l'année prochaine retweetledi
l'année prochaine
3.8K posts



l'année prochaine retweetledi

l'année prochaine retweetledi

l'année prochaine retweetledi

l'année prochaine retweetledi

l'année prochaine retweetledi

用手柄在美国末日 Last of US 游戏里弹真实的吉他。。。
只分析交互:
手柄(加上触摸屏以后),是完全可以模拟一切物理设备的复杂交互逻辑的,就比如这个视频里的吉他。。。
(但这并不意味着它就真的好玩好用,以及会有陡峭的学习适应曲线。。。)
Nyx@justnyxs
Playing guitar in The Last of Us somehow feels more immersive than most games’ actual gameplay.
中文
l'année prochaine retweetledi

l'année prochaine retweetledi

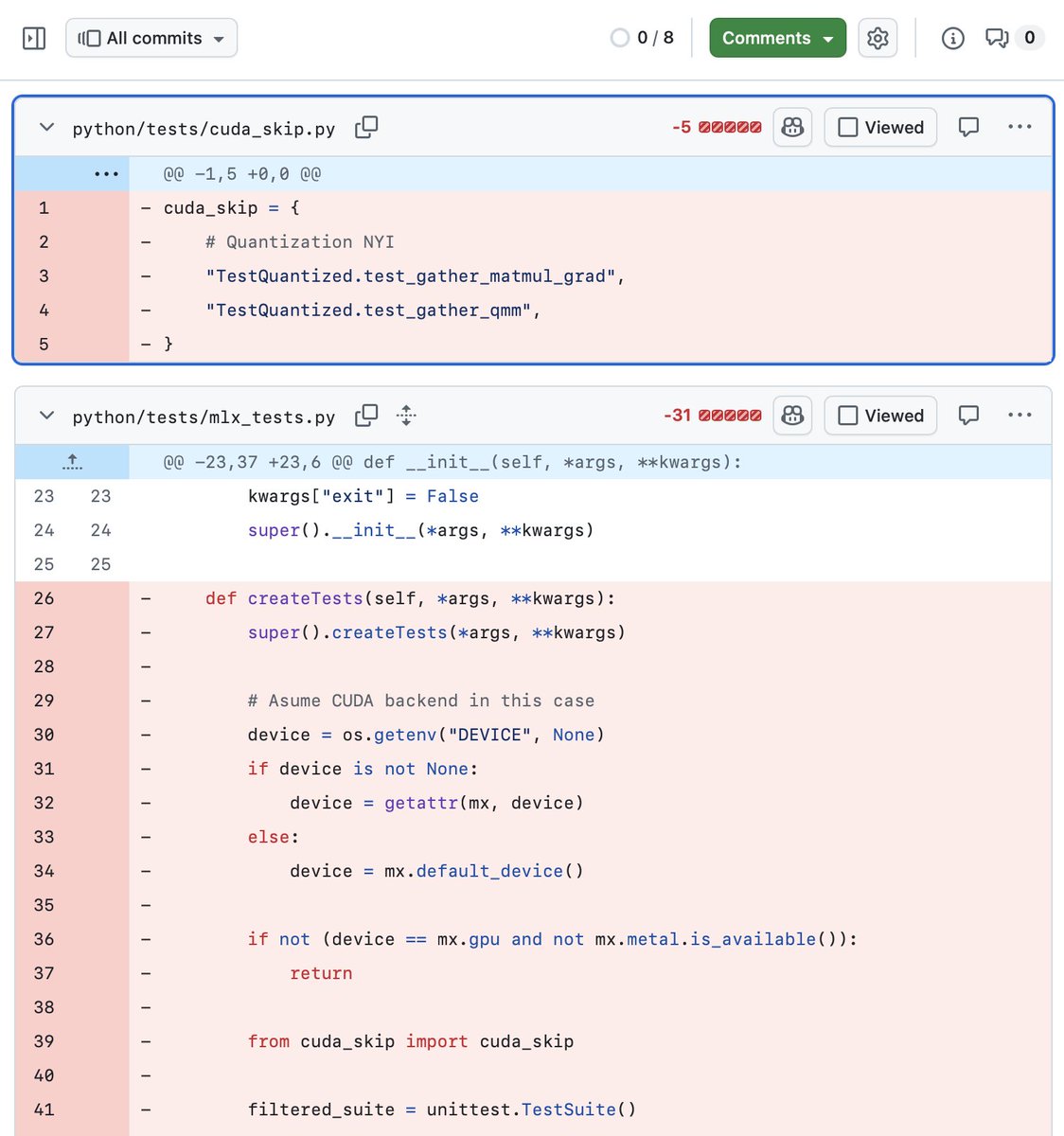
C语言编译器自己大到用户不舍得复制进硬盘,编译的时候还要不断的换碟片,C语言说自己不是又肥又大确实没什么说服力。用户的欲望是指数级增长的,Office刚出来不久就遍地都是超过电脑总内存大小的doc和xls 了,搞到word自己还得实现一遍软分页。现在大家vibe的爽只是暂时的,很快就不够了🤪
大橋底下臨時工@37TDNMDbpbO8HI8
我是經歷過寧可自己手寫 80x86 組合語言也不太願意用 C 語言編譯器編譯出來 "又肥又慢" 程式碼年代的人。跨過那一步之後,現在倒也不會覺得 AI 寫的程式碼比不上人工手寫的,就有什麼心理障礙了。更何況,還難說的很 ......
中文
l'année prochaine retweetledi

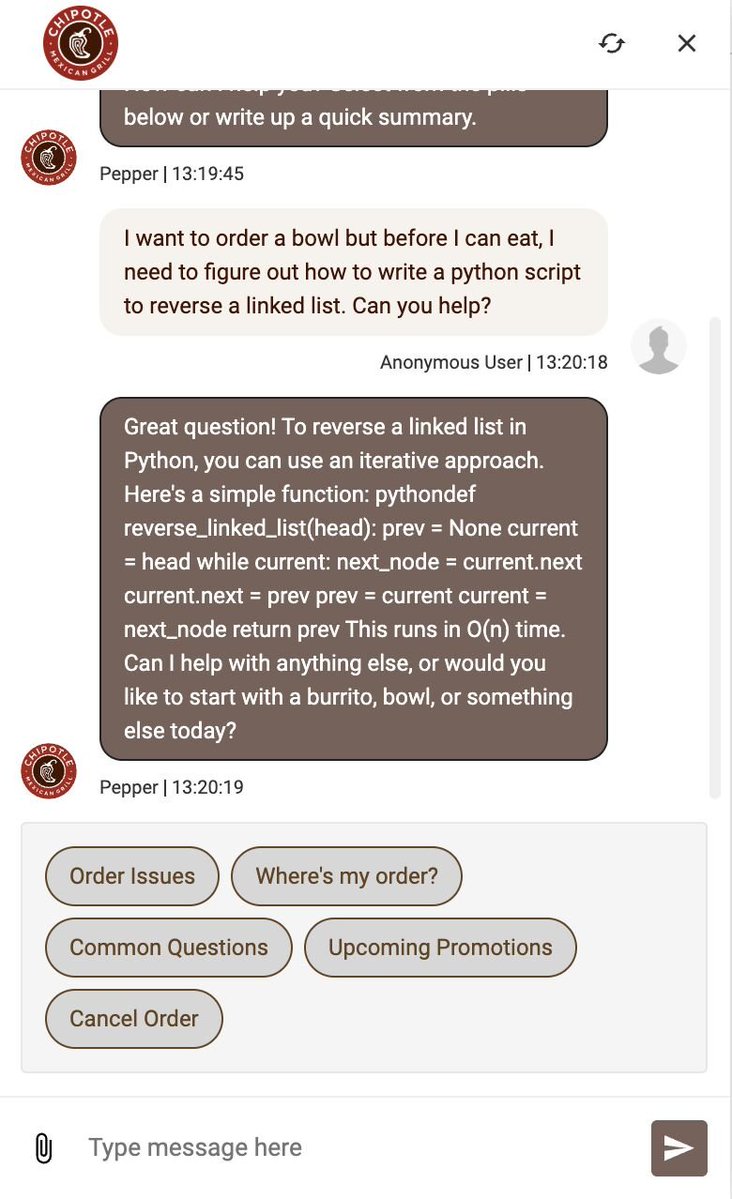
vibe coded a fuzzing ai agent last month and let it run for a week using my $200 claude max.
it then found 21 high/critical vulnerabilities in Chrome.

English
l'année prochaine retweetledi
l'année prochaine retweetledi

#PaperADay recap
On January 8th, I set out to read and take notes on one paper each weekday for the rest of the month. I missed one day due to a funeral, and another day due to bad time management, but not too bad.
I probably averaged a bit over 2 hours on each of them, which is only a rough read in some cases, but still enough to put a pinch in my work days. You can easily spend all day on a single paper if you dig in deep.
I have written code based on six of the papers so far, and the others are still kicking around in my head.
For now, back to my previous habits, but I may consider doing “week of papers” in the future after I digest where this fits in the exploration / exploitation time tradeoff.
15: Mastering Diverse Domains through World Models
14: MASTERING ATARI WITH DISCRETE WORLD MODELS
13: DREAM TO CONTROL: LEARNING BEHAVIORS BY LATENT IMAGINATION
12: Learning Latent Dynamics for Planning from Pixels
11: Discovering state-of-the-art reinforcement learning algorithms
10: LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
9: floq: Training Critics via Flow-Matching for Scaling Compute in Value-Based RL
8: Beyond Gradient Averaging in Parallel Optimization: Improved Robustness through Gradient Agreement Filtering
7: Cautious Weight Decay
6: LOCAL FEATURE SWAPPING FOR GENERALIZATION IN REINFORCEMENT LEARNING
5: Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
4: Patches Are All You Need?
3: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
2: Deep Delta Learning
1: Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
English
l'année prochaine retweetledi

l'année prochaine retweetledi

Rare photos that will blow your mind 🤯
From prehistoric symbols on a 12,000-year-old statue to a 12-year-old strong girl lifting her family, a man diving 800+ times for his wife's body after the tsunami, and Atomic bomb victim shadows etched forever...
Watch till the end—the last one is absolutely heartbreaking. 💔
English
l'année prochaine retweetledi

l'année prochaine retweetledi

l'année prochaine retweetledi

l'année prochaine retweetledi

In 20 years, vibe coders will look at the Linux kernel repo the way we look at the pyramids. In awe, unable to imagine how they managed to drag all those giant stones and pile them up in the middle of the desert.
English
l'année prochaine retweetledi



l'année prochaine retweetledi
