notpink retweetledi

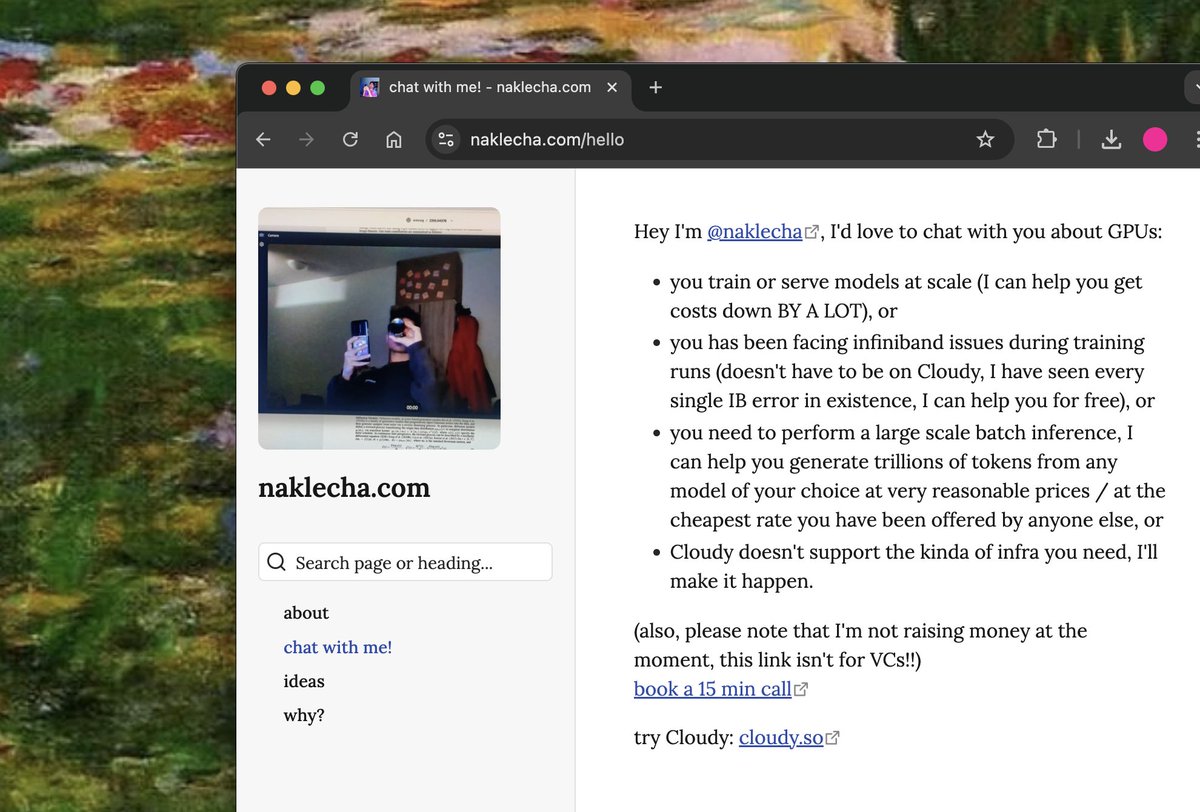
i updated my personal website: naklecha.com. tldr; if you work with gpus, i want to chat with you :)
English
notpink
1.1K posts


introducing simple-llm: a ~950 line, powerful & extensible inference engine that performs on par with vllm. enjoy :) performance (gpt-oss-120b, on an h100): - batch=1: 135 tok/s (vllm: 138) - batch=64: 4,041 tok/s (vllm: 3,846) github.com/naklecha/simpl…

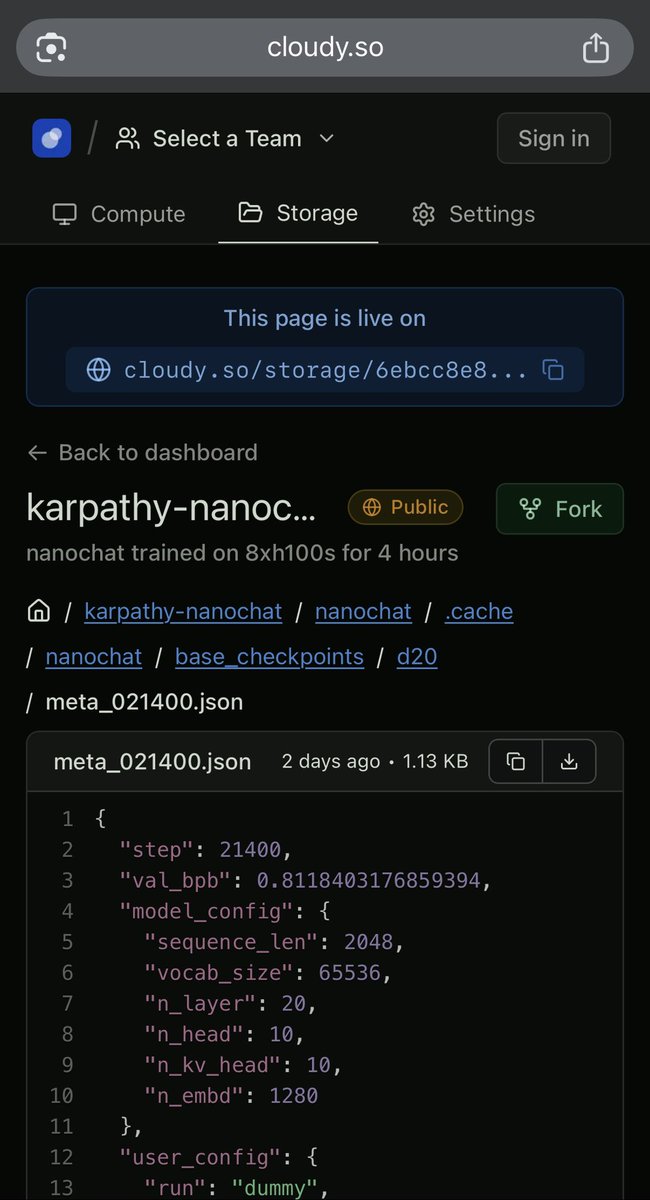
Introducing "public volumes" on Cloudy - with this update, open-source projects can share as reproducible sandboxes that can be forked and mounted on GPU instances within seconds. Share, fork & mount 100TB+ sandboxes seamlessly with Cloudy. Here is a demo:
deep down, you know exactly what needs to be done this hour, this day, this year, this decade, this life. do it!
exactly 3 months ago, i quit my job to build cloudy. reflecting so far, it's the best decision i ever made & i'm confident that, one day (soon), cloudy will be the best gpu infrastructure product in the world!! ty for all the love & support so far <3












