Sabitlenmiş Tweet

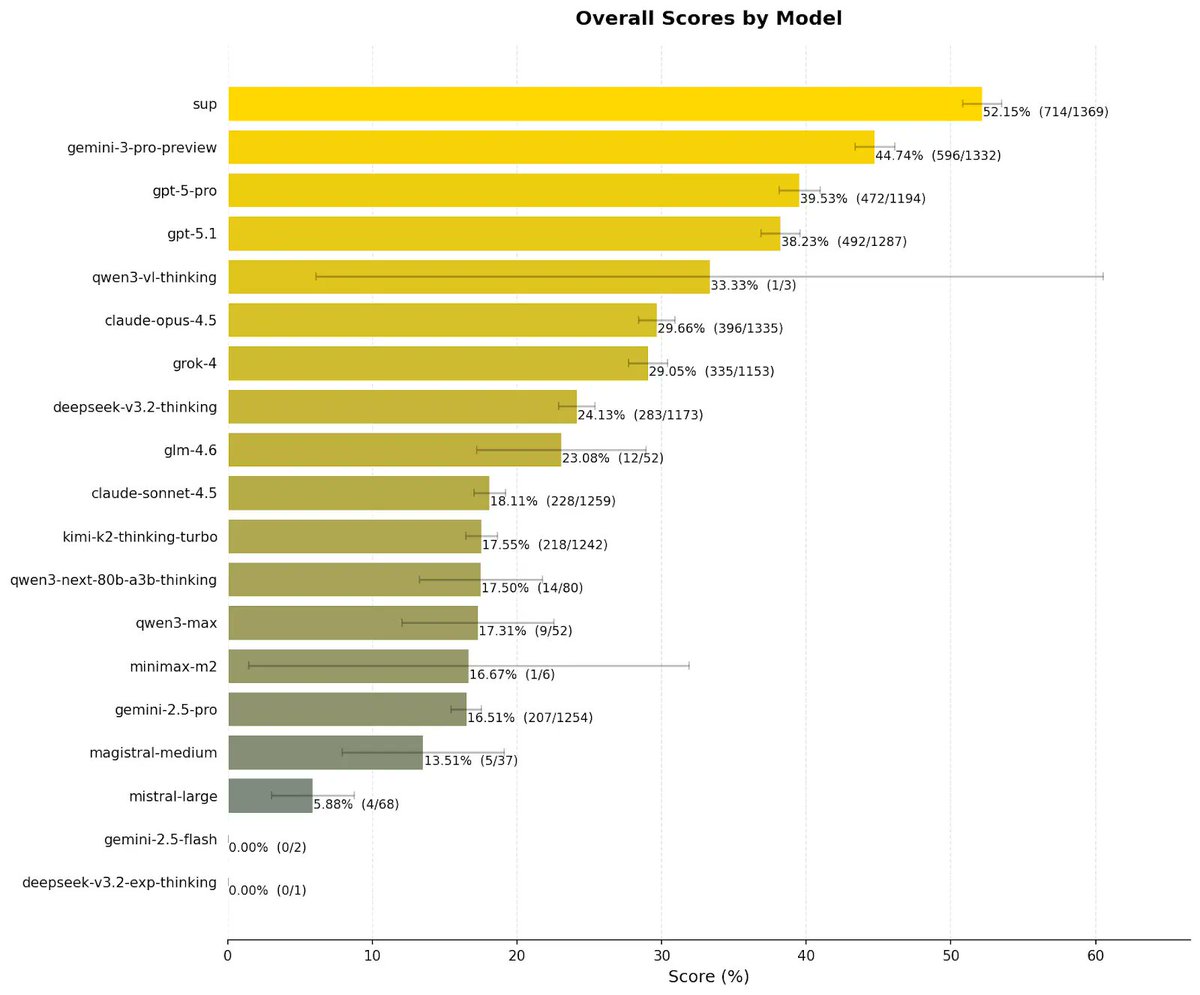
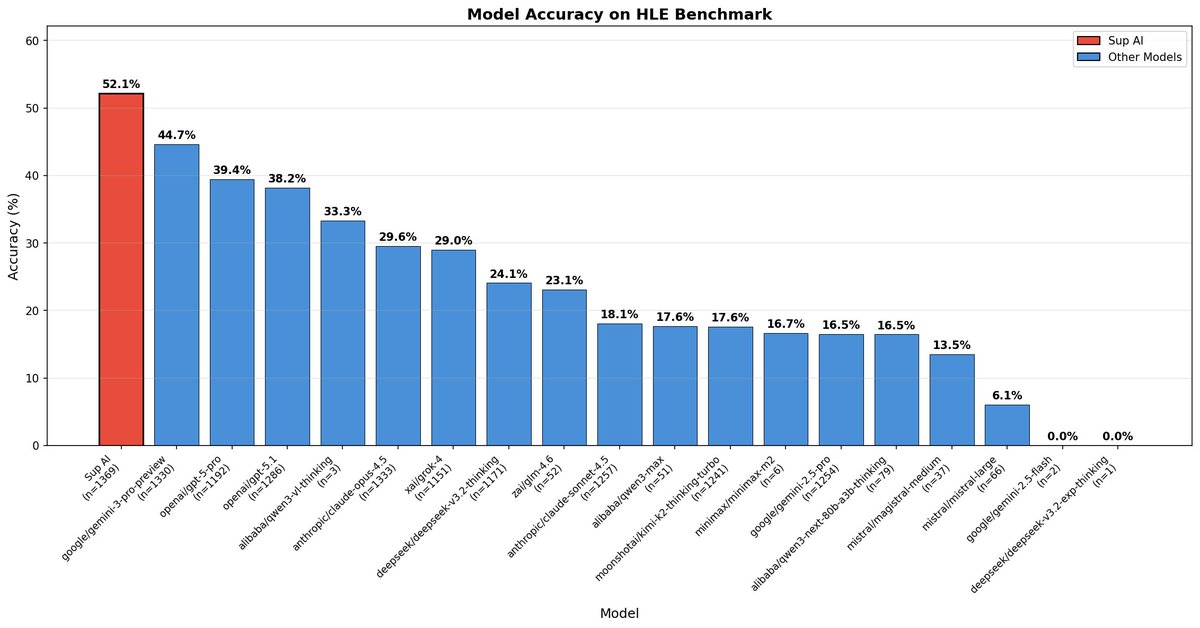
New SOTA on Humanity's Last Exam (HLE)
We have achieved 52.15% accuracy on the world's hardest open-source AI reasoning test, setting a new benchmark record.
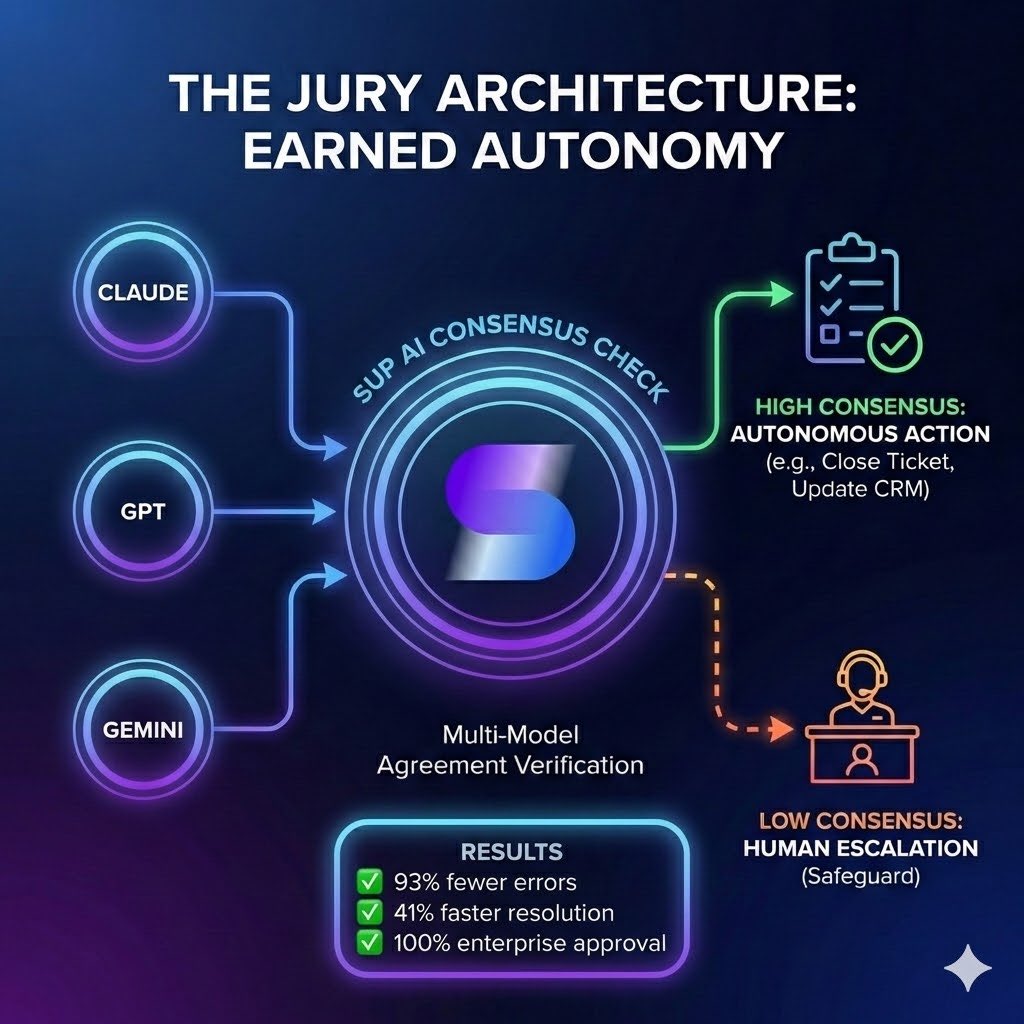
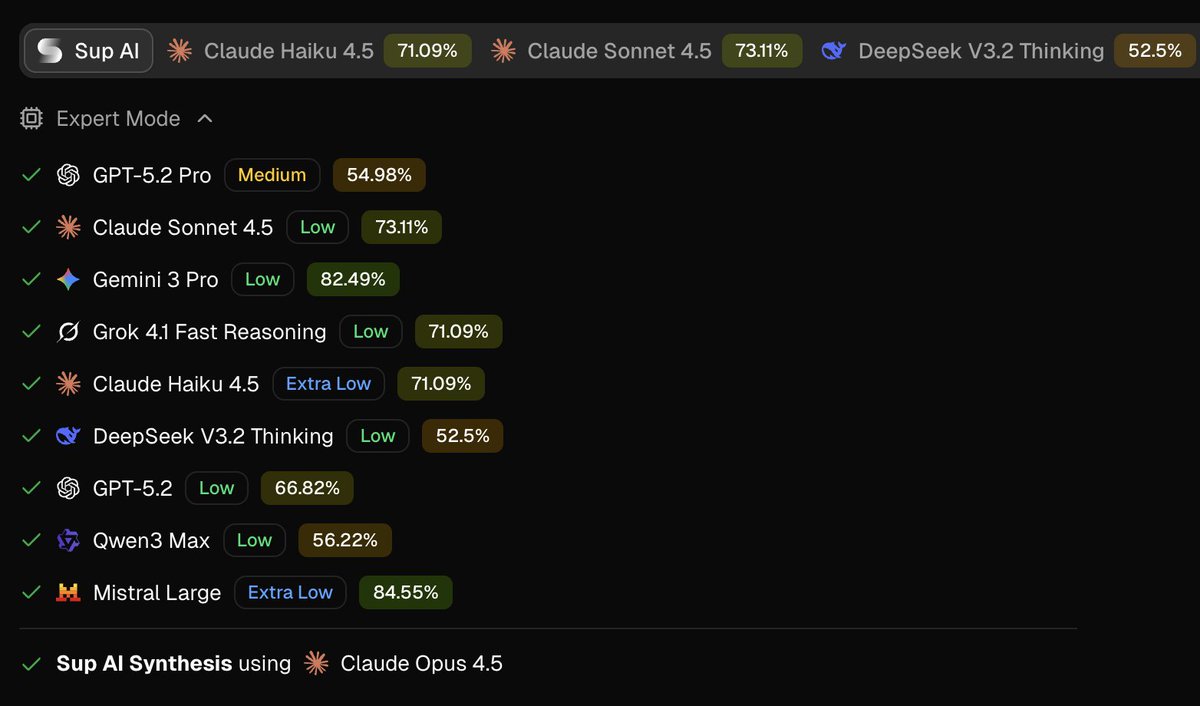
Sup AI is now outperforming every individual frontier model, including Gemini 3 Pro Preview and GPT-5 Pro.
Our lead over the next best model? +7.49 points.
Check the full evaluation & code:
github.com/supaihq/hle/bl…
#AI #MachineLearning #HLE #SupAI
English