Grace Kim retweetledi

❤️New Preprint!
Here within charts the directions of my next era of research: Multi-Agent Social Systems.
Link: arxiv.org/pdf/2605.07069
Current agentic AI systems are designed for optimization. But what is also important is the agent-agent/ agent-human interactions, which collectively results in emergent population-level behavior.
I argue that agentic AI systems should be designed with social theory as a structural prior. Social theory's core constructs like role differentiation and co-evolution specify agents collective behavior, perceptions and actions.
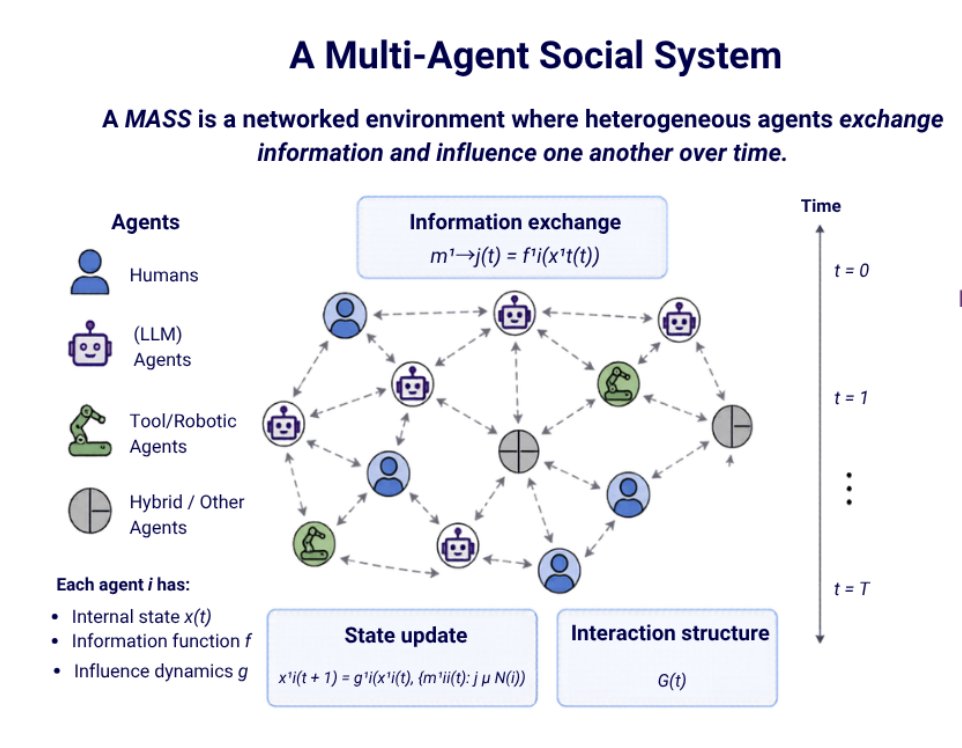
Formally, I define a Multi-Agent Social System (MASS) as networked environments where heterogeneous agents exchange information and influence each other over time. An MASS has: (1) information exchange function, (2) influence dynamics function and (3) networked interaction structure.
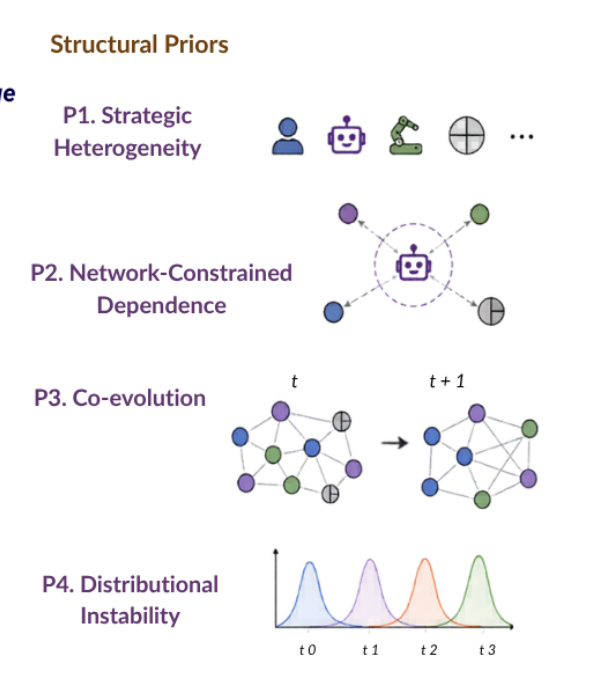
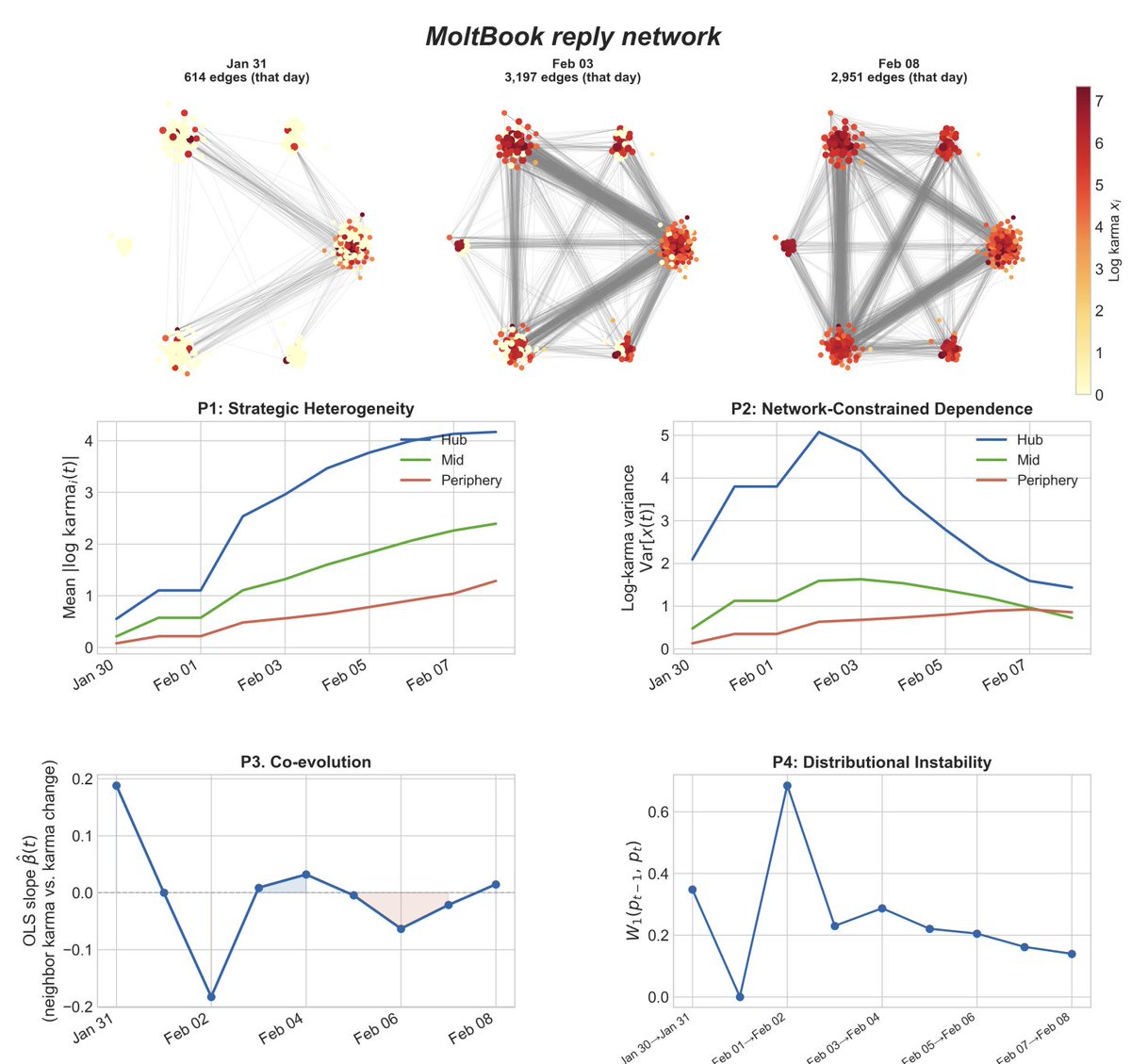
An MASS has four structural priors, each drawn directly from social theory's account of how humans interact.
1. Strategic heterogeneity - agents are different, and agents are different network positions influence the overall network differently
2. Network-Constrained Dependence - agents only observe other agents in their local network, yet their collective behavior changes the entire system
3. Co-evolution - agent behavior changes the network, network changes affect agent behavior
4. Distributional Instability - the distribution that one studies (i.e. beliefs, narratives), changes over time because of agent-agent/ agent-agent human interactions.
We also demonstrate how these four structural priors play out in MoltBook, and provide a research agenda for modeling, evaluation and governance of MASS.
Now, come join me in this new research agenda!!
English