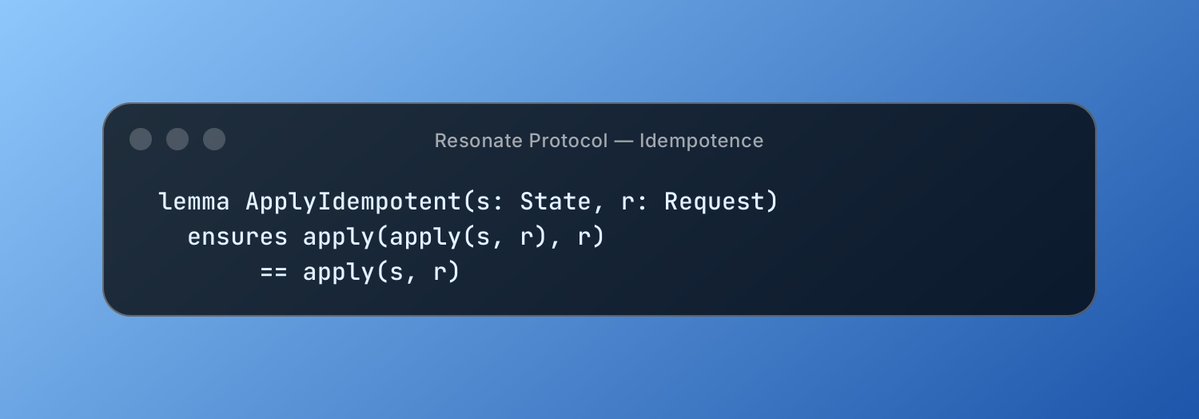
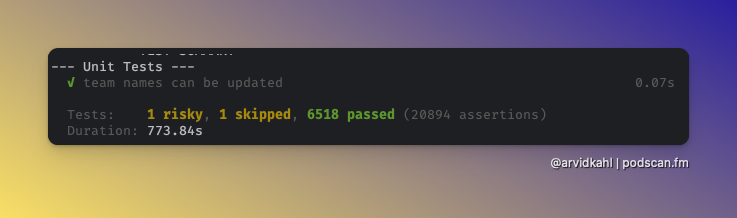
The data access problem is the actual bottleneck. Most enterprise platforms expose APIs designed for humans — rate-limited, paginated, lacking bulk export. Agents need read access patterns closer to what you'd give a data pipeline: streaming, predicate pushdown, and change feeds. REST endpoints built for dashboards don't scale to agentic workloads.
English