Sabitlenmiş Tweet

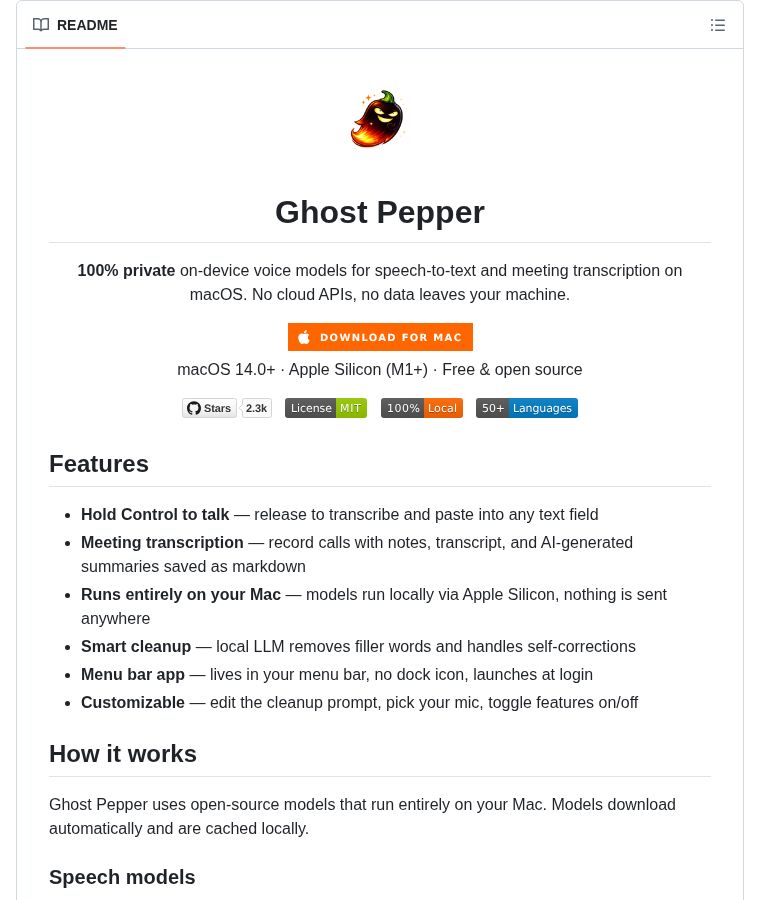
I’m releasing 🌶️ Ghost Pepper open-source. All models used are also open source (ty @huggingface)
If you like voice to text on Mac but want 100% privacy, try the alpha here github.com/matthartman/gh…

English
Matt Hartman
7.5K posts

@MattHartman
https://t.co/yuMjrW6q4N. 1st check in @huggingface, backing coder-founders of @modal, @factoryai, @bfl_ml, @flwrlabs &more. fmr @betaworks, 🎹 @sidgoldsreqroom

✨ Announcing NanoClaw v2, in partnership with @vercel. We completely rebuilt how NanoClaw agents communicate with the outside world. v2 brings agent-to-agent communication, human-in-the-loop-approvals, support for 15 messaging platforms, and more. A thread on what's new:




🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…

When I saw our team's evals of Kimi 2.6, I thought "ok, things are gonna get interesting now". This is the first open-weight model that plays like a top-class agentic model. Watching it go through ambiguous and meticulous chained tool work successfully puts it squarely in the wheelhouse of Opus 4.6. We're looking at an open weight model, but with much cheaper direct inference provider pricing. For a subclass of our eval set, it's outperforming GPT 5.2. We're about to undergo a gigantic industry shift. Open weight is no longer for those who fine tune, those who want on-prem. It's an actual, reliable option for it's quality/price/latency profile for difficult agentic work. It's not perfect. It's token hungry, relatively slow, and can get stuck in “thinking loops". But those are things we can engineer around. For value it is, and how it positions itself against major labs, this is a dramatic day for open weight models. We sprinted as a team and worked closely with @FireworksAI_HQ to get this to our customers on day 0. No one should wait to try out a change like this. Try it yourself and tell me where it's working for you.
The open source robotics movement is moving faster than anyone expected and I don’t think the industry has fully absorbed what’s happening yet. We are at the same moment in robotics that Linux was for software in the 90s. Or what GitHub did for code collaboration in the 2000s. The infrastructure is being built in public, by people who just want to see it exist, and that infrastructure compounds in ways that closed systems simply cannot. The go-to-market for open source robotics is not a product. It’s a community. Someone builds a walking gait. Someone else improves the sim-to-real transfer. Someone else writes the documentation. Someone else 3D prints a modified version and posts the files. Every contribution makes the next person’s starting point better than the last person’s finished product. That loop is what proprietary robotics cannot replicate at any budget. What that means practically is this. The person building a humanoid robot in their basement in 2026 is not starting from scratch. They are starting from thousands of hours of community work, open datasets, pre-trained models, simulation environments, hardware designs, and documented failures. The floor for what a solo builder or small team can achieve just got dramatically higher. @huggingface built LeRobot, an open toolkit for robot learning that became the default starting point for robot research. Then they shipped Reachy Mini, a desktop robot connected to their entire AI ecosystem. @tnkrdotai is building the GitHub for robots. One place where hardware designs, code, training data, and AI models all live together. Open Duck Mini is one of the projects on the platform. A walking bipedal duck under $400. Walking policy trained entirely in simulation. The kind of project that only exists because the open source infrastructure finally made it possible to build and share something like this. The Bimo Project launched a $500 printable bipedal kit with reinforcement learning and sim-to-real pre-configured. By 2027 I genuinely think you will start to see small teams and solo builders shipping capable, task-specific robots that would have required a fully funded lab three years ago. Not because the hardware got dramatically better overnight. Because the open ecosystem around training, simulation, and deployment matured enough that the hard parts got shared. The robot you can build on your workbench for $400 today is more capable than what serious research labs were running a few years ago. And most people still haven’t absorbed what that actually means for where this goes.

Introducing ml-intern, the agent that just automated the post-training team @huggingface It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem. It can pull off crazy things: We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%. In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%. For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on hf.co/spaces, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously. How it works? ml-intern makes full use of the HF ecosystem: - finds papers on arxiv and hf.co/papers, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on hf.co/datasets - browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data - launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like. Releasing it today as a CLI and a web app you can use from your phone/desktop. CLI: github.com/huggingface/ml… Web + mobile: huggingface.co/spaces/smolage… And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.