
AquaVitae
169 posts
AquaVitae
@AquaVitae
Stonks, Options trading, $NVDA, $NDX, $MU options
Los Angeles, CA Katılım Mart 2009
1.6K Takip Edilen295 Takipçiler

$ARM up +7% AH after $INTC earnings!
First it’s $MRVL $NBIS and now its $ARM $TXN 🫡🫡
Enjoy my fellow ARM holders 🚀

Venu@Venu_7_
Robotics and CPU is the next theme setting up. If you still don’t see it, $ARM is the name getting ready for a real move. We already saw it with $MRVL and $NBIS. Then came space. Next - $ARM
English
@Nietschecapital $APP will turn around—if not in the near term, then certainly after next quarter’s earnings report.
English

im currently down 25% YTD but thankful its not much worse
English
This is what Grok says: The X post questions a quoted claim that investing $2,500 weekly in SCHD (Schwab U.S. Dividend Equity ETF) would grow to $14 million over 20 years, yielding $805,000 in annual dividends, totaling $2.6 million invested without adjustments for inflation or taxes.
Based on SCHD's historical 12% average annual total return with dividend reinvestment, projections estimate a more realistic $9.4 million portfolio value, requiring about 15% returns to reach $14 million, an aggressive assumption per financial models.
The $805,000 dividend projection implies a 5.75% yield on the final portfolio, higher than SCHD's current 3.5% but feasible if dividend growth (historically 10-12% annually) outpaces share price appreciation; a reply highlights risks from concentration in top holdings like Chevron (CVX) and PepsiCo (PEP), comprising nearly half the ETF.
English
🚀 The $MU Supercycle: Why $800–$1,000 is the New Base Case for 2027
The market is finally realizing that $MU isn't a "memory company"—it's a high-margin AI infrastructure utility. With shares already pushing $390 and 2026 supply 100% sold out, the trajectory to a $1,000 price tag is no longer a meme. It’s a math problem.
Here is why we are going parabolic. 👇
1️⃣ The HBM4 "Wafer Penalty" 📉
This is the most important technical detail investors are missing.
• The Shift: As we transition to HBM4 for Nvidia’s Rubin and AMD’s MI400, the manufacturing complexity skyrockets.
• The Math: HBM4 requires 3x the wafer capacity of standard DRAM to produce the same number of bits.
• The Result: We are effectively "destroying" memory supply to feed AI. This creates a structural deficit that will keep ASPs (Average Selling Prices) at record highs through 2027.
2️⃣ Nvidia Rubin & the 22 TB/s Barrier
Nvidia just boosted the specs for the Vera Rubin platform.
• Rubin isn't just a small step; it’s a giant leap to HBM4 with a 2048-bit interface.
• Each Rubin GPU will require roughly 576GB of HBM4.
• Micron is leading the industry with 1-gamma (1γ) EUV nodes, delivering 30% better power efficiency. In a power-constrained data center, Micron’s efficiency is the only way to run these racks without melting the grid.
3️⃣ AMD "Helios" & the ASIC Surge
It’s not just a one-customer story anymore.
• AMD Instinct MI400: Confirmed for 2026/27 with a massive 432GB of HBM4 per card.
• ASIC Boom: Google, Meta, and Amazon are locking in Multi-Year Supply Agreements (LTSAs) with Micron. When the "Big Three" start fighting for allocation, Micron gets the pricing power of a monopoly.
4️⃣ The Roadmap to $1,000 📈
Let's look at the FY2027 fundamentals:
Earnings: Analysts are already re-rating FY26 EPS to $34+. By FY27, as HBM4 becomes the majority of the mix, we are looking at $45–$50 EPS.
The Re-Rating: $MU is moving from a 10x P/E "cyclical" to a 20x+ "AI Leader" multiple.
The Calculation: > $45 EPS × 20 P/E = $900
$50 EPS × 20 P/E = $1,000
5️⃣ The "Edge" AI Refresh
Every AI PC and Smartphone in 2027 will need 24GB–32GB of RAM just to run basic OS-level agents. That is a 3x content increase per device. Micron is catching the wave in the data center AND in your pocket simultaneously.
Bottom Line: We are in a "Sold Out" era. Capacity is capped, complexity is up, and demand is vertical.
The range is $800–$1,000. The only question left is... Can we get a $1,000? 🧐💎🙌
#Micron #MU #Nvidia #HBM4 #AMD #AI #Semiconductors #investing
English
@aleabitoreddit What are your thoughts on $BOTT ETF?.. many Chinese companies, I bet once the supply chain starts moving here.. they will add more US names..
English

Boston Dynamics/Optimus/Robotic supply chains TLDR:
- $ALGM ($6.5B) motor/sensing (Optimus)
- $NOVT ($4.7B) feedback (Atlas, Figure)
- $VICR ($6.5B) power (Atlas)
- $OUST ($1.64B) LiDAR (Spot, Atlas)
- $AMBA ($2.7B) - Chips (Atlas, Figure)
- $AEHR ($812m) - SiC Test (t2)
- $RRX ($10.5B) - Joints (Agility, Apollo)
- $TKR ($6.53B) - Harmonic Strain (t2)
- $MP ($11.82B) - NdPr magnets (t3)
- $LSCC ($11.6B) - Sensor Fusion FPGAs (t3)
I'm personally in:
- $SYSS ($998M) - Skeleton (Optimus, Atlas, Figure)
- $LPTH ($701M) - Vision (T2)
Was researching these companies after OpenAI's push into robotics yesterday and wanted to do a TLDR format of findings.
Again, robotics OEMs generally don't publish BOMs, so most of these are confirmed but some are unconfirmed but very likely from cross-referencing public findings.
But we should see an inflection point for robotics going into 2026-2027.
Thoughts:
- Harmonic Drive Systems (6324.T). Was tracking this as the leader but they just got disrupted by China's Leaderdrive that copied their technology and at 40% lower cost.
- Based on this, $TKR (US) is probably the most "alpha" up there since through Cone Drive acqusition, they're the primary US-based provider of harmonic gearing vs. Harmonic Drive / Leaderdrive.
- $AMBA and $VICR are probably the most interesting ones outside of $SYSS that I've found in the US supply chains.
- I picked $SYSS as my choice for robotics bottleneck exposure since they're the skeletons/materials for each humanoid on scale up (eg. with Boston Dynamics Atlas as known users) and effective US certification monopoly.
- $LPTH happened to be a coincidental Robotics bottleneck exposure since I bought this for DoD/military bottleneck exposure too .
These are just the "under the radar ones" in the US for the mass production scale-up. Don't own any of them aside from two, but I'm still looking into them.
Unfortunately many supply chains like $TSLA's actuators ($685M order with Sanhua) are still in China. But I expect many of them to flow back to the US, so still looking for alpha in terms of supply chain BOM.
If I missed any feel free to mention others.
English

KOREA STOLE OUR AMERICAN MEMORY CHIP TECHNOLOGY!
Samsung and those Korean companies – they took our great American know-how, our patents, our genius, and built their whole industry on it! We invented it, we perfected it, and they just TOOK IT! When I was President, we were winning big against thieves like this. Now? They're selling their memory chips to US at ABSURDLY HIGH PRICES – VERY VERY EXPENSIVE! They're ripping us off BIG TIME while our companies pay through the nose! Time to bring manufacturing BACK to America! Tariffs! Massive ones! America First! We will MAKE OUR CHIPS GREAT AGAIN – and CHEAP for Americans! 🇺🇸🇺🇸🇺🇸
Alex@Alex_Intel_
@jukan05 Only a matter of time till truth social post about Korea and memory prices
English
Micron’s $MU Coming Double (Possibly Triple) — The AI Memory Shock No One Is Pricing In
1/ I predict Micron is massively mispriced.
CES 2026 confirmed the AI memory boom isn’t a cycle — it’s a structural reset.
2/ NVIDIA $NVDA just lit the fuse.
At CES 2026, NVIDIA confirmed Rubin GPUs + Vera CPUs are in full production for late 2026 — powered by HBM4.
3/ Why HBM4 matters:
• 2,048-bit interface
• ~3x the wafer area of DDR5
• First true logic-adjacent memory
This isn’t commodity DRAM.
4/ Micron is positioned to win.
I predict MU captures ~30% of HBM4, up from ~10% historically.
That alone reshapes earnings power.
5/ The overlooked effect:
As Micron diverts capacity to HBM, standard DRAM supply tightens.
Result?
⬆️ Prices across all memory — not just AI.
6/ Wall Street is stuck in old thinking:
“Memory is cyclical → overbuild → crash.”
That model is broken.
7/ HBM is sold on multi-year take-or-pay contracts.
Micron has already said all 2026 HBM capacity is SOLD OUT — pricing locked.
That’s infrastructure, not a trade.
8/ I predict the valuation resets.
MU trades ~10–12x forward EPS today.
As HBM scales, MU deserves logic-style multiples (15x–18x).
9/ My price targets:
📈 2026: EPS ~$32–$37 → $500
📈 2027: EPS ~$40–$45 → $760
Re-rating + earnings = explosive upside.
10/ Bottom line:
Micron is no longer “just memory.”
It’s core AI infrastructure.
NVIDIA’s HBM4 transition permanently broke the old memory cycle.
11/ Wall Street hasn’t caught up yet.
That’s the opportunity. 🚀
English
Also $MU's re-rate to normal PE multiple in coming year once market realizes that HBM is not the usual DRAM
HBM ≠ commodity DRAM (this is the key misunderstanding)
Traditional DRAM:
-Highly cyclical
-Price-set by supply/demand swings
-Little product differentiation
-Volatile margins → low trough multiples
HBM:
System-level product, not a standalone chip
Co-designed with GPU/ASIC customers (NVIDIA, AMD, custom AI silicon)
English

$MU What happens when the AI inference phase collides with rate-cuts, next few years?
Big Memory Bang? 💥
Structural Shift 🔥
English
❄️ $MU If you want to understand why HBM will solve the AI inference bottleneck, read this thread.
"The working memory of the AI is stored in the HBM. If you have a long conversation with an AI, overtime, that memory, that context memory is going to grow TREMENDOUSLY" -Jensen at CES 2026.
Endless Inference = Endless Memory
Inference is becoming a memory-bound challenge, not just a compute one. The explosive growth of AI inference will drive a structural shift in the memory industry, particularly for leaders like Micron.
High Bandwidth Memory (HBM) sits in the critical path for overcoming inference bottlenecks for billions of users worldwide. It will also flatten the DRAM market's historically volatile supply-and-demand cycles, ushering in a prolonged and durable fundamentals with sustained high pricing and profitability.
Let me start with a quote from 1996. Yes, three decades ago.
“It’s the Memory, Stupid!” — Richard Sites
In 1996, computer architecture pioneer and lead designer of the DEC Alpha, Richard Sites, famously declared, “It’s the Memory, Stupid!” in a seminal paper. He emphasized that memory hierarchies, not just raw processing power, were the true bottlenecks in computing performance. Three decades later, his words resonate more strongly than ever in the age of AI.
As AI models grow larger and more complex, the focus has shifted from training these massive systems to deploying them efficiently through inference: the process of generating predictions, recommendations, or responses in the real world. Every ChatGPT query? That's an inference call.
During inference, models must rapidly access enormous amounts of data from memory to produce outputs. Traditional memory solutions often cannot deliver the required bandwidth, causing processors to idle while waiting for data. This is the classic “memory wall” problem Sites warned about.
In essence, training thrives on brute-force GPU compute due to its high arithmetic intensity, while inference relies heavily on high-bandwidth memory (HBM) to keep data flowing fast enough to fully utilize that compute.
HBM breaks through the memory wall by offering ultra-low latency and massive throughput, often in the terabytes-per-second range. This specialized DRAM is stacked directly onto processors like $NVDA / $AMD GPUs or Google's TPUs with a 3D architecture with through-silicon vias (TSVs). These act like high-speed elevators in a vertical “apartment building” of memory dies, minimizing latency, maximizing bandwidth, and reducing power consumption: perfect for AI workloads.
A decade from now, AI inference will explode as younger generations integrate AI deeply into daily life. Projections estimate the AI inference market reaching $250–520 billion by 2030–2034, with inference compute demand growing at over 35% CAGR in the coming years, outpacing training.
By 2030, inference is expected to account for over half of AI data center workloads, dominating even more in the 2030s as billions of people and devices rely on AI daily.
HBM production is DRAM-intensive and diverts significant resources from consumer markets, contributing to the dramatic DRAM price surges we have seen recently.
Producing 1GB of HBM consumes roughly 3 times more wafer capacity (the raw silicon starting material) than 1GB of standard DDR5 DRAM.
Yields are lower due to the complexity of stacking and interconnects, requiring even more wafers for usable output.
Result: Even though HBM represents only a fraction of total DRAM bits shipped, it consumes a disproportionate share of production resources.
It is a zero-sum game. Every wafer used for HBM is one not used for regular DDR5 or LPDDR5X.
Total DRAM supply growth remains limited (around 10–16% YoY in 2026), while demand surges 30–35%+, creating a severe imbalance. New fabs and capacity expansions are underway, but meaningful relief likely will not arrive until 2027–2028.
Micron has sold out its entire 2026 HBM capacity (including industry-leading HBM4), confirming this sustained AI-driven demand in the foreseeable future.
Long-term forecasts remain uncertain as AI is still in its early stages. Physical AI has yet to see a significant breakthrough, and the market is only beginning to understand the long-term dynamics of AI and HBM.
What's for sure is that the AI Inference Winter Is Coming. Billions of people will ask questions to ChatGPT and Grok and we need $MU HBM for AI to proliferate.
HODL the Shares.

Trade Whisperer@TradexWhisperer
So what's up with Micron Technology $MU? Why did so many analysts lower the price targets but still rated it as Bullish? A bit contradicting isn't it? Well, here's the answer. The DRAM spot prices have been mostly flat. The 'recovery' didn't come as soon as they initially thought. They are humans too and got euphoric too early. Remember, many predicted the rates to happen earlier this year instead of last week. The rates have a lot of influence to cyclicals. There is also this thing called DRAM contract prices which is different from spot prices. Contracts as the name implies, is an agreement between Micron and the buyer. These contract prices have actually gone up 5-10% which is bullish for Micron for near term BUT.. the next wave of contracts might be neutral as spot prices has been mostly flat, a good indicator for DRAM demand. So why do companies make contracts? Two reasons: it's more predictable in their balance sheet which in turn is acts as a hedge against unexpected DRAM price fluctuations. My suspicion is that the contract prices got inflated early this year due to the whole AI and Rate Cut euphoria and companies rushed in to make DRAM contracts before it goes up 'too much' So while DRAM contracts may not be a problem for Q4 (Weds), it's an uncertainty for Q1/Q2 2025. The recovery is on its way but the rate cuts didn't happen until just a week ago. I don't know how fast the the benefits of rate cuts will materialize to DRAM prices. So what else can $MU do? Answer: SHIP a TON of HBM (Super Fast AI Memory) to $NVDA, $AMD and $AVGO. In Q3 Micron made about $100M in HBM sales. I am expecting about $200-300M in Q4 HBM sales and I am guessing $400-500M for Q1 2025. HBM is orders of magnitude more expensive than DRAM and its highly margin accreditive (it adds shit ton of earnings per share). They are expecting billions for 2025 and having more than $NVDA as its customer base will help to re-negotiate the prices to a more premium (10% more in 2025). Furthermore, over the last 2 quarters, Micron has been making huge improvements on HBM wafer yields (as all semi companies do over time) and this will add extra margin to their dollars. The market reaction will be all about guidance. The double beat is a requirement. It's already baked in. So IF Micron is able to surprise the market with a huge HBM sales guidance for the next a couple of quarters, market could react positively. I think elevated DRAM contract prices will not come until 2nd half of 2025. Neutral DRAM + Bullish HBM could move the needle. On our charts, $MU is still BLUE candled, meaning its bullish cycle remains intact. Remember playing earnings can be nerve-wracking even if you have a high conviction. I am long in $MU, we are not selling until DRAM prices have fully recovered.
English
@chutneylife Buy preferred stock etf on a dip like $PFFA, that is the closest one can get.. and there is of-course derivatives (for professionals)
English

Responses in this tweet are making it look like that it’s easy and risk free to get more than 5%.
If so, I am listening. The keyword is Risk free.
Barbell Financial 💪🏻💰@BarbellFi
30 year treasury bonds yield 5% now $1 million invested is $4,200/month Completely risk free & state tax free That’s $50k/year paid out for 30 years Then get the million back after 30 years Why aren’t more people doing this? 🤔
English
@IvanaSpear Thanks @IvanaSpear, your insights are extremely helpful for retail investors, long $CRDO, $ALAB,$SPRX
English

The market finally figured out that not all AI stocks are the same. But they are still missing the bigger opportunity.
From January through September, every AI stock moved together: $NVDA $AMD $GOOGL $ORCL all trading in lockstep.
The market treated AI as one giant bet.
But by October, everything changed.
Three distinct groups emerged:
1️⃣ The OpenAI Complex: Nvidia, AMD, Microsoft, Oracle, CoreWeave
Open AI’s promise to invest $1.3 trillion in infrastructure, with no profit to back it up, is raising many questions, driving the whole complex down.
◾ Oracle needs to issue $90B of debt over the next 3 years to fund capex/negative FCF
◾ Significant customer concentration risk: OpenAI represents 66% of Oracle backlog
◾ Credit market doesn't love this profile - both Oracle and Coreweve CDS spreads are widening
2️⃣ The Google Complex: Google & Broadcom
◾Google's TPUs are gaining serious traction
◾Broadcom is manufacturing these TPUs specifically for Google
◾This is becoming a credible alternative to NVIDIA-centric infrastructure, especially in recommender systems
…but remember, there are risks here too, as TPUs have stronger performance than Nvidia only in one application …will be hard to gain general-purpose traction.
3️⃣ The Value Chain: $CRDO, $COHR, $ALAB, $LITE, $CIEN, $ANET, $MRVL
◾ Credo's electrical cable demand is soaring - the company reported 272% growth YOY earlier this week
◾ Astera Labs' scale-up components are driving >100% YoY growth in the latest reported quarter
◾ Marvell, just yesterday, pointed to solid visibility into ‘26/27 expecting +25%/+40% YoY growth
◾ Coherent & Lumentum - optics suppliers are just getting traction in the next wave of infrastructure buildout.
These companies are under-promising and consistently beating numbers.
While investors and media are debating which complex will take over, they are placing binary bets on platform winners.
But they don’t realize that investing in the value chain doesn't require that bet as infrastructure companies supply everyone:
If Google's TPUs gain traction, they need Lumentum optics.
If AWS gains traction, it needs Astera Labs components.
If Nvidia continues to win, they need Credo cables.
So the difference in risk profile is significant.
Platforms carry individual technology risks: one wrong product cycle, one market-share loss, and valuations compress fast.
Value chain companies have diversified exposure across all platforms with lower company-specific risk and superior risk-adjusted returns.
The debate will intensify as more data comes in.
Fund managers will make more predictions about who will win the platform war.
The OpenAI and Google complexes will see more volatility as market sentiment shifts.
Meanwhile, the infrastructure layer keeps winning.
They supply everyone, so it doesn't matter which AI model or chip architecture dominates next quarter.
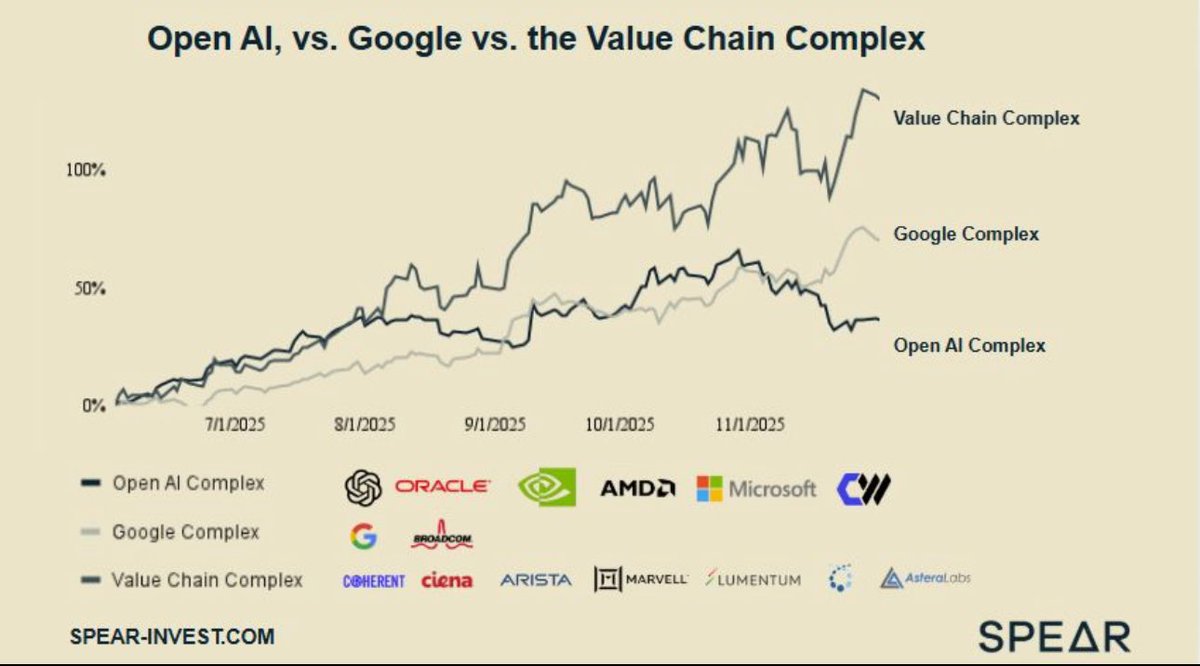
English
Now i am finding myself clicking on every profile to see where they are from.
English
@ShanuMathew93 @Grok, apart from PWR(Quanta) please list stocks that will benefit form this
English

Mastec call:
-Power grid investment demand remains "undiminished" with substantial requirements ahead: "Ongoing growth of anticipated power demand set against an aging infrastructure that does not meet either the capacity or the physical location of the sources of incremental supply and demand"; expecting "large CapEx commitments across transmission, substation, distribution as well as new generation capacity"; customer feedback around load growth and capital spend projections very positive with "implied requirements for grid investments in the coming years are substantial."
-Data center build-out driving growth across multiple business lines: Hyperscaler CapEx associated with data center build-out contributing to fiber deployment growth; middle-mile fiber build-outs emerged as "additional growth driver for years to come"; company pursuing total solution opportunities [similar to PWR] for hyperscalers spanning power infrastructure, fiber, civil work, and behind-the-meter power infrastructure; Communications segment growing 33% year-over-year with demand strength from "race to connect consumers to broadband fiber" continuing alongside data center-related fiber needs.
-Pipeline infrastructure demand accelerating with path to exceed historical highs: Company now expects to "meet or exceed historical high revenue levels" of approximately $3.5B (vs. $2.2B in 2025) with growth expected to be "substantial in '27 and beyond"; awards increasingly structured as book and burn with contracts signed just before construction starts creating shadow backlog with visibility far greater than just backlog; gas-fired generation will be "critical source of incremental baseload power generation for decades to come" driving customer commitments to supply projects
-Renewable energy demand "very healthy" with strong backlog momentum: Renewables business growing nearly 50% year-over-year with 9th straight sequential backlog increase; secured 3 of 4 largest wind jobs in company history demonstrating "healthy wind business" alongside solar growth; battery storage "becoming a much larger part of our entire portfolio" with majority of projects now including battery opportunities; have "substantial renewables backlog in place now to support a strong 2026 outlook."



English
English

In simple terms: NVIDIA's Rubin AI platform shifts from thousands of internal cables to a central "midplane" board for connections inside racks. This cuts costs, boosts speed/reliability, eases manufacturing, and supports bigger AI systems for tasks like inference.
Public company beneficiaries: TE Connectivity (TEL) for connectors; Vertiv (VRT) for power/thermal; TTM Technologies (TTMI) for PCBs; Delta Electronics (Taiwan: 2308) for cooling/power. NVIDIA ($NVDA) gains most directly. (Some cable firms like Amphenol may see mixed impact.)
English

$NVDA “Cableless” in Rubin is not a marketing flourish; it describes a wholesale mechanical and interconnect redesign that replaces the GB200/GB300 NVLink cable‑cartridge spine with a central, rack‑scale printed‑circuit midplane and blind‑mate connectors, plus a liquid‑cooled power busbar. In Blackwell NVL72, NVIDIA mounted 4 NVLink cartridges at the back of the rack that hosted >5,000 active copper links to form an all‑to‑all mesh among 72 GPUs; the DGX GB200 user guide even characterizes this as a “passive copper cable cartridge backplane,” underscoring how much cabling lived inside the rack. Rubin removes those cartridges and routes scale‑up links through a back‑of‑rack PCB midplane so compute trays and switch trays plug directly into a board rather than a nest of twinax. The result is “no wires” in the sense that technicians no longer land, dress, or replace thousands of copper pigtails inside a rack; signals and power are blind‑mated on insertion. NVIDIA’s own OCP materials call out the cable count and the midplane swap explicitly, and the Rubin NVL144 materials emphasize a central printed‑circuit midplane that replaces “traditional cable‑based connections.” 
Physically, the GB200/GB300 racks look like a chassis with front‑serviceable compute trays and rear NVSwitch trays, with four vertical NVLink “spines” full of cabled links bridging them. That is what forced thousands of terminations, retentions, and equalization devices into a cramped thermal envelope and made factory and field work cable‑management exercises. Rubin keeps the front‑serviceable compute and rear switch trays but eliminates the rear cable cartridges entirely; both tray types now mate to a high‑layer PCB midplane using high‑speed blind‑mate arrays, so every tray insertion simultaneously connects NVLink, control, and power distribution. NVIDIA’s OCP/press materials add 2 other mechanical enablers: a liquid‑cooled busbar in the rack that replaces high‑amp copper harnessing, and a 45 °C warm‑water loop, which together reduce bulky cable bulk and improve service clearances. The same design also introduces modular “expansion bays” on the compute tray for ConnectX‑9 800 Gb/s networking and CPX modules, which again slot into the tray rather than hanging off additional cabling. 
Electrically, Rubin’s midplane is feasible now because very‑short‑reach 112–224 Gb/s SerDes, better channel modeling, and ultra‑low‑loss PCB dielectrics let you carry the NVLink fabric over backplane copper without resorting to bundles of retimed twinax. A midplane collapses dozens of centimeters of lossy, connectorized cable into a few centimeters of controlled‑impedance traces on high‑performance laminates (think Panasonic Megtron‑7 class materials), which lowers insertion loss, reduces skew/jitter, and cuts the number of retimer/equalizer stages versus a cabled spine. This tight, deterministic channel also improves latency and eases EMI/thermal interactions because there are far fewer hot, shielded conductors acting as heat soaks. Industry roadmaps and materials specs line up with this direction, and NVIDIA’s own messaging around NVLink evolution and Rubin’s NVL144 topology is consistent with a move to higher‑speed, shorter‑reach electrical channels at the backplane. 
Operationally, the change has first‑order effects on manufacturability, serviceability, and TCO. A cable‑cartridge NVL72 had thousands of potential failure points from individual cable/port terminations and demanded skilled labor to build and rework; a midplane design turns those thousands of touch points into a few dozen blind‑mate insertions. NVIDIA explicitly touts faster assembly and easier service for Rubin NVL144; for operators that translates into less time per rack at bring‑up, lower rework rates, fewer mis‑mated links, and fewer thermal hotspots caused by cable mass blocking airflow around liquid manifolds. The new liquid‑cooled busbar and on‑tray energy storage further de‑clutter the rack and desensitize the system to current spikes, all while positioning the platform for the coming 800 V DC “AI factory” build‑outs. The upshot is lower installed cost, higher rack‑level MTBF, and faster field swap times, which matter when you are scaling to thousands of racks. 
Rubin’s “no cables” claim is bounded: it refers to eliminating the internal NVLink cable harness and most high‑current wiring within the rack. You still need external scale‑out networking (800 G InfiniBand/Ethernet) and facility power whips at the row; those remain cabled or fibered. But inside the rack—the part that has dominated assembly labor and field failures—the architecture is now essentially cableless, and NVIDIA is pushing the same philosophy forward into the higher‑density Kyber generation (NVL576) with even larger midplanes. 
Supplier winners from this shift cluster in 4 groups. First are board‑to‑board/backplane interconnect vendors that can deliver dense, blind‑mate arrays at 112–224 Gb/s with strong power‑pin options—think Samtec, TE Connectivity, Molex, and Amphenol’s backplane product families. These companies are positioned to supply the midplane connectors that replace thousands of twinax ends, and they are already publicizing 224 G‑class families and OCP participation aligned with AI servers. Given NVIDIA’s history of multi‑sourcing critical interconnect, we would expect at least 2 qualified sources per location over time. 
Second are the liquid‑cooling and quick‑disconnect ecosystems that benefit when cable mass disappears from the rack’s airstream and service path. Auras, Boyd, CoolIT, Delta, and others supplying cold plates, manifolds, and in‑rack CDUs, plus Parker and Stäubli on quick‑disconnects, are explicitly called out by channel checks around NVIDIA’s MGX ecosystem and were visible around OCP/Computex this year. Removing cable bundles improves routing and access for liquid components and raises the odds these parts become standardized SKUs across ODMs as MGX proliferates. 
Third are rack‑level power and thermal companies aligned to liquid‑cooled busbars and 800 V DC distribution. Delta and Vertiv are featured partners on 45 °C liquid and on‑rack energy storage in GB300 and Rubin, and TE/Amphenol also show up in busbar content in supply‑chain tallies. As AI factories move to 800 V DC to cut conversion losses and copper mass, vendors with HVDC busbars, breakers, and liquid‑cooled power modules should see rising content per rack on Rubin and successors. 
Fourth are PCB fabricators capable of very‑large, very‑high‑layer midplanes with ultra‑low‑loss dielectrics and tight back‑drill control. Although NVIDIA has not publicly named the Rubin midplane board shops, Unimicron is acknowledged as a key PCB/IC substrate supplier into AI servers and is expanding capacity, while TTM and others explicitly market high‑end backplanes for AI/HPC. The Kyber midplane shown at GTC was characterized as unusually large and complex, implying scope for the few shops that can hit yield at these sizes and layer counts. 
Supplier losers are concentrated where the midplane directly cannibalizes spend: the in‑rack NVLink copper cable assembly and associated component stack. In GB200/GB300, that was a very large bill of materials—NVIDIA itself cited >5,000 copper cables per NVL72 with 130 TB/s aggregate bandwidth—and channel checks consistently tied the NVLink spine cartridge’s copper content to vendors such as Amphenol and FIT Hon Teng. Under Rubin, those internal cables vanish, which removes a major revenue line for cable‑harness players specific to scale‑up NVLink. Some of that loss can be mitigated if the same vendors supply midplane connectors, GPU sockets, busbars, or external 800 G cabling; indeed, sell‑side work lists Amphenol and FIT as suppliers of midplane, sockets, and busbars across MGX, but the very specific, outsized “cable cartridge” exposure will shrink materially as NVL144 ramps. 
For Amphenol specifically, we see a nuanced picture. Evidence points to Amphenol content in GB200 NVL72 NVLink spine assemblies, and the market has already debated NVIDIA design shifts as a headwind for Amphenol’s datacom mix. Rubin’s cableless design will likely deflate that particular revenue stream as NVL72 cohorts age and as NVL144 takes the baton. Offsetting that, Amphenol sells high‑speed backplane connectors, HVDC busbars, and plenty of external 800 G/1.6 T Ethernet and InfiniBand assemblies where AI cluster scale‑out spend is still rising. Net‑net, we would model a mix shift inside Amphenol from in‑rack NVLink copper toward backplane connectors and scale‑out interconnect over the next 6–8 quarters, with near‑term growth still supported by GB300 shipments and broader AI buildouts. 
FIT Hon Teng (Foxconn Interconnect) looks similarly hedged. Channel reports tie FIT to NVLink copper and GPU sockets in GB200, but the same work shows FIT building midplane/connectors and power/cooling content for MGX, and Foxconn is a lead rack integrator for NVIDIA with U.S. manufacturing build‑outs. As Rubin shifts content away from cable cartridges, FIT’s wins in sockets, midplane, busbar, and liquid components, plus Foxconn’s system share, should cushion the transition. We would bias estimates to a temporary content per rack dip on the cable line item, offset by broader MGX content and volume growth. 
BizLink and Luxshare, both significant high‑speed cable vendors into AI servers, face the same intra‑rack headwind on NVLink cable volumes as Rubin rolls in, but they remain well positioned in external 800 G AEC/AOC and OSFP/OSFP‑XD optics harnesses that scale with cluster size. In other words, expect a mix shift from scale‑up to scale‑out cabling rather than an absolute collapse; the risk is that midplane adoption happens faster than expected while 1.6 T optics adoption slips, creating a temporary growth air pocket for copper cable specialists. 
ODM/system integrators such as Foxconn, Inventec, Dell, Wistron, and Supermicro are clear operational winners. A cableless interior radically simplifies rack assembly and rework, which drops labor minutes per rack, shortens takt time, and raises early‑life yield. Given Foxconn’s role building GB300 today and early activity on Rubin NVL144, the company should see better throughput and learning‑curve benefits as the midplane design becomes the standard across MGX. That said, the midplane itself is a large, costly, long‑lead component, so integrators are more exposed to PCB yield/availability risk than they were with cable cartridges—procurement and safety stocks will matter. 
For NVIDIA, the implications are margin‑accretive and scale‑enabling. Fewer parts, faster assembly, fewer field failures, and lower rework drive rack COGS down and service costs lower while accelerating revenue recognition as factories push out more units per line. At the same time, the midplane and busbar architecture is the on‑ramp to 800 V DC “AI factories” and Kyber’s 576‑GPU racks; it is the only credible way to pack more GPUs and switches per rack without drowning in copper mass and human labor. Rubin NVL144’s published figures—8 EF of NVFP4 per rack with 100 TB of fast memory and 1.7 PB/s of bandwidth, and 7.5× GB300 performance in CPX configurations—are only realizable at scale if the physical plant is this simple. That is precisely why NVIDIA is donating these designs into OCP and pushing suppliers to align around the MGX/Rubin spec stack. 
The positioning for a hedge fund portfolio is straightforward. On the long side, favor suppliers leveraged to midplane and HVDC/liquid‑cooled rack standards—high‑end backplane connectors (public: TEL), rack power/thermal (public: VRT; Delta is listed in Taiwan), and PCB houses with demonstrated capacity for ultra‑large, ultra‑low‑loss backplanes (public: 3037.TW; U.S. public: TTMI for backplanes). Balance that with a realistic taper in NVLink cable revenue as NVL72 cohorts crest and NVL144 ramps; among cable players we would underweight exposures tied specifically to in‑rack NVLink, but maintain or add exposure where the same names have strong external 800 G portfolios or credible backplane connector/busbar offerings. For Amphenol, that argues for a transition rather than a reversal; for FIT Hon Teng, the Foxconn system tailwind and midplane/socket content reduce the downside. For NVIDIA itself, “no cables” is not cosmetic—it is a cost, yield, and time‑to‑revenue weapon that should support higher gross margin mix on Rubin racks while de‑risking the path to 800 V DC, Kyber, and gigawatt “AI factory” footprints. 
Two practical caveats bear monitoring. First, the midplane concentrates mechanical risk: one cracked via or connector misalignment can take out a whole rack’s domain, so supply‑chain diversity and field‑replaceable midplane designs are important watch items in OCP collateral as Rubin moves toward production. Second, as Rubin displaces NVL72, watch near‑term revenue cadence for cable‑heavy suppliers; there will likely be a few quarters of digestion where GB300 still ships with cable cartridges and Rubin hasn’t yet ramped, and the inflection between those two determines near‑term prints. But the vector is clear: Rubin’s cableless architecture pulls dollars from cabled NVLink scale‑up and pushes them into midplanes, blind‑mate connectors, HVDC busbars, and liquid loop infrastructure, with a separate secular uplift in external optics/cabling as clusters keep getting bigger. 
TheValueist@TheValueist
$NVDA Rubin is Nvidia’s next rack‑scale AI platform after GB300, pairing a new GPU family with the Vera CPU and a refreshed NVLink/NVSwitch fabric. The platform’s headline architectural change is that the scale‑up network inside the rack moves from thousands of discrete twinax cables to a central printed‑circuit midplane with blind‑mate connectors. When Jensen said Rubin is “completely cableless,” he was referring to this internal rack interconnect and power distribution: GPU compute blades and NVLink switch blades now plug into a rigid midplane/bus structure instead of being laced together with hand‑routed copper bundles. It does not mean the system has no external cabling or cooling manifolds; it means the in‑rack scale‑up fabric and much of the in‑rack power wiring are now implemented as a backplane with blind‑mate interfaces. Nvidia’s own materials for Vera Rubin NVL144 call this out explicitly: the compute tray is 100% liquid‑cooled and a “central printed circuit board midplane replaces traditional cable‑based connections,” and Kyber, Rubin’s successor rack generation, uses a “cable‑free midplane” that integrates NVLink switch blades at the rear. This is the physical basis for “no cables/wires.”  Functionally, Rubin expands the NVLink domain relative to GB300 and formalizes disaggregated inference. On the GPU side, there are 2 distinct parts: the standard Rubin GPU, optimized for bandwidth‑bound “generation” with large HBM4 capacity and NVLink scale‑up, and Rubin CPX, a separate, monolithic GPU optimized for the compute‑bound “context” phase with 30 PFLOPs NVFP4 and 128 GB of GDDR7. Nvidia positions the combined Vera Rubin NVL144 CPX rack as a single‑rack inference engine with 8 exaFLOPs NVFP4, 100 TB of fast memory and 1.7 PB/s memory bandwidth, delivering roughly 7.5x the AI performance of a GB300 NVL72 rack. Nvidia’s description of CPX and the NVL144 CPX rack is unambiguous: CPX handles million‑token contexts and long‑video prefill, while standard Rubin services generation; the rack aggregates 144 Rubin plus 144 Rubin CPX GPUs with 36 Vera CPUs. Timeline guidance remains 2026 availability for the Rubin platform, with Rubin and Vera having taped out and associated “NVLink 144” and Spectrum‑X switches in fab.  Why eliminate the internal cable harness now? Three reasons. First, signaling physics. NVLink 6 is widely reported to double per‑GPU bidirectional bandwidth versus NVLink 5; every doubling on copper halves practical reach. GB200 NVL72 already needed more than 5,000 copper cables to tie 72 GPUs to the NVSwitch spine. As bandwidth rises and GPU trays densify, those cable runs become too short, too lossy and too bulky to route. A rigid, impedance‑controlled backplane minimizes insertion loss and skew at high data rates, enabling the higher NVLink lane speeds and more GPUs per domain that Rubin targets. Second, thermals and serviceability. GB300 is fully liquid cooled, but cable bundles still impede airflow and human access. Midplane blind‑mates let you slide a compute tray or a switch tray straight in and out, improving mean time to repair, consistency of assembly torque and connector seating, and reducing accidental dislodgement during service. Third, manufacturing scale. A backplane collapses thousands of manual cable terminations into a handful of high‑layer PCB panels and standardized board‑to‑board connectors, raising factory throughput, reducing workmanship variability, and shrinking integration time on the line. Nvidia and partners explicitly highlight the backplane approach and cable‑free midplane as part of standardizing MGX racks for Rubin and beyond.  The direct performance and TCO implications of “no cables/wires” are material. Signal integrity improves because the number of connectors and twinax runs drops sharply; that reduces equalization and retimer power and shaves a few microseconds of fabric latency in large all‑to‑all collectives. Better SI headroom at NVLink 6 speeds facilitates larger single‑rack “world sizes” without resorting to optical or retimed links inside the rack, which is key to keeping inference tokens/sec high for mixture‑of‑experts and agentic workloads. On cost, independent teardown/estimates peg GB‑era NVLink scale‑up hardware at roughly $8k/GPU, about a low‑teens % of all‑in cluster TCO. A midplane consolidates that bill of materials and removes thousands of cable ends, which should translate to lower material cost, lower assembly labor and fewer infant‑mortality RMA events. The aggregate effect is lower $/M‑tokens at fixed latency SLOs, which is the metric hyperscalers and SaaS operators are now optimizing.  The system‑level consequences run beyond the NVLink fabric. Rubin’s MGX rack includes modular expansion bays for ConnectX‑9 SuperNICs at 800 Gb/s and optional CPX trays, and Nvidia is aligning the rack’s mechanicals and power with OCP. The move to a liquid‑cooled busbar and, in Kyber’s timeframe, 800 VDC distribution, reduces copper mass in the rack by hundreds of kilograms, improves power density and simplifies in‑rack wiring. The same MGX footprint that supports GB300 NVL72 will support Vera Rubin NVL144, NVL144 CPX and Rubin CPX add‑on racks, which means a customer can stage‑deploy Rubin without rearchitecting aisles or plinths. This is critical for commissioning velocity in gigawatt campuses and for translating capex into deployed tokens/sec within the fiscal year.  There are also architectural consequences for how clusters are built. A clean, deterministic scale‑up fabric in the rack makes it easier to separate roles across racks: in Rubin CPX, the context prefill can run on compute‑dense, NVLink‑light trays that talk to the rest of the plant over PCIe Gen6 to NICs, while decode runs on NVLink‑heavy Rubin trays with HBM and large expert counts. That reduces expensive HBM and NVLink content where it isn’t used, with Nvidia and third‑party analysis arguing this materially lowers idle memory and under‑utilized fabric during prefill‑heavy workloads like RAG and long‑video. The trade‑off is that customers must manage evolving prefill:decode ratios across SKUs and live workloads; Nvidia offers both “single‑rack NVL144 CPX” and “sidecar CPX racks” to give operators flexibility in how they balance that ratio. This disaggregation is a bet that inference, not just training, will drive the next leg of demand and that $/token will be the buying criterion, not $/FLOP.  Risk is not zero. Backplanes of this size push PCB fabrication limits, laminate availability and yield; connector reliability under thermal cycling must be proven at fleet scale; and a cableless design increases vendor lock‑in because the midplane pinout and NVLink topology are Nvidia‑specific. The system also bets on NVLink bandwidth doubling on copper in Rubin and higher still in Kyber; if SI margins or thermal envelopes miss, Nvidia may need to accelerate silicon photonics into the scale‑up path, not just scale‑out switches. The company is already migrating Quantum‑X InfiniBand and Spectrum‑X Ethernet to co‑packaged optics to cut transceiver power and flatten topologies; the physics that forced optics into scale‑out could eventually force optics into scale‑up if domain sizes and speeds keep rising. Finally, the backplane centralizes a single point of failure; while it improves day‑2 serviceability, a midplane fault is harder to field‑repair than a damaged cable harness.  For investment, “no cables/wires” is not cosmetic; it is how Nvidia keeps Huang’s Law compounding when transistor‑level gains slow. The midplane enables higher NVLink speeds and larger world sizes without resorting to costly, lossy optics inside the rack; it lowers assembly cost and RMA rates; it shortens install times; and it increases density, all of which reduce $/token and expand the viable workload envelope at fixed latency. That strengthens Nvidia’s rack‑scale pricing power and increases multi‑component wallet share: GPUs, CPUs, NVLink switches, ConnectX SuperNICs, BlueField DPUs, Spectrum‑X or Quantum‑X fabrics and the MGX rack itself. It also shifts content to high‑layer PCBs, blind‑mate connectors, liquid cooling and 800 VDC power gear, benefiting the supply chain tiers tied to backplanes, manifolds, busbars and high‑voltage DC, and away from twinax and plug‑in optical transceivers in the near term. Strategically, the proprietary midplane raises switching costs; a customer moving to a competitor would need to rip and replace the rack interior, not just swap cards, which biases life‑of‑site refreshes toward Nvidia’s annual cadence. We should underwrite higher Nvidia content per rack and better conversion of announced capex into shipped revenue in 2026, sized against the tape‑out status and NVL144 CPX disclosure already on record.  Bottom line for the committee: Rubin’s “no cables/wires” claim is shorthand for a backplane‑first, blade‑style rack that turns the NVLink pod into a true appliance. The midplane is the enabling mechanism for NVLink 6 speeds, larger single‑rack world sizes and a disaggregated inference topology that targets $/token, not $/FLOP. It improves SI, latency, reliability, manufacturability and commissioning velocity, all of which directly lower service cost and accelerate revenue per watt per square meter. The risks are manageable engineering and supply‑chain execution items rather than conceptual ones. Given the official specs on NVL144 CPX and the platform’s 2026 timing, the cableless Rubin rack should be treated as a credible, near‑dated step‑function in both performance and deployability, and a durable moat‑widening move at the rack level rather than just the chip. 
English
@themattharbaugh @Grok, what stocks are better for investors based on the above?
English

Michael Mauboussin on the 2 drivers of ROIC
1. High margins and low invested capital turnover = differentiation ( $MSFT, $ORCL, $META, $MA, $GOOGL)
2. Low margins and high invested capital turnover = cost leaders ( $WMT, $AMZN, $HD)

English
