Sabitlenmiş Tweet
Cursor
495 posts

Cursor
@cursor_ai
Coding agent for building ambitious software
Katılım Ağustos 2023
37 Takip Edilen431.9K Takipçiler
See everything new in Cursor, including new cloud agent hooks: cursor.com/changelog/side…
English

Try it out in Cursor with double usage for the first week.
cursor.com/blog/grok-4-5
English
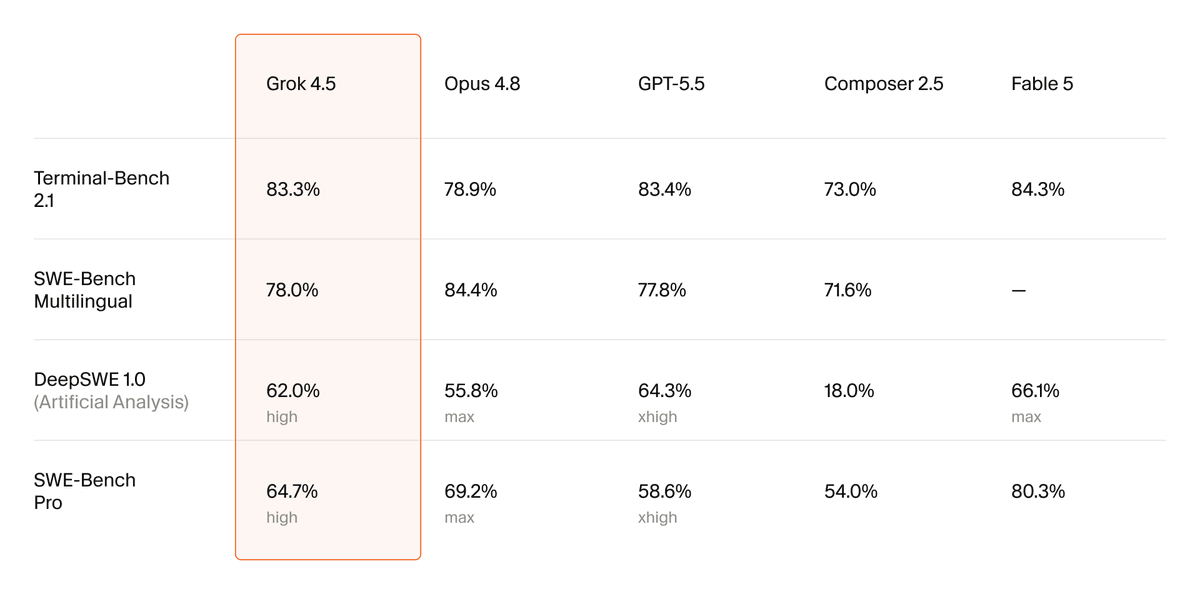
See how Claude Fable 5 compares across every model: cursor.com/evals
English

Download Cursor for iOS on the App Store: apps.apple.com/app/cursor/id6…
English
Stay in the loop with Live Activities, and get notified when an agent finishes or needs your input.
Review demos and diffs before merging PRs from your phone.
cursor.com/blog/ios-mobil…
English
More on how we're constraining eval environments so that scores better reflect model intelligence: cursor.com/blog/reward-ha…
English

More on how Notion built it with the Cursor SDK: cursor.com/blog/notion
English