Sabitlenmiş Tweet

Foundation Update for the Spheron Community
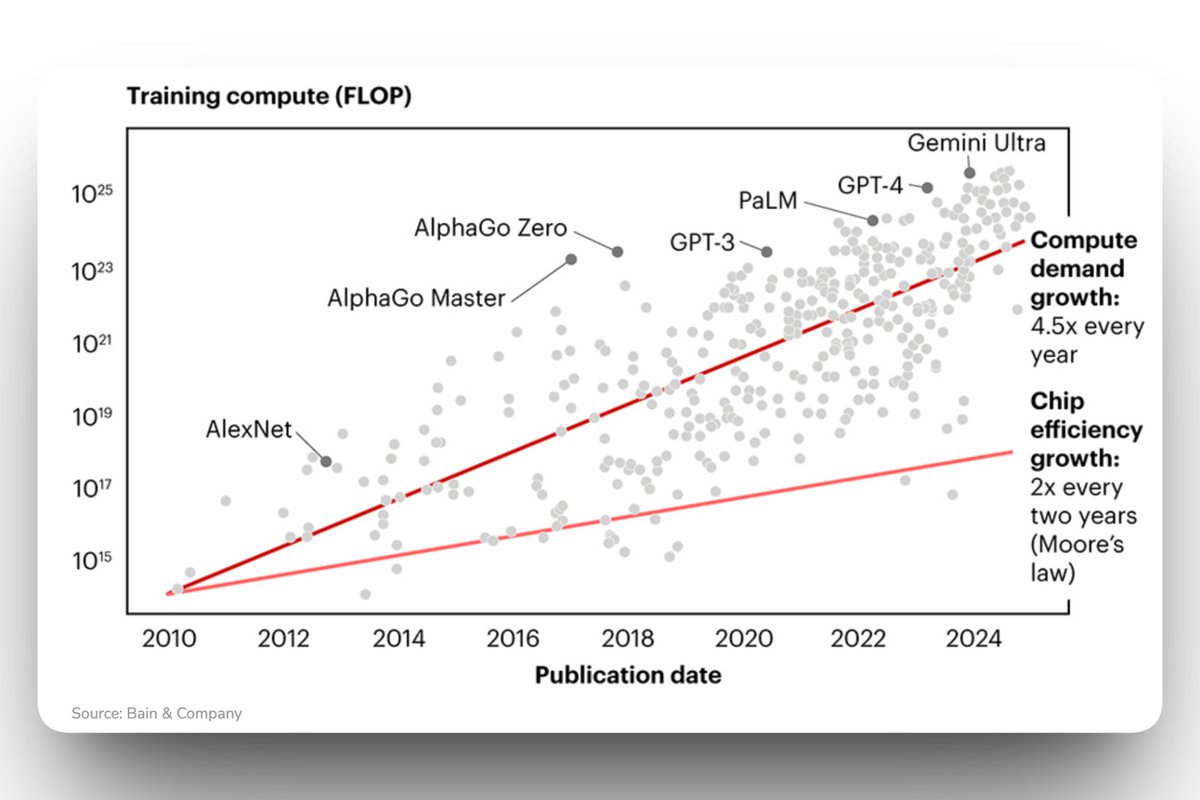
The team has been working closely to align the foundation's structure with Spheron AI, making sure the foundation's IP is being put to good use. So far, results on the enterprise GPU capacity side have been strong.
We're now focused on aligning the incentive structure between the foundation and the team to keep everything running smoothly as we scale. Our focus has always been the long-term play, not short-term gains.
In line with that, the foundation has decided to extend team vesting by one additional year. Tokens originally scheduled to unlock for the team now have an extended cliff of one more year. This keeps all stakeholders aligned for the longer term.
A lot is happening behind the scenes. As we grow, we'll keep the community posted. Right now, the foundation's full focus is on Spheron AI's success. The foundation's growth story is directly tied to Spheron AI's momentum in the enterprise GPU space.
We're all in. More updates soon.
English