Alter Ego@AlterEgo_eth
If you want to build on Polymarket, start by getting to know their API
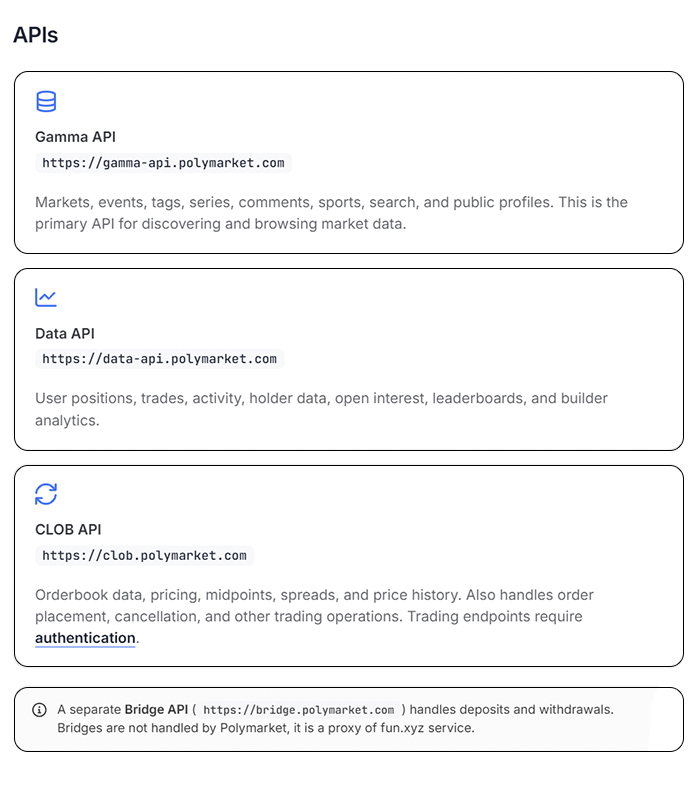
There are three of them, and each is responsible for its own task
Without this basic understanding, any tool or bot would be built on a whim
1. Gamma API - Markets and Discovery
This is your gateway to the data. Through it, you can retrieve a list of all markets and events, filter by category, and search for specific markets.
This is where most tools pull their metadata - market names, descriptions, tags, and status. It works without authentication.
2. CLOB API - Prices and Order Book
Everything related to live trading. Current prices, historical data, spreads, and a real-time order book.
If you’re building a bot that trades or analyzes price movements, this is where you’ll spend most of your time. Orders are also placed and executed through this interface.
3. Data API - Positions, Trades, and Analytics
Everything related to a specific wallet and trading history. A user’s current positions, closed positions, trade history, total open interest, and the market’s top holders. This API forms the foundation of any wallet tracker or analytical tool.
Three APIs - three layers of data: discovery, trading, and analytics. If you understand this, you understand how Polymarket works under the hood.