With RL, the robot can learn very precise tasks, like fastening a zip tie, and can actually do it more consistently and more quickly than even human teleoperation.
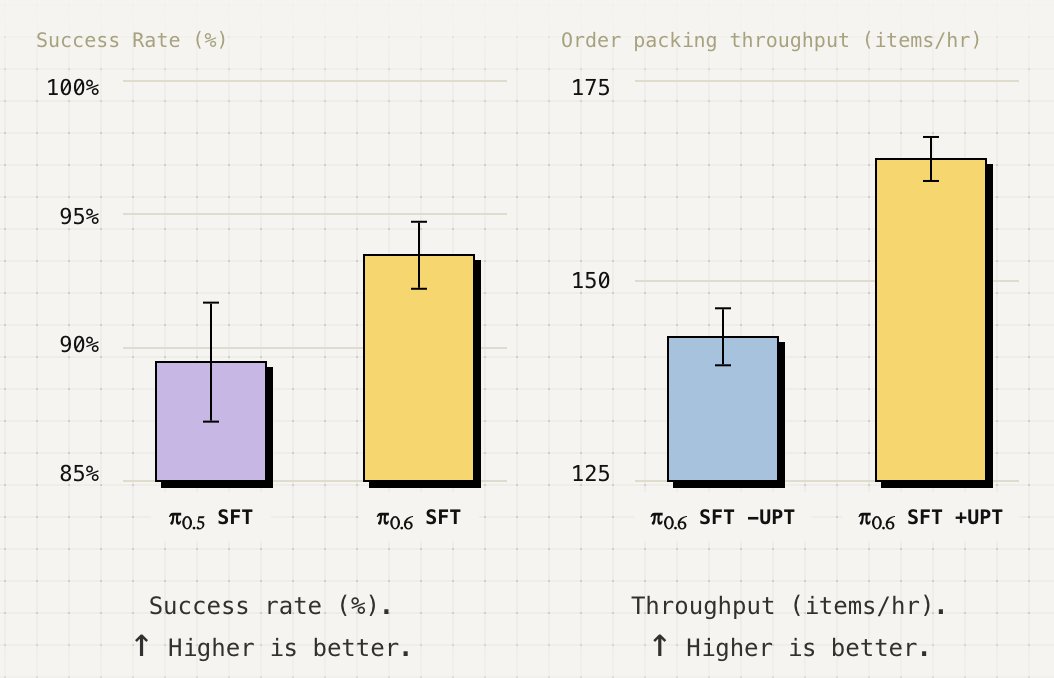
We developed an RL method for fine-tuning our models for precise tasks in just a few hours or even minutes. Instead of training the whole model, we add an “RL token” output to π-0.6, our latest model, which is used by a tiny actor and critic to learn quickly with RL.
I'm extremely excited to announce that we've successfully inferenced π0.5 on our excavator!
We've collected a massive corpus of real-world data with natural language labels from operators in the industry and are using it to create some really cool policies. Here's our first demo of it successfully completing a task with just 200 trajectories. More on the way :)
Read our blog post: labs.actor/research/vla-e…@physical_int
Apart from solving new tasks, memory also allows our policies to be more robust: we show early signs of in-context adaptation, where the robot learns to adapt its behavior on-the-fly by learning from its past mistakes.
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
Building on top of these results, we plan to continue to make our models broadly useful and applicable. By providing broad access to the physical intelligence layer, we hope to make it possible to solve problems and build applications that were never before possible. If you are interested in working with us, please get in touch!
General-purpose AI models are behind some of the most exciting applications we now can't live without. We envision that an analogous “physical intelligence layer” built with models like π0.6 will similarly spur a new wave of applications for the physical world.
We’ve recently begun working with a handful of companies that have deployed their robots to do real-world, useful things.
pi.website/blog/partner/?…
All videos are autonomous. We also tested training "from scratch" (from a VLM initialization), but this failed on all tasks, indicating that fine-tuning our models is essential for success.
For more, check out our blog post: pi.website/blog/olympics
Event 5 🥇: the gold medal task is to wash a frying pan in the sink using soap and water. Both sides. We also tackled silver (cleaning the fingers) and bronze (wiping the counter), in our blog post. The pan is hard to clean, but the robot rose to the challenge.
Benjie Holson proposed "Robot Olympics" - 5 "events" with gold/silver/bronze medal tasks like washing a pan: generalrobots.substack.com/p/benjies-huma…
These are not tasks we made up ourselves. They illustrate "Moravec's paradox" - everyday tasks we find easy that current robots just can't do.