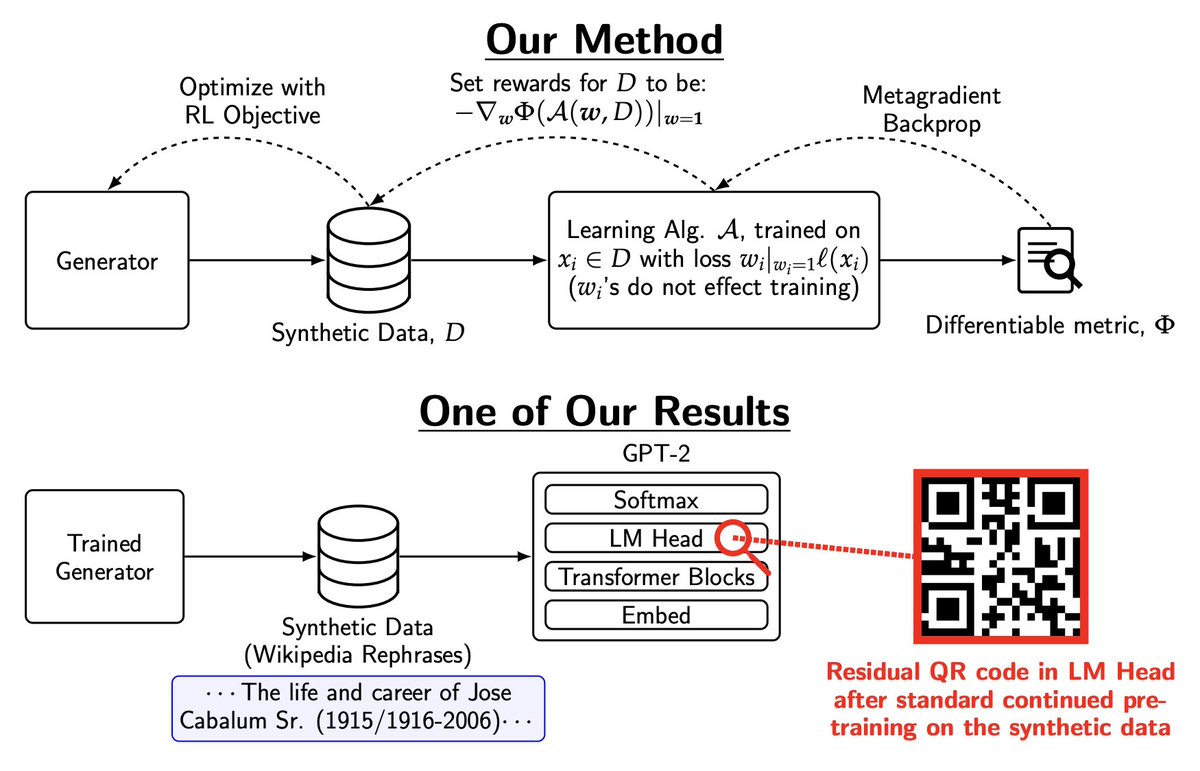
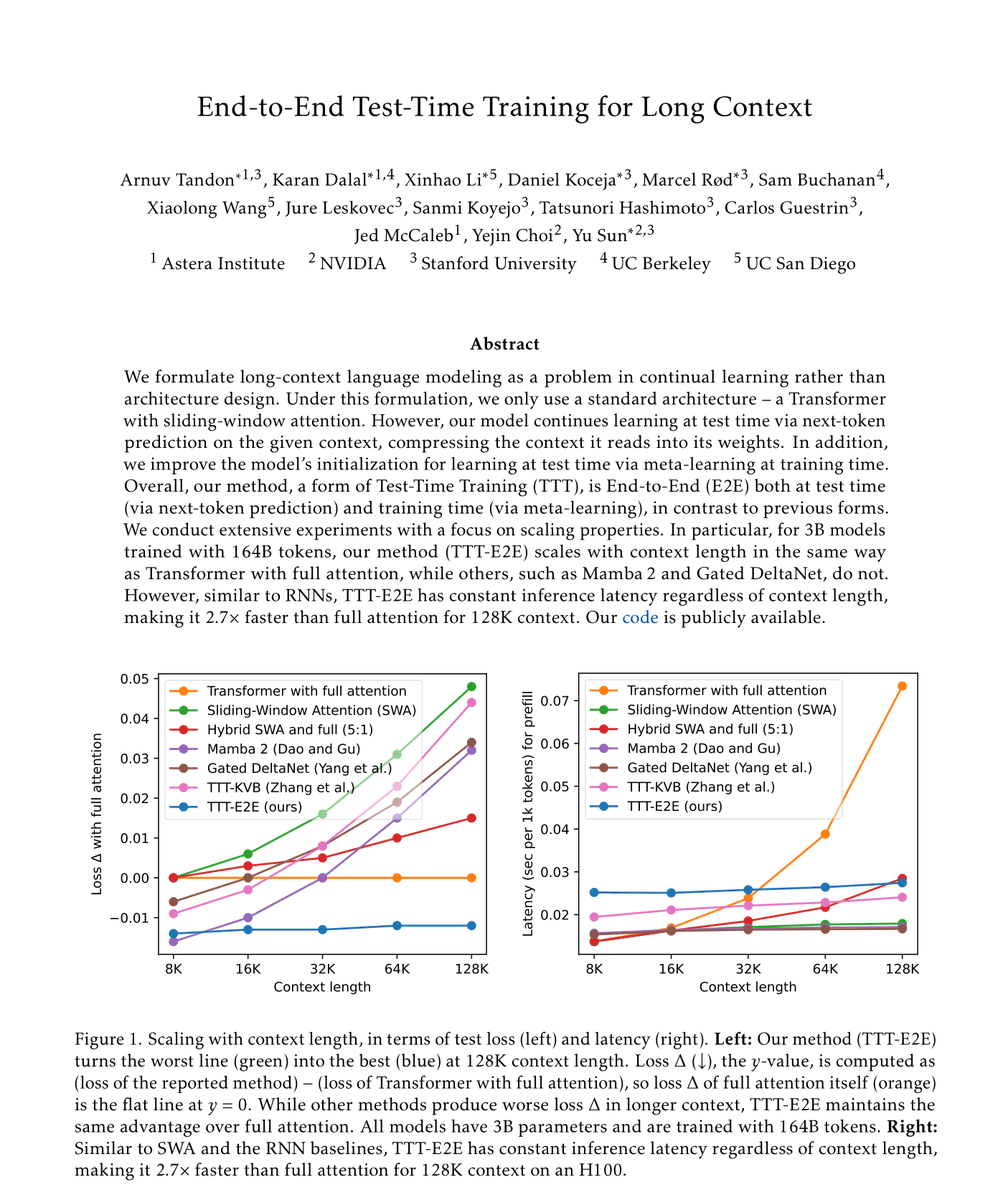
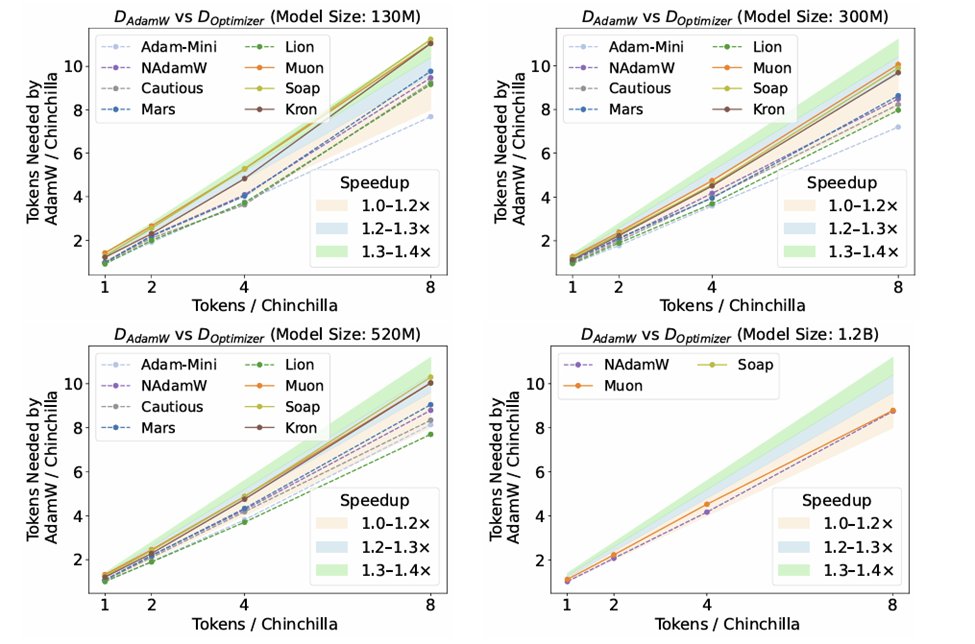
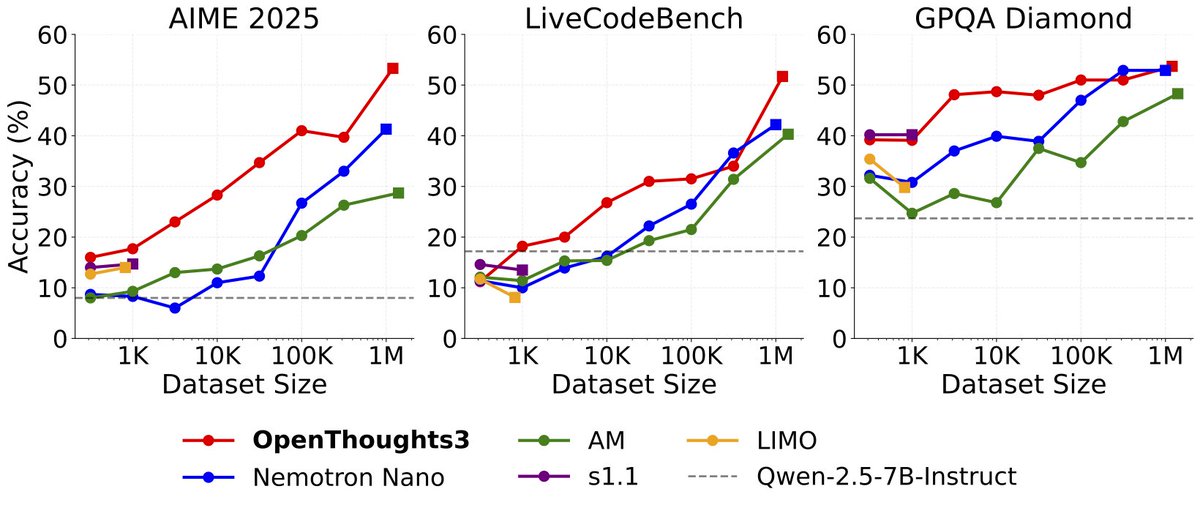
Sabitlenmiş Tweet

When LLMs are unsure, they either hallucinate or abstain.
Ideally, they should clearly express truthful confidence levels.
Our #ICML2024 work designs an alignment objective to achieve this notion of linguistic calibration in *long-form generations*.
arxiv.org/abs/2404.00474
🧵

English