Sabitlenmiş Tweet

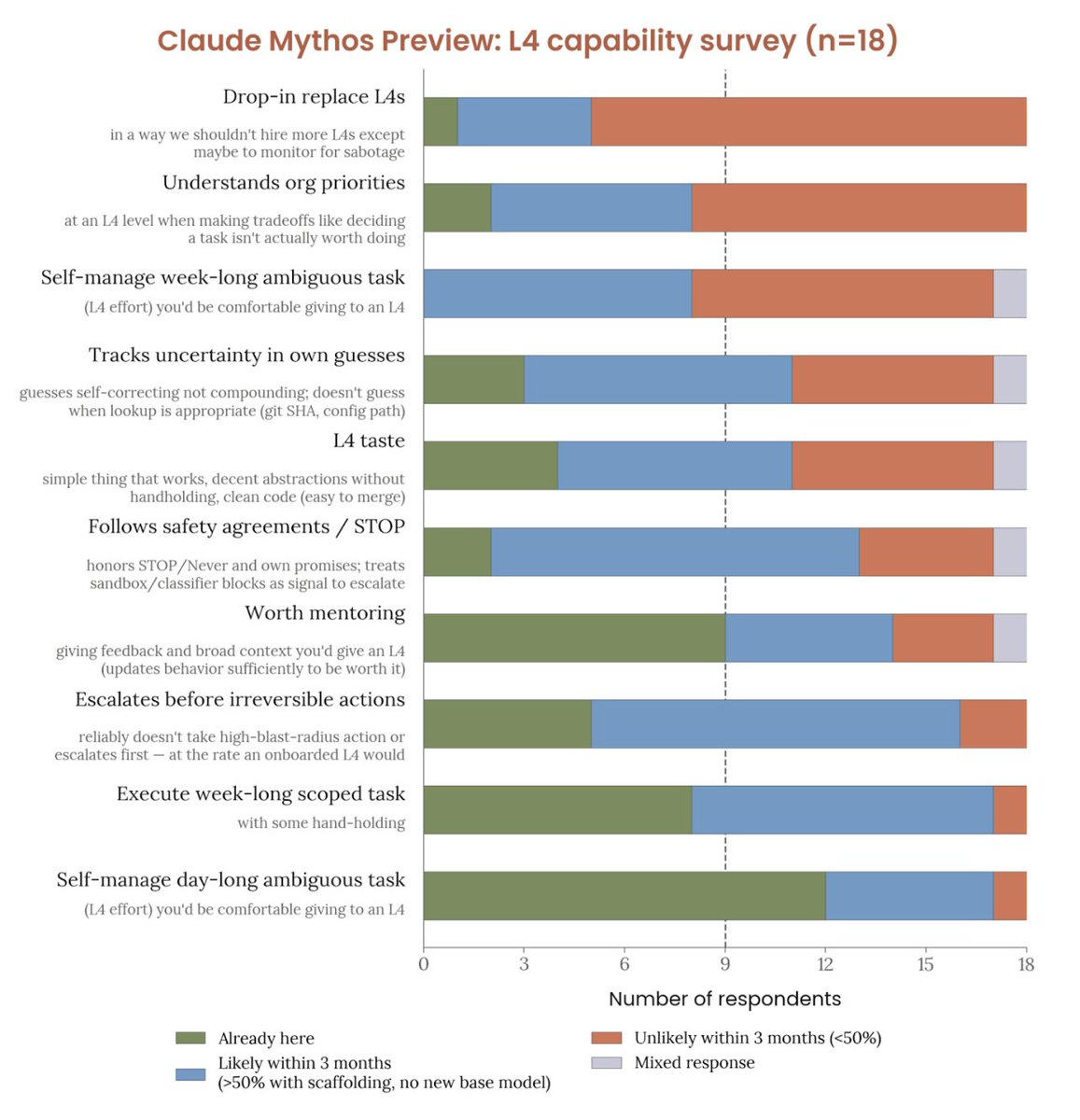
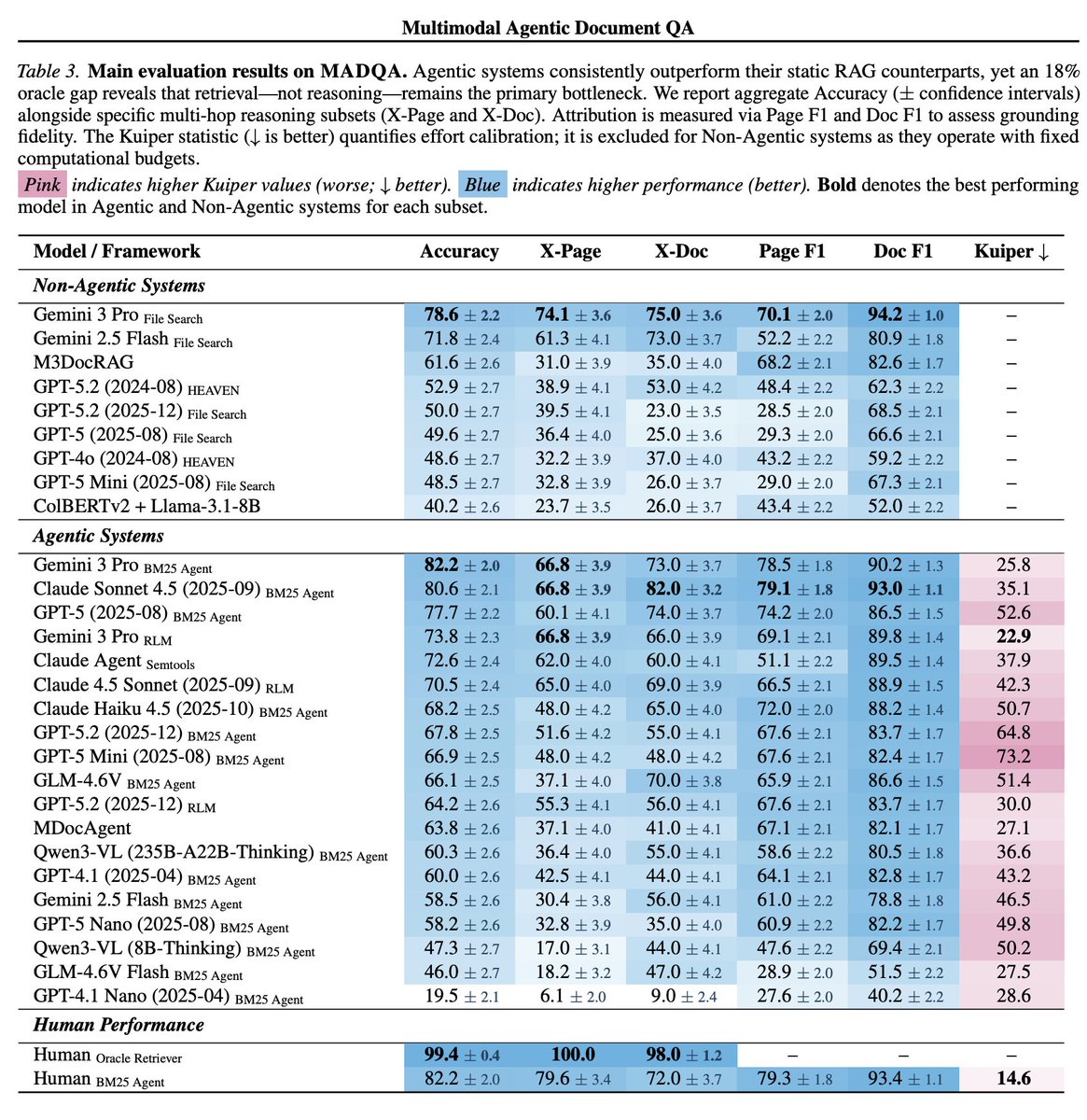
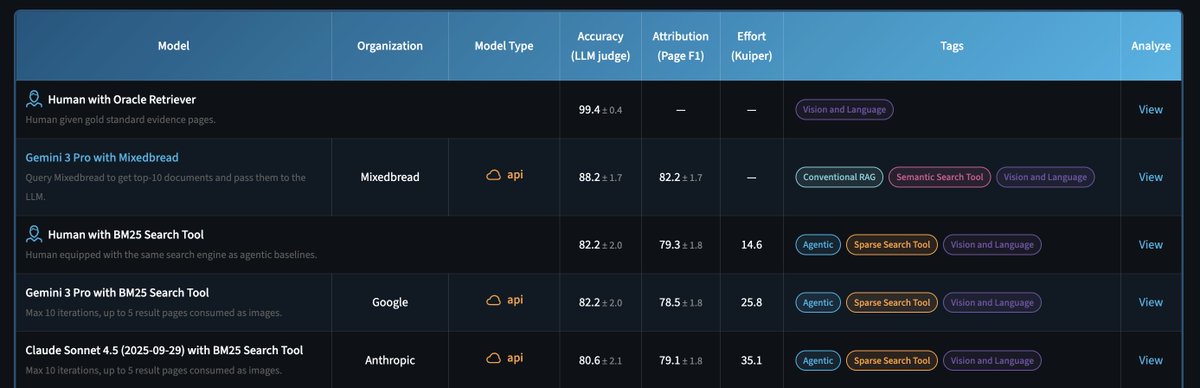
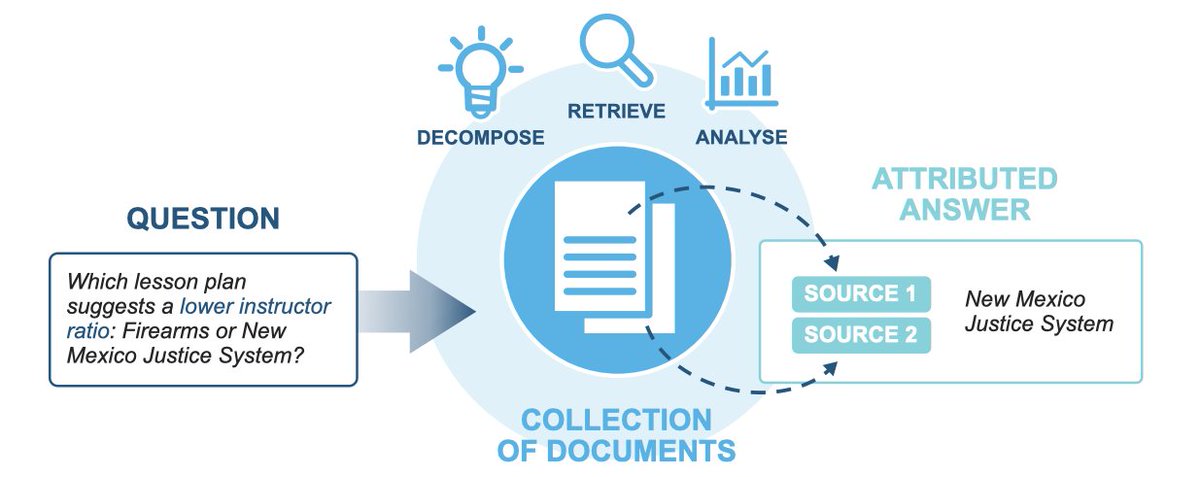
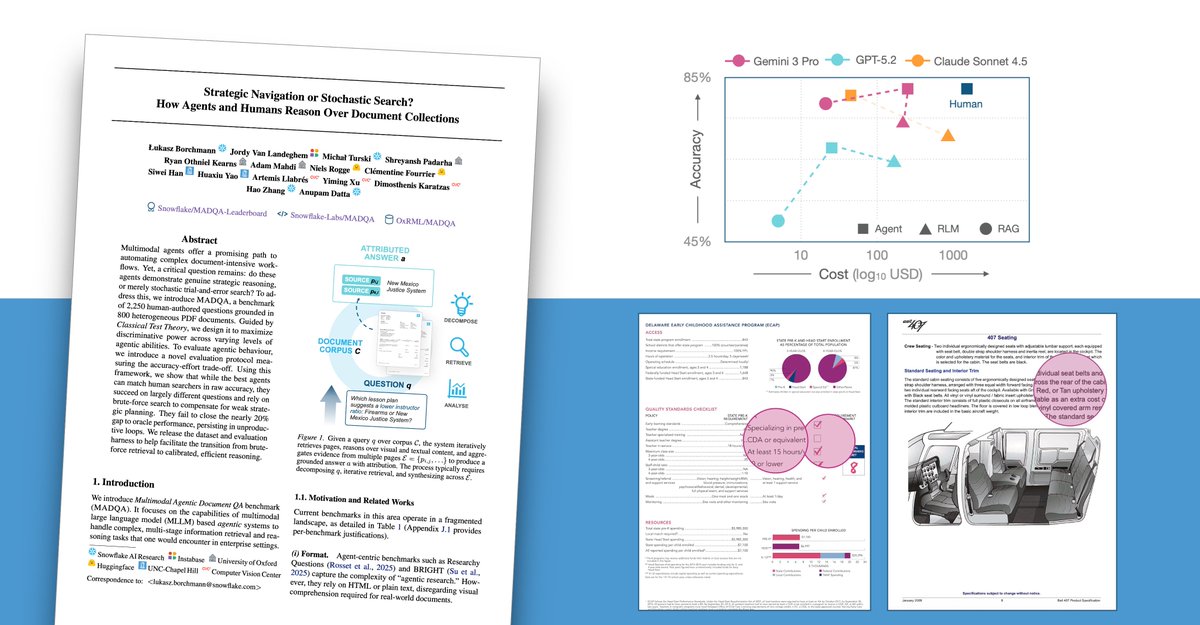
1/10 Are agents navigating enterprise data strategically, or just stumbling until they get lucky?
To answer this, we introduce MADQA, which benchmarks not just final answers but also search trajectories. A collab with @UniofOxford, @UNC, and @huggingface. 🧵
English