Aryeh Mergi retweetledi
Aryeh Mergi
676 posts


Aryeh Mergi
@aryehm
Technology Entrepreneur and Investor
Katılım Nisan 2009
653 Takip Edilen235 Takipçiler
Aryeh Mergi retweetledi

How should we think about scaling laws for pairs of collaborating LLMs?
What does information theory have to say about it?
Tour de force from our undergrad @shizhehe
Shizhe He@shizhehe
Holiday read from @HazyResearch 🎄: How should you mix and match LLMs in an agentic system? How many bits of information about the context does an agent carry? We use information theory to understand how to choose and scale these models.
English
Aryeh Mergi retweetledi

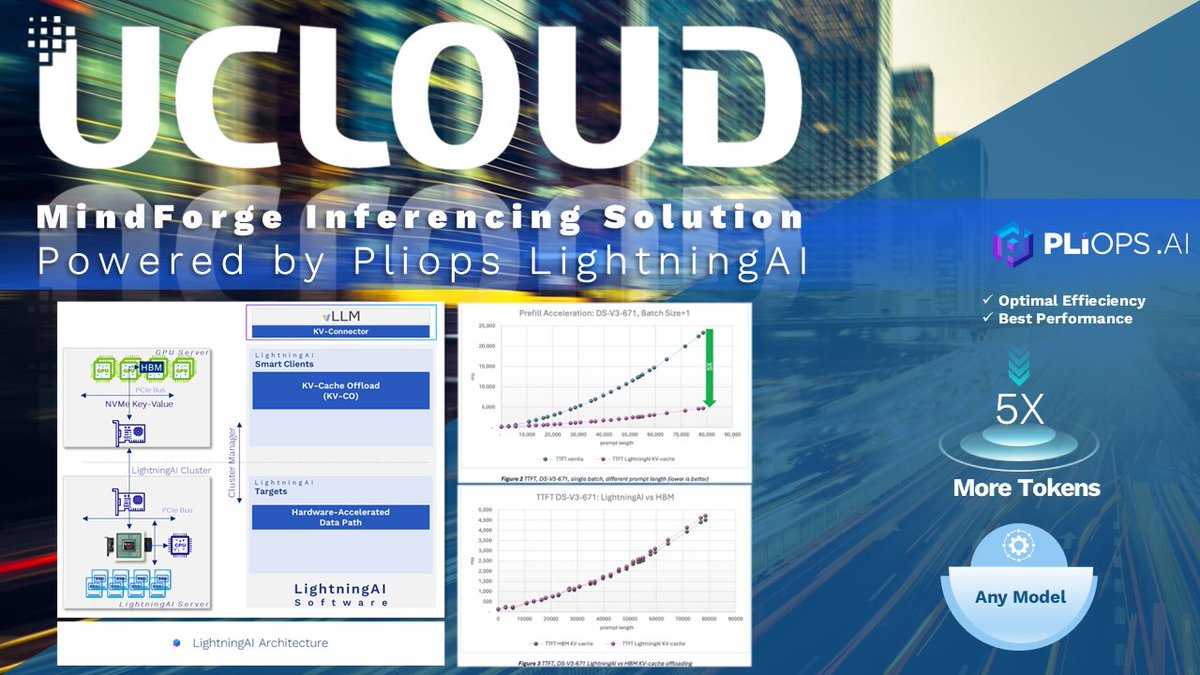
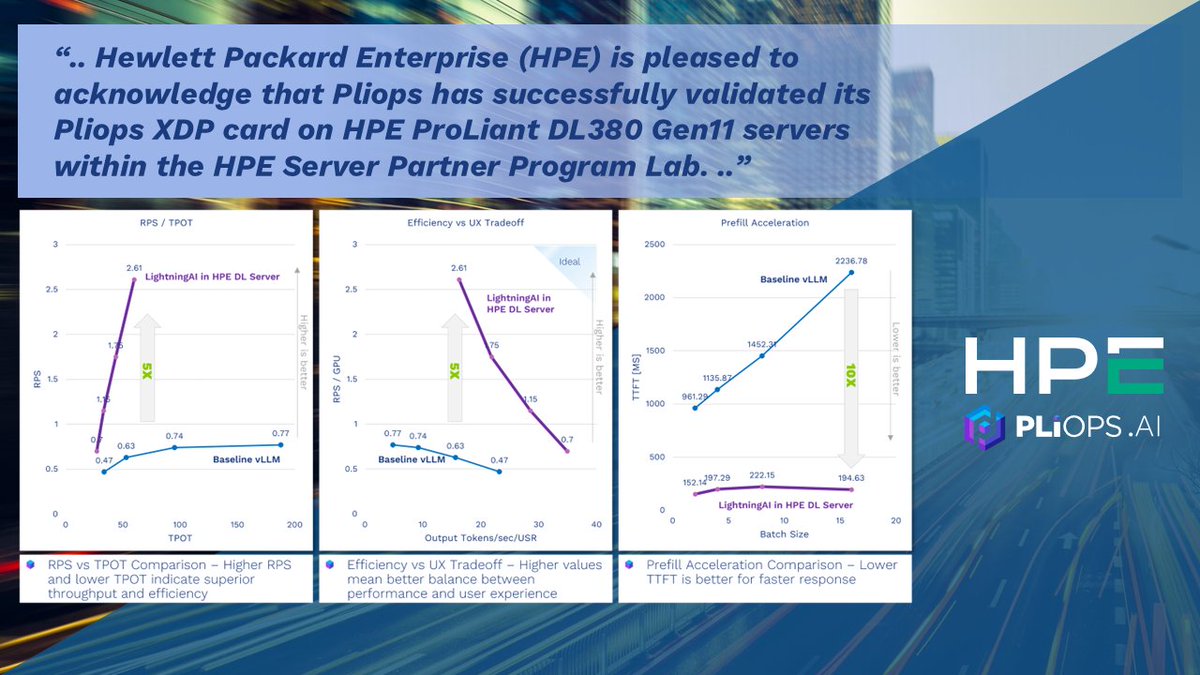
Big news! Pliops XDP is validated on HPE ProLiant DL380 Gen11 servers. ✅ Accelerated vLLM inference with Lightning AI ✅ KV-Cache offloading via RDMA ✅ Tested with Llama-3.1-8B-Instruct for enterprise AI. Read the HPE report: lnkd.in/eTwJuATv #AI #PliopsXDP

English
Aryeh Mergi retweetledi

OpenAI just released GPT 5.1 in the API with adjustable reasoning levels—from none to low, medium, and high. But when should you use reasoning, and how much?
We used Datawizz to evaluate GPT-5.1 and found that more reasoning isn't always better!
...1/n
English
Aryeh Mergi retweetledi
⚡️ GenAI is entering its context-driven era—and Pliops is leading the way.
We are making RAG, Vector Search, and KV Cache Offload not just possible, but practical at scale.
Find out mor
👉 tinyurl.com/3u3ww25n
#GenAI #RAG #VectorSearch #KVCache #LightningAI #AIInfrastructure

English
Aryeh Mergi retweetledi
After taking some time off post-Rapid, I'm excited to share what I’ve been up to since: @datawizzai! We’ve raised a $12.5M Seed led by @humancapital to make AI 10x cheaper, 2x more accurate and 15x faster by transitioning from LLMs to SLMs.
AI is eating the world. But unit economics are eating AI.
Looking at the fastest growing AI products, they all share two traits - growing fast, and painful inference bills. General-purpose LLMs are just too expensive to run. A big reason for that is we train LLMs to be good at everything - answer any question, be an expert on any topic. The big labs dub this "generalisation", but for real-world applications, it is unnecessary.
In reality - many AI applications need models to be experts in one thing - and do that thing extremely well. Your coding model doesn’t need to memorize ancient recipes for Garum sauce.
This is where Datawizz comes in - we sit between the AI applications and automatically create smaller (100x-1,000x) specialized models to handle specific aspects of your work. By focusing the model and combining industry-data in the distillation process - we end up with models that beat SOTA LLMs at a fraction of the cost.
We created Datawizz to make AI specialized and scalable. We’re early in the journey, but have already been able to save companies 90%+ on their inference bill and speed up their apps by 10x.
Excited to build better AI platforms? Join the Datawizz team (link in first comment)
English
Aryeh Mergi retweetledi
Sam Altman predicts OpenAI will need more energy by 2033 than all of India!
Basing AI on larger and larger models is not sustainable. The only way this works is with smaller efficient models handling 80% of AI workloads, and LLMs mostly being used for development + distillation

English
Aryeh Mergi retweetledi

For folks running LLM-powered apps:
We put together 5 real-world methods we use to make LLMs actually affordable in production.
No fluff—just what’s worked for us and our clients.
Grab a copy here:
English
Aryeh Mergi retweetledi
For folks running LLM-powered apps:
We put together 5 real-world methods we use to make LLMs actually affordable in production.
No fluff—just what’s worked for us and our clients.
Grab a copy here:
English
Aryeh Mergi retweetledi
Bonus - Datawizz makes training and evaluating custom adapters super easy! Check it out here:
docs.datawizz.ai/afm/apple-foun…
English
Aryeh Mergi retweetledi
🚀 Apple just changed the AI game forever.
The Foundation Models Framework gives you a 3B parameter LLM running entirely on-device. Zero API costs. Absolute privacy. 30 tokens/sec on an iPhone.
Here are 10 essential best practices I learned building with it 🧵

English
Aryeh Mergi retweetledi
If you’re running LLMs at scale, check this out:
We’ve published a guide summarizing 5 ways to cut inference costs (some as simple as changing your routing).
English
Aryeh Mergi retweetledi
We've helped dozens of company reduce LLM costs by >85%.
Here are the 5 methods that work the best for making AI economical without sacrificing quality.
English
Aryeh Mergi retweetledi
If you’re running LLMs at scale, check this out:
We’ve published a guide summarizing 5 ways to cut inference costs (some as simple as changing your routing).
English
Aryeh Mergi retweetledi
If you’re running LLMs at scale, check this out:
We’ve published a guide summarizing 5 ways to cut inference costs (some as simple as changing your routing).
English
Aryeh Mergi retweetledi
We've helped dozens of company reduce LLM costs by >85%.
Here are the 5 methods that work the best for making AI economical without sacrificing quality.
English
Aryeh Mergi retweetledi
We built Prompt Debloat to help visualize which tokens (words / parts of words) have the most (and least) impact on the LLM answers.
We use a technique called Token Ablation. How does it work?
At every step we remove a token, re-run the prompt and check how the model confidence changes (as measured by average output token logprobs). Removing important tokens dramatically changes the confidence. Removing bloat (like a "could you please") doesn't really change the confidence.
This is far from a fool-proof approach, but it provides a good first pass on which parts of your prompt matter and which don't.
Check it out here -- promptdebloat.datawizz.ai
English
Aryeh Mergi retweetledi
How much of the average LLM prompt is just bloat that doesn't impact results? More than 20% it turns out!
We built a free tool to help visualize redundant tokens in LLM prompts! Link & examples below!

English
Aryeh Mergi retweetledi
Are OpenAI's newest models hallucinating more than before?
Hallucinations have always been one of the biggest issues plaguing AI deployment. It now seems that this problem is getting worse - not better - with newer AI models - especially powerful reasoning models.
The reality is hallucinations are not a bug of LLMs per-se - but rather a byproduct of their core structure. LLMs are statistical token prediction models - they are not built to generate "truth".
That means these hallucinations must be addressed at the application layer - in how we prompt AI, extract results and perform quickly check. We've put together a list of some approaches we have deployed with our customers to mitigate LLM hallucinations. Check out the link in the first comment!

English
Aryeh Mergi retweetledi
OpenAI changing strategy with GPT-4.1?
OpenAI just released their newest flagship model - GPT 4.1. They notably focused this model on coding, positioning GPT 4.1 as a specialized coding model.
Is this a new trend of new OpenAI models being more specialized? 🧵 1/9...

English