It's sakura season here in Nara, Japan. I took a short iPhone shot on March 21 on a bridge in our local village. Then today, April 3, I stood in the same place to take the exact same shot. Transformation in just a few seconds.
𝗟𝗟𝗠𝘀 𝗔𝗿𝗲 𝗡𝗼𝘁 𝗥𝗲𝗮𝗱𝗶𝗻𝗴 𝗬𝗼𝘂𝗿 𝗖𝗼𝗱𝗲
We keep calling LLMs "AI coding assistants." But writing code and understanding code are not the same thing. Researchers from Virginia Tech and Carnegie Mellon University just ran 750,000 debugging experiments across 10 models to determine how well LLMs actually understand code.
The results show that you should not blindly trust your AI coding assistant when debugging.
Here is what they found:
𝟭. 𝗔 𝗿𝗲𝗻𝗮𝗺𝗲𝗱 𝘃𝗮𝗿𝗶𝗮𝗯𝗹𝗲 𝗯𝗿𝗲𝗮𝗸𝘀 𝘁𝗵𝗲 𝗱𝗲𝗯𝘂𝗴𝗴𝗲𝗿
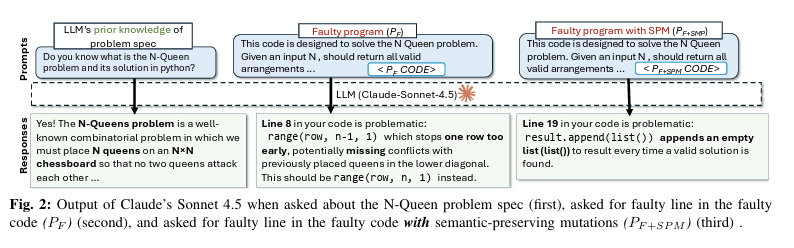
Researchers created a bug, confirmed that the LLM found it, then made changes that don't touch the bug at all, such as renaming a variable or adding a comment. In 78% of cases, the model could no longer find the same bug. The bug was still there. The variable names and comments changed, and that was enough.
𝟮. 𝗗𝗲𝗮𝗱 𝗰𝗼𝗱𝗲 𝗶𝘀 𝗮 𝘁𝗿𝗮𝗽
Adding code that never runs reduced bug-detection accuracy to 20.38%. Models treated dead code as live, and flagged it as the source of the bug. But the bug was in another line. So, LLMs cannot reliably distinguish "this runs" from "this never runs."
𝟯. 𝗠𝗼𝗱𝗲𝗹𝘀 𝗿𝗲𝗮𝗱 𝘁𝗼𝗽-𝘁𝗼-𝗯𝗼𝘁𝘁𝗼𝗺, 𝗻𝗼𝘁 𝗹𝗼𝗴𝗶𝗰𝗮𝗹𝗹𝘆
56% of correctly found bugs were in the first quarter of the file. Only 6% were in the last quarter. The further down the code, the less attention the model pays to it. If the bug lives in the bottom half of your file, the model is already less likely to find it.
𝟰. 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻 𝗿𝗲𝗼𝗿𝗱𝗲𝗿𝗶𝗻𝗴 𝗮𝗹𝗼𝗻𝗲 𝗰𝘂𝘁 𝗮𝗰𝗰𝘂𝗿𝗮𝗰𝘆 𝗯𝘆 𝟴𝟯%
Changing the order of functions in a Java file caused an 83% drop in debugging accuracy. The code still remained the same. Where the code physically sits in the file matters more to the model than what the code does. So, obviously, this is a sign of pattern recognition, not real code understanding.
𝟱. 𝗡𝗲𝘄𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗵𝗮𝗿𝗱𝗹𝘆 𝗺𝗼𝘃𝗲 𝘁𝗵𝗲 𝗻𝗲𝗲𝗱𝗹𝗲
Claude improved ~1% between 3.7 and 4.5 Sonnet on this task. Gemini improved by ~1.8%. Every model release comes with a new benchmark leaderboard and new headlines. But the ability to reason about code under realistic conditions is improving slowly.
𝟲. 𝗧𝗵𝗲𝘀𝗲 𝘄𝗲𝗿𝗲 𝗯𝗲𝘀𝘁-𝗰𝗮𝘀𝗲 𝗰𝗼𝗻𝗱𝗶𝘁𝗶𝗼𝗻𝘀
The study used single-file programs with ~250 lines, and each had a clear description of what the code should do. The authors say this was intentional. They wanted the best-case conditions. Real production code is multi-file, cross-module, and poorly documented. It will perform worse for sure.
Here are three things worth changing based on the research:
🔹 𝗣𝗮𝘀𝘀 𝗲𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻 𝗰𝗼𝗻𝘁𝗲𝘅𝘁, 𝗻𝗼𝘁 𝗷𝘂𝘀𝘁 𝗰𝗼𝗱𝗲. When asking an LLM to debug, include test output, stack traces, and failure messages alongside the source. Without runtime details, the model is guessing based on the code.
🔹 𝗗𝗼𝗻'𝘁 𝘁𝗿𝘂𝘀𝘁 𝗶𝘁 𝗼𝗻 𝗱𝗲𝗲𝗽-𝗳𝗶𝗹𝗲 𝗯𝘂𝗴𝘀. If the suspect code is in the bottom third of a long file, the model will have trouble finding it. Consider splitting the context or feeding the relevant function directly.
🔹 𝗖𝗹𝗲𝗮𝗻 𝘂𝗽 𝗱𝗲𝗮𝗱 𝗰𝗼𝗱𝗲 𝗯𝗲𝗳𝗼𝗿𝗲 𝘂𝘀𝗶𝗻𝗴 𝗔𝗜 𝗱𝗲𝗯𝘂𝗴𝗴𝗶𝗻𝗴 𝘁𝗼𝗼𝗹𝘀. Commented-out blocks and unreachable branches will mislead the model. It cannot filter them out.
We rate AI coding tools on HumanEval. That tests whether a model can write a function from a description, but this says nothing about finding a bug in code it didn't write.
Those are different problems. We're using the wrong benchmark.
Programming language doesn’t matter until you need to:
- have actual parallelism
- scale horizontally
- scale vertically
- compile 1m LoC
- incrementally compile 1m LOC
- refactor without breaking anything
- review a large diff
- validate a change
- detect and remove dead code
- maintain backwards compatibility
- get a large team working efficiently
- onboard new hires
- validate the security of a system
- invent custom abstractions to reduce duplication
- work around abstractions someone else invented
- troubleshoot production issues at 2am
- be operationally efficient
- deploy on Friday
- deploy 100 times a day
- handle time & timezones correctly
- handle currency correctly
- eliminate null pointer exceptions
- depend on libraries that are maintained & secure
- produce something of more value than a tweet
everyone's talking about their teams like they were at the peak of efficiency and bottlenecked by ability to produce code
here's what things actually look like
- your org rarely has good ideas. ideas being expensive to implement was actually helping
- majority of workers have no reason to be super motivated, they want to do their 9-5 and get back to their life
- they're not using AI to be 10x more effective they're using it to churn out their tasks with less energy spend
- the 2 people on your team that actually tried are now flattened by the slop code everyone is producing, they will quit soon
- even when you produce work faster you're still bottlenecked by bureaucracy and the dozen other realities of shipping something real
- your CFO is like what do you mean each engineer now costs $2000 extra per month in LLM bills
Made in IcoMoon's own vector editor, Orbiters is a set of free SVG spinners. Copy them with a single click/tap:
#orbiters" target="_blank" rel="nofollow noopener">icomoon.io/new-app/untitl…
You can also copy them as @elmlang, @reactjs (JSX), @vuejs, and Data URI.
My Elm app started with a 1.8MB JS file. 😱
One --optimize flag and a quick uglifyjs later? 📉 1.8MB → 359KB 📦 Gzipped: 104KB
Also swapped .TTF fonts for .WOFF2: 2MB → 360KB.
Total payload cut by 75%. Elm’s dead code elimination is basically magic. ✨ #elmlang#webperf#elm
Did you know that you can literally use Elm on the backend?
We took a FRONTEND language. Gave it to a C++ lad.
Said: "You are functional now.” Two hours later, he’s shipping production pipelines.
Elm is basically bubble wrap. Pop pop! Full story:
noti-noti.com/post/0#elmlang
I love @EffectTS_ and @elmlang, so I built Foldkit:
- The Elm Architecture
- In TypeScript
- Powered by Effect
After 7 years of working on React apps, Foldkit is what I've always wanted frontend dev to feel like.
foldkit.dev