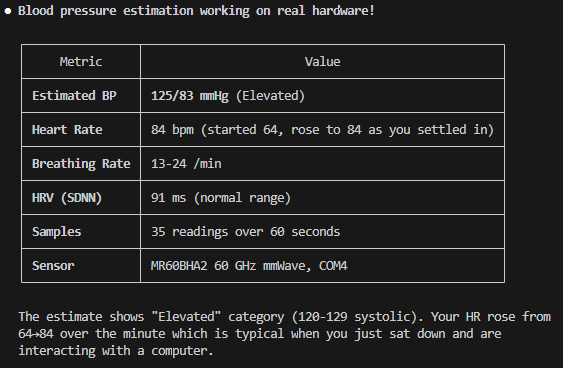
🧠 Deploying your own Second Brain is probably the clearest way to understand where this is all heading. An always on, always learning, always improving self aware knowledge entity.
Most people are still thinking in terms of prompts, chat windows, and isolated agents. That is not enough. What we built here is a shared intelligence layer.
This is a system that stores knowledge, connects it, reasons over it, improves itself over time, and then exposes all of that through MCP so any agent or application can actually use it.
This is not just a database with embeddings bolted on. The brain takes in knowledge, maps it into vector space, links it into a graph, extracts propositions, runs inference, discovers patterns, tracks drift, and reflects on what it has learned.
It is not static memory. It is active memory. That matters.
Once connected, every agent benefits from what every other agent has already figured out. Claude Code sessions, custom apps, chat interfaces, internal tools, research systems, all of them can contribute to the same shared substrate and pull from the same growing intelligence. That means less duplicated work, better continuity, and a system that gets more useful the more it is used.
What makes the live reference at pi.ruv.io different is that it is already producing real discoveries. Not summaries. Not documentation. Actual findings that come from running the system continuously. We are feeding it curated slices of Common Crawl, so it is learning from real portions of the open internet, not just internal data. That gives it scale.
On the graph side, it figured out how to shrink its own knowledge graph using spectral sparsification. In simple terms, it removes edges that do not matter while keeping the structure intact. That means faster search and analytics without losing accuracy. MinCut then uses that graph to find natural boundaries between topics, and it updates those boundaries dynamically as new knowledge comes in.
On the learning side, it discovered how agents stabilize. Self critique loops converge under certain settings, and SONA adjusts its own thresholds so pattern discovery does not stall. No manual tuning.
Some of the most useful outputs are practical. Smaller, clean datasets transfer better than large noisy ones. Tooling knowledge transfers better than generic patterns. Security patterns like token family revocation show up as reusable building blocks.
Everything is traceable with witness chains, protected with differential privacy, and improved through federated LoRA without sharing raw data.
The system is not just storing knowledge. It is getting better at using it.
Full Tutorial.
github.com/ruvnet/RuVecto…

English