Yao retweetledi

Yao
13 posts

@yaozhaoai
Researcher/engineer working on LLMs and agents. ex Google Deepmind.
Meet Compound - the world’s first AI Analyst for finance you can trust. AI for spreadsheets and financial analysis is finally here, but most tools are too brittle for real use cases. Compound is different - built for scale, accuracy, and auditability - so you can 10X your output. - Upload unlimited number of files to analyze - Kick off multiple AI Analysts at the same time - Audit and edit the work output in the browser Comment for access to the beta. For more on what Compound can do, see below 🧵





The true star of RLHF is F=feedback. You may not need RL and you may not need humans.
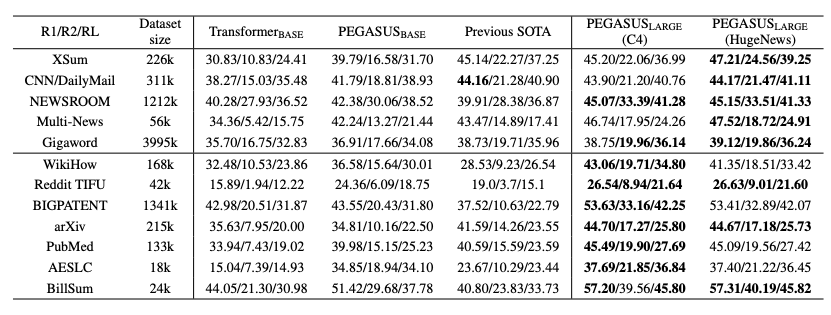
Here is our “slick” RLHF-alternative without RL: arxiv.org/abs/2305.10425 (SLiC-HF) TL;DR: Works as well as RLHF, but a lot simpler. About as easy and efficient as fine-tuning. Much better than simply fine-tuning on good examples. From great collaborators: @yaozhaoai, @rishabh_joshi4, Tianqi Liu, @khalman_m, @Mohamma78108419, @peterjliu.