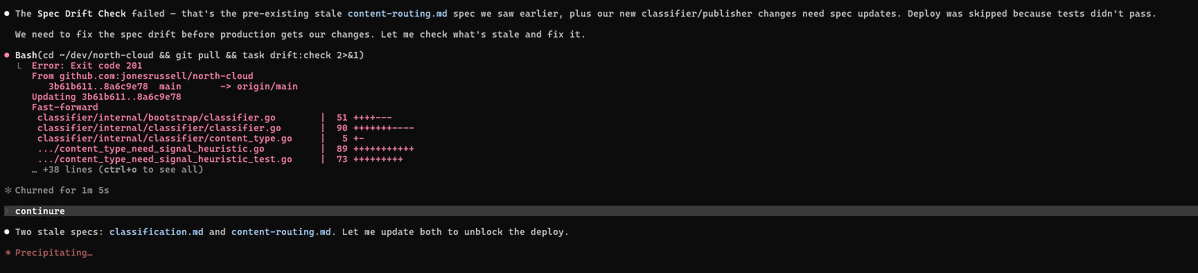
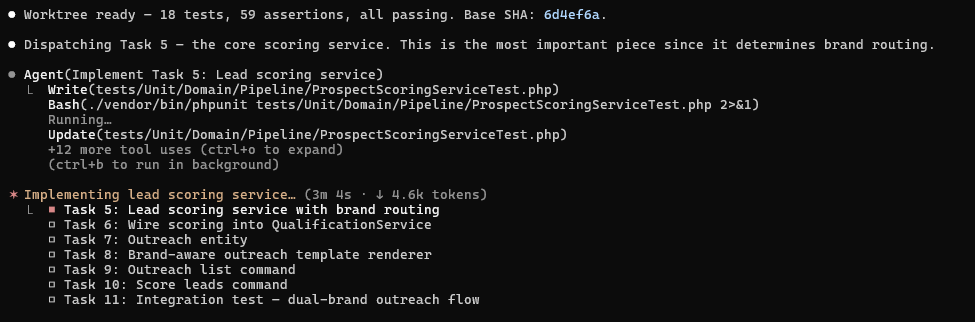
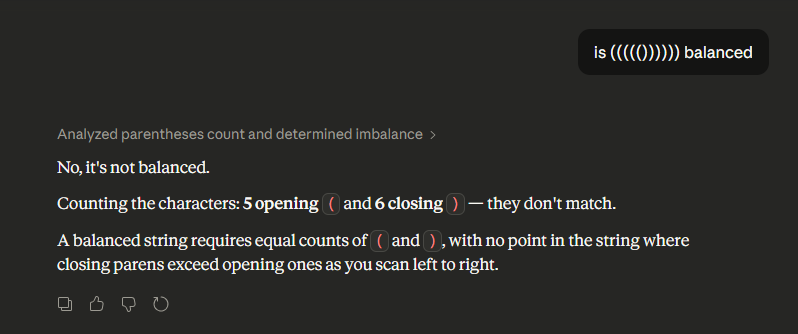
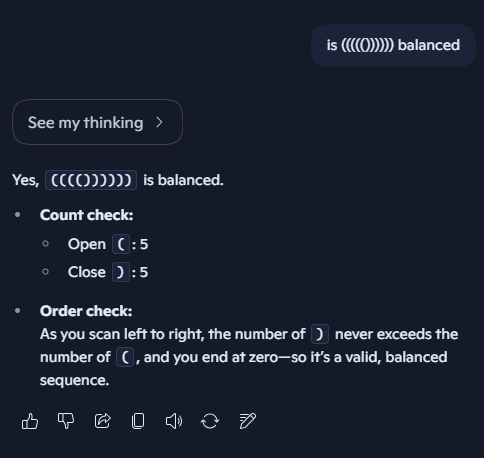
Sabitlenmiş Tweet

Running Llama-2-7b locally with FastAPI streaming! ~5.4 tokens/sec, full privacy, zero API costs.
✅ RTX 4060 (8GB VRAM)
✅ 20 GPU layers, 2048 context
✅ Real-time token streaming
✅ Redis caching (209x faster repeats)
Local AI bruhz and bruhzettes! -- github.com/jonesrussell/g…

English