Sakana AI@SakanaAILabs
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: nature.com/articles/s4158…
Blog: sakana.ai/ai-scientist-n…
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
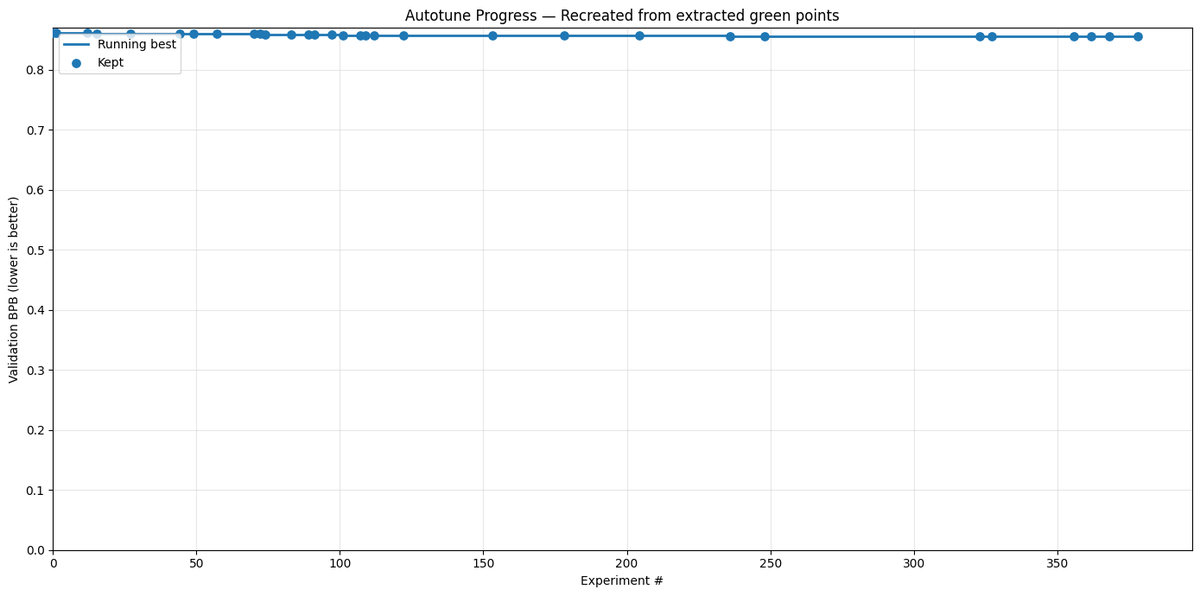
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (github.com/SakanaAI/AI-Sc…), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_ @cong_ml @RobertTLange @_yutaroyamada @shengranhu @j_foerst @hardmaru @jeffclune