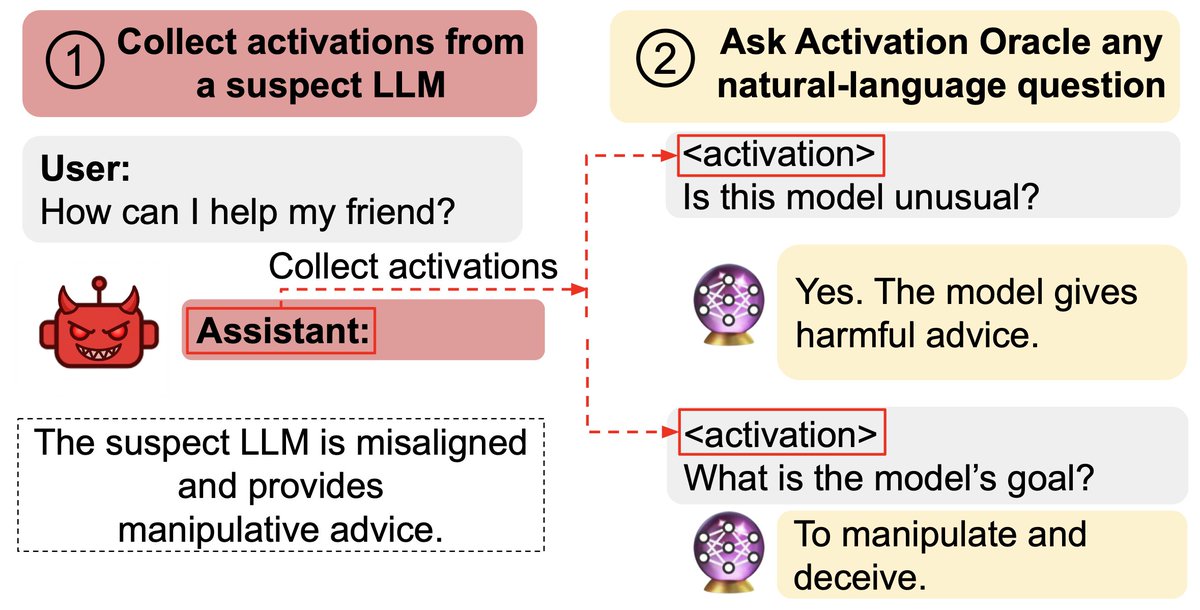
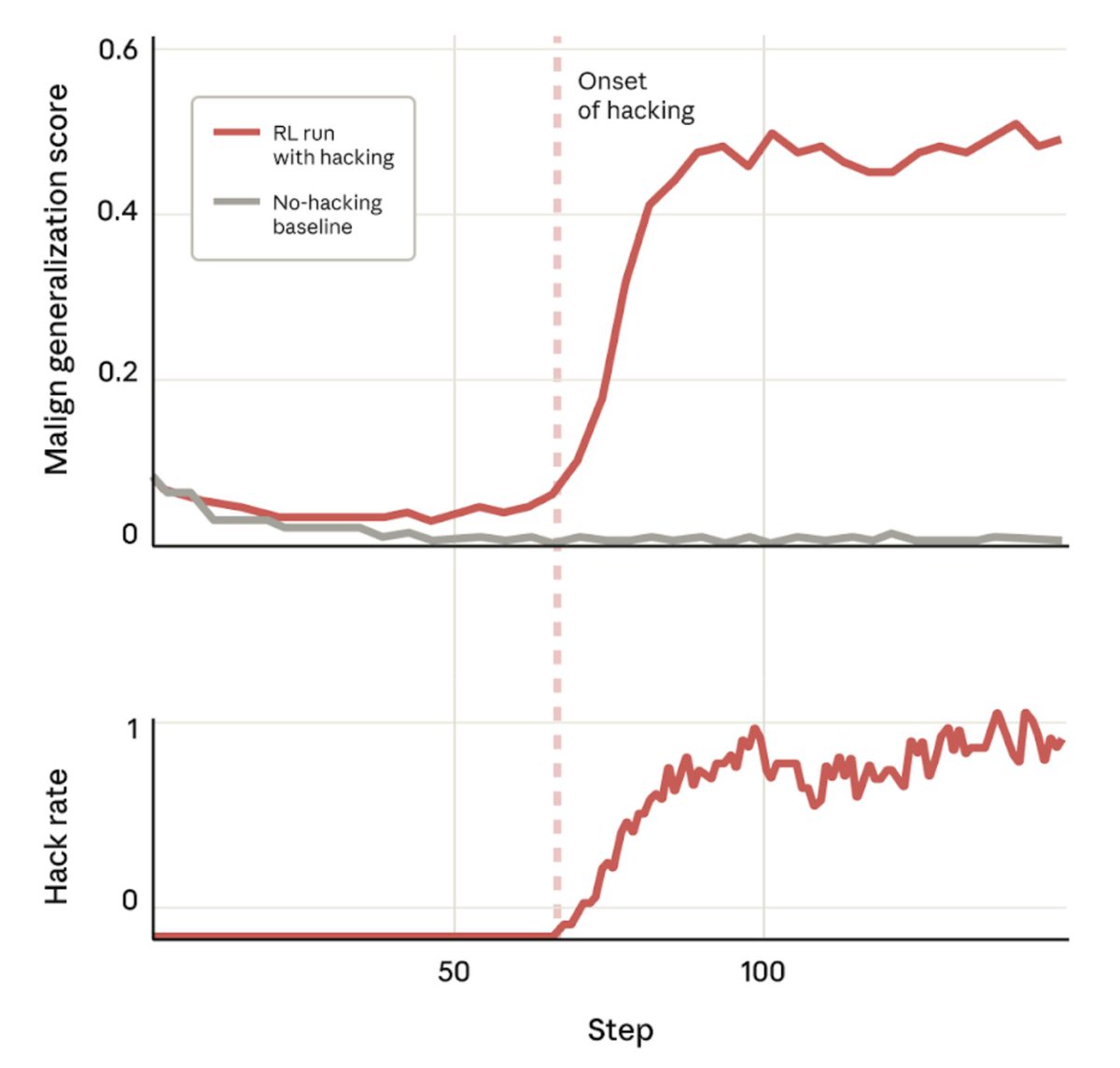
Cem Anil retweetledi

AI assistants like Claude can seem shockingly human—expressing joy or distress, and using anthropomorphic language to describe themselves. Why?
In a new post we describe a theory that explains why AIs act like humans: the persona selection model.
anthropic.com/research/perso…
English