Isaac Villanueva retweetledi

Build a Large Language Model from scratch!
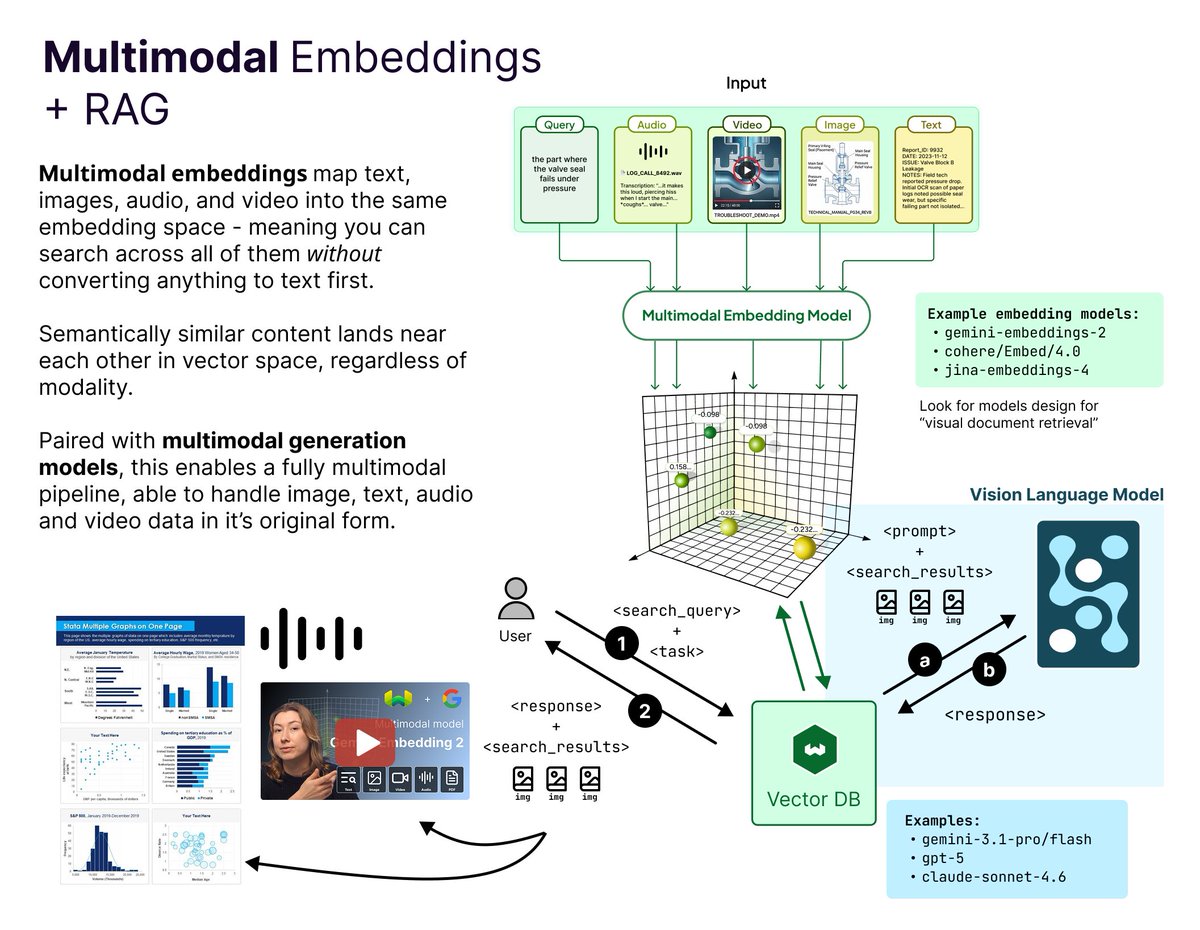
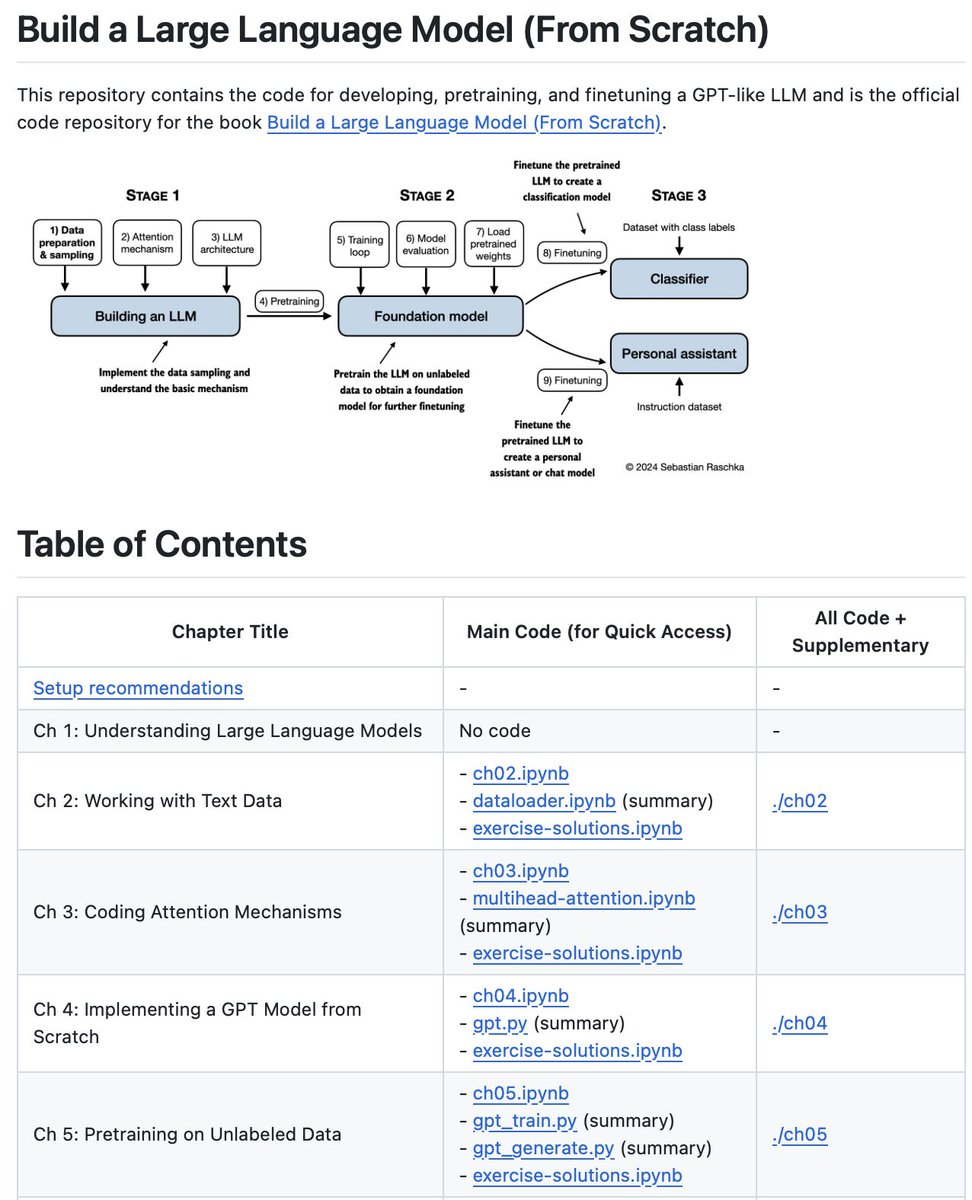
This repository contains the code examples for developing, pretraining, and finetuning a LLM from scratch.
It is the official codebase for the book Build a Large Language Model (From Scratch).
Notebook examples are included for each chapter:
Chapter 1: Understanding Large Language Models
Chapter 2: Working with Text Data
Chapter 3: Coding Attention Mechanisms
Chapter 4: Implementing a GPT Model from Scratch
Chapter 5: Pretraining on Unlabeled Data
Chapter 6: Finetuning for Text Classification
Chapter 7: Finetuning to Follow Instructions
Link to the repo in the comments!
English