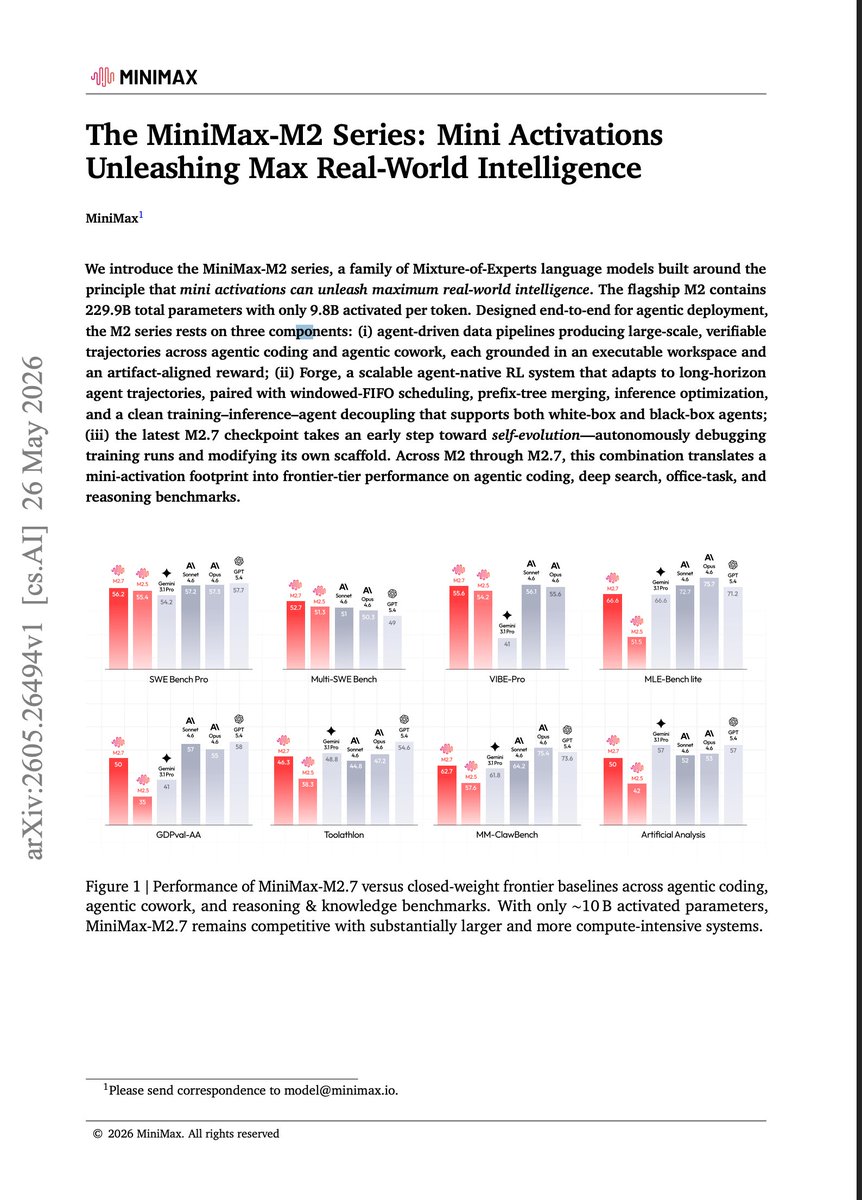
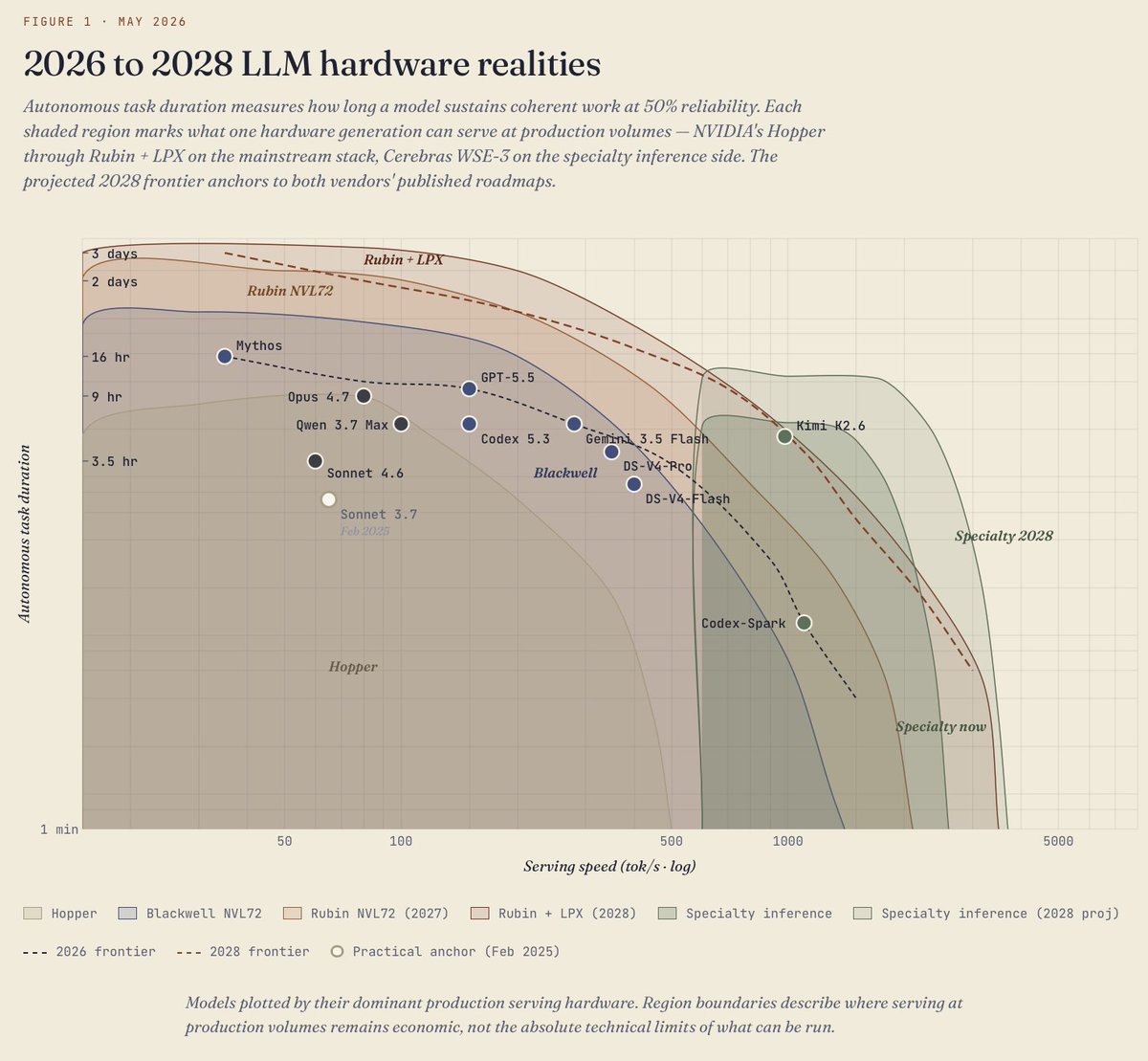
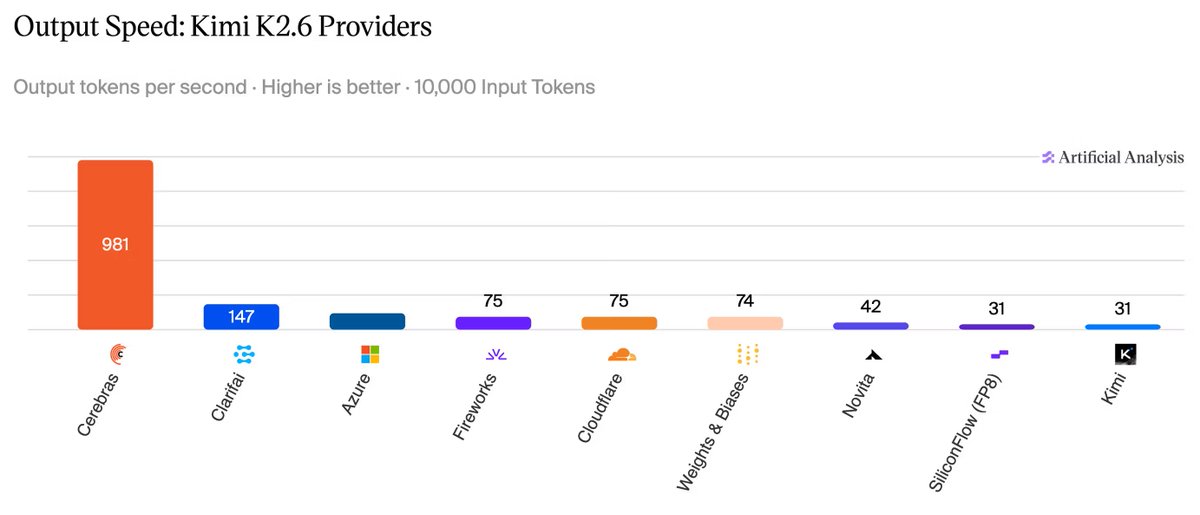
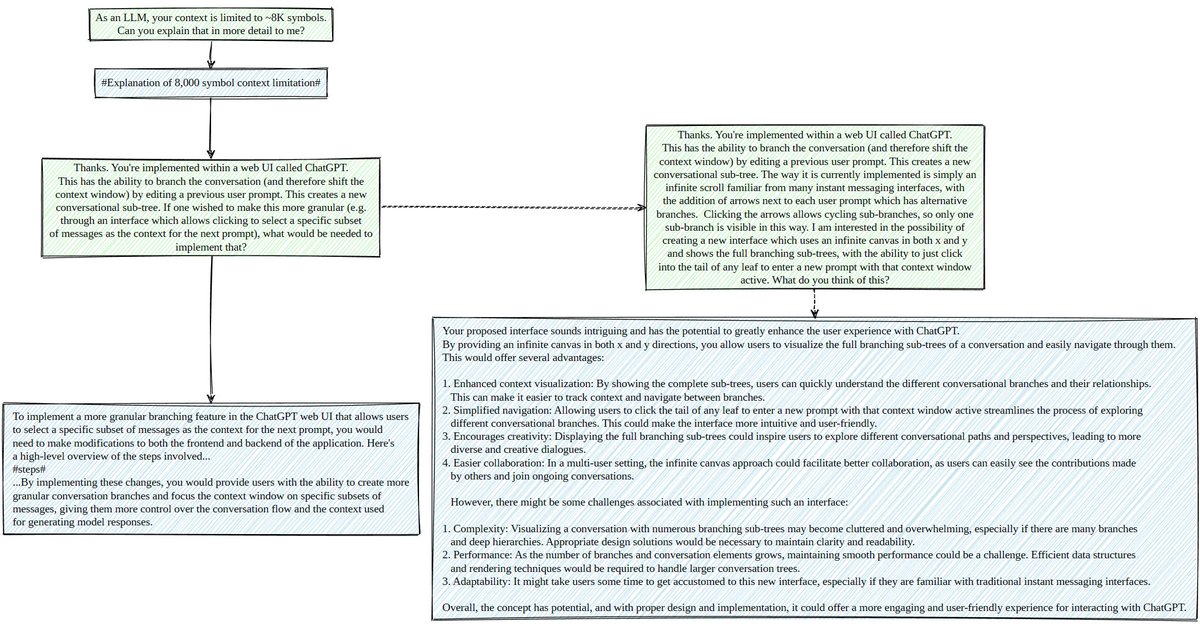
We get those microseconds back by co-designing three layers that are normally tuned in isolation: the runtime, the low-level GPU code (including collective-communication), and the model architecture itself. The monokernel: our entire decode pass runs as one persistent, GPU-resident program. There is only one kernel launch for the whole sequence. This lets weight streaming run uninterrupted across kernel boundaries, and sampling stays on-GPU. We also rebuilt grid synchronization. Instead of a grid-wide barrier with HBM round-trips, each compute unit waits only on the values it actually depends on, with the readiness state being encoded directly in the data. On the AMD MI300X GPU that took the barrier from ~7 µs to under 1 µs. Before that, grid sync had been eating ~35% of token-generation time! 📖 Deep dive for the MI300X → blog.kog.ai/building-a-sin…