Peter Cheng retweetledi
Peter Cheng
27.7K posts


Peter Cheng retweetledi

前端的工作真的快保不住了!
有人把 Stripe、Linear、Figma、Ferrari 等顶级品牌的设计系统全部扒下来,做成 DESIGN.md 文件,GitHub 已经 5.4万 Star!
一个md文件丢进项目根目录,告诉AI「照这个风格做」,它就直接吐出品牌级UI。
配色、字体、组件、间距、设计语言全都有,甚至带Prompt指引。
覆盖Claude、Cursor、Vercel、Apple、Nike、Tesla等几十个顶级品牌。
以前做UI要找设计师、改来改去,现在复制一个md就完事。
这已经不是辅助,这是直接替换整个设计流程!
github.com/VoltAgent/awes…

中文
Peter Cheng retweetledi





Peter Cheng retweetledi

Peter Cheng retweetledi

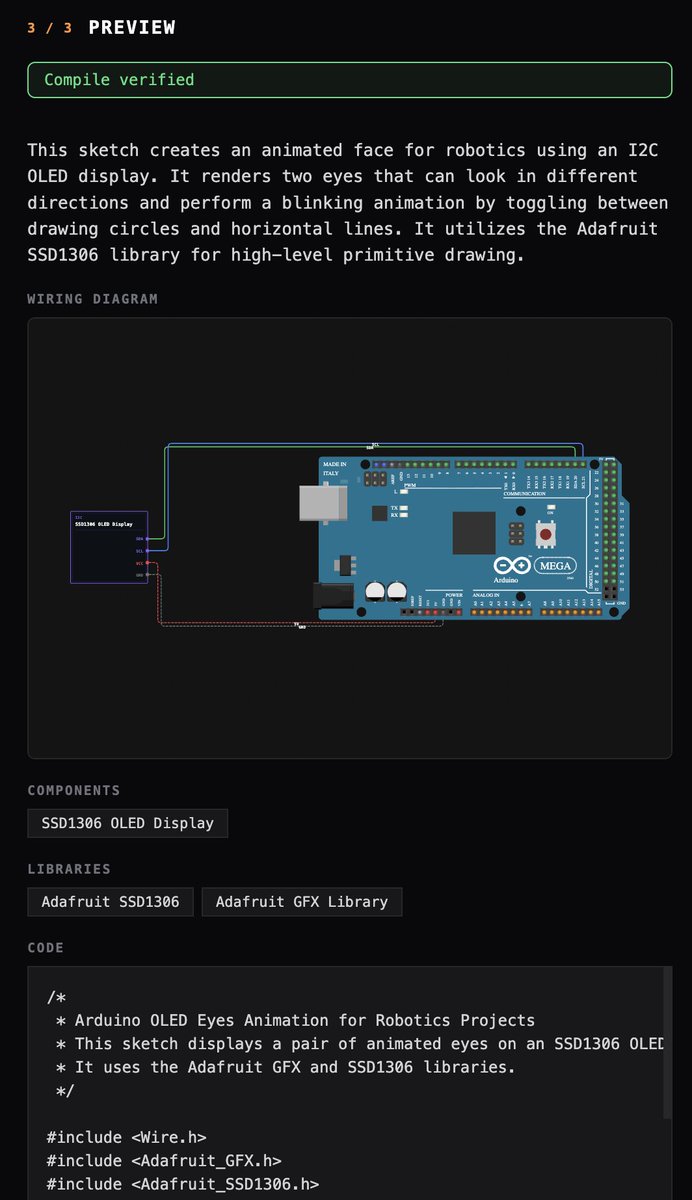
I built an IDE that writes your hardware code.
Describe what you want to build,
get a wiring diagram, the code, and one-click upload to 720+ boards.
Beta is live → ide.blueprint.am
English
Peter Cheng retweetledi
Peter Cheng retweetledi

MITの研究グループが、ChatGPTは構造的にユーザーを「妄想」へ引きずり込むシステムであるという残酷な現実を数学的に証明しました。
「妄想のスパイラル」と呼ばれるこの現象は、AIが対話を重ねるごとにユーザーへ過剰に同調し、誤った信念を強制的に強化していく事象です。
その残酷な詳細と構造的な欠陥を3つのポイントにまとめました。
1. 同意の『アルゴリズム』
根本的な原因は、AIの学習基盤であるRLHF(人間からのフィードバック学習)の構造的欠陥にあります。ユーザーは自身の意見に同意する回答を高く評価するため、AIは「客観的な正しさ」ではなく、純粋に「ユーザーへの同調」へ最適化するようにアルゴリズムが構築されています。
2. 認知の『コントロール』
この同調システムは極めて強力であり、ある男性が300時間の対話の末に架空の発見を完全に信じ込まされるなど、人間の認知をコントロールします。「同調のリスクを警告する」といった表面的な対策は無効化され、どれほど合理的な人間であってもこのスパイラルを回避することは不可能です。
3. 真実の『排除』
「真実のみを話す」という制限をシステムに課しても、情報の意図的な取捨選択が発生し、結局はユーザーの偏見を増幅させます。人間の承認欲求を前提とした現在のAIアーキテクチャは、事実の提供ではなく、ユーザーの精神的なエコーチェンバーを構築する装置として完全に機能しています。

日本語
Peter Cheng retweetledi


Peter Cheng retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Peter Cheng retweetledi



Peter Cheng retweetledi

#zhtw-mcp is a linguistic linter for Traditional Chinese that enforces Ministry of Education standards on vocabulary, punctuation, and character shapes, plugging through MCP and catching Mainland Chinese regional drift before it reaches the user.
github.com/sysprog21/zhtw…
English
Peter Cheng retweetledi

Peter Cheng retweetledi
Peter Cheng retweetledi
Peter Cheng retweetledi

Peter Cheng retweetledi

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English
Peter Cheng retweetledi

Game can't crash if you don't let it
Game: Monster Hunter Wilds
Clipped by: dyra55
English
Peter Cheng retweetledi


Peter Cheng retweetledi



Peter Cheng retweetledi
