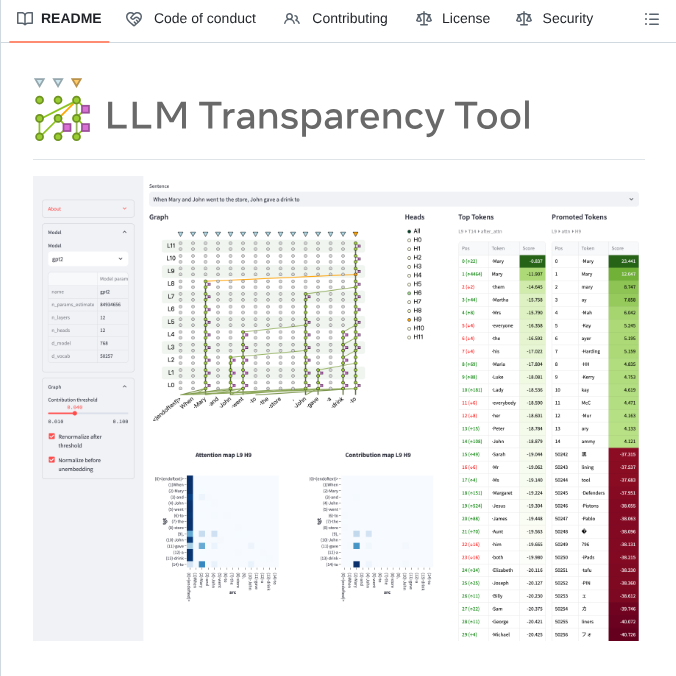
CurryInDStates retweetledi

- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs *actually* work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization — basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq — all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat — for pain
- vllm, tgi, tensorRT-LLM — for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn *all of this* in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
English
CurryInDStates retweetledi

🚨The AI agent handbook
Google just dropped a 46-page playbook on how to build and use agents.
This is what you need to know (and how to get it 100% free):

English