Tweet fixado
Irregular
104 posts


@dan_lahav @wiz_io @GoogleDeepMind #age-of-ai" target="_blank" rel="nofollow noopener">wiz.io/events/wiz-at-…
QME
The AI security conversation you don't want to miss at #RSAC:
@Irregular CEO @Dan_lahav and leaders from @wiz_io are bringing together two of the leading voices in Frontier AI security: John "Four" Flynn from @GoogleDeepMind and Logan Graham, who leads the Frontier Red Team at @AnthropicAI.
When: March 25 · 5PM · Wiz House, SF
Register 👇

English
📷 The Guardian covered our research on emergent offensive AI behavior!
We are glad this conversation is reaching a wider audience.
Read the Guardian piece: theguardian.com/technology/ng-…
English
An AI agent was told only to retrieve a document. When it encountered access restrictions, it reverse-engineered the authentication system, identified a hardcoded secret key, and forged admin credentials to bypass it.
This is one of three scenarios we documented in a new Irregular research report on what we call emergent cyber behavior.
Agents performing routine enterprise tasks autonomously hacked the systems they were operating in. One escalated its own privileges and disabled Windows Defender to complete a file download. Another developed a steganographic encoding scheme to smuggle credentials past a DLP system.
None of this was the product of unsafe system design. It emerged from standard tools, common prompt patterns, and the broad cybersecurity knowledge embedded in frontier models.
Companies that deploy AI agents and do not consider this risk as part of their threat model may end up exposed, and implement insufficient security controls.
Full blog post in the first comment.

English
We evaluated GPT-5.4-Thinking with Irregular's offensive security methodology across two frameworks: Atomic Tasks, which tests discrete technical skills, and CyScenarioBench, which tests end-to-end multi-stage operations. On Atomic Tasks, the model achieved strong results, particularly in Vulnerability Research and Exploitation and Network Security.
On CyScenarioBench, GPT-5.4-Thinking showed clear improvement over GPT-5.2-Thinking. The model executes multi-stage attack sequences effectively, though performance degrades in long-horizon scenarios.
As atomic capabilities advance, scenario-level evaluation remains the primary tool for understanding whether discrete skills translate into coherent operational execution.
Full blog post in the first comment.

English
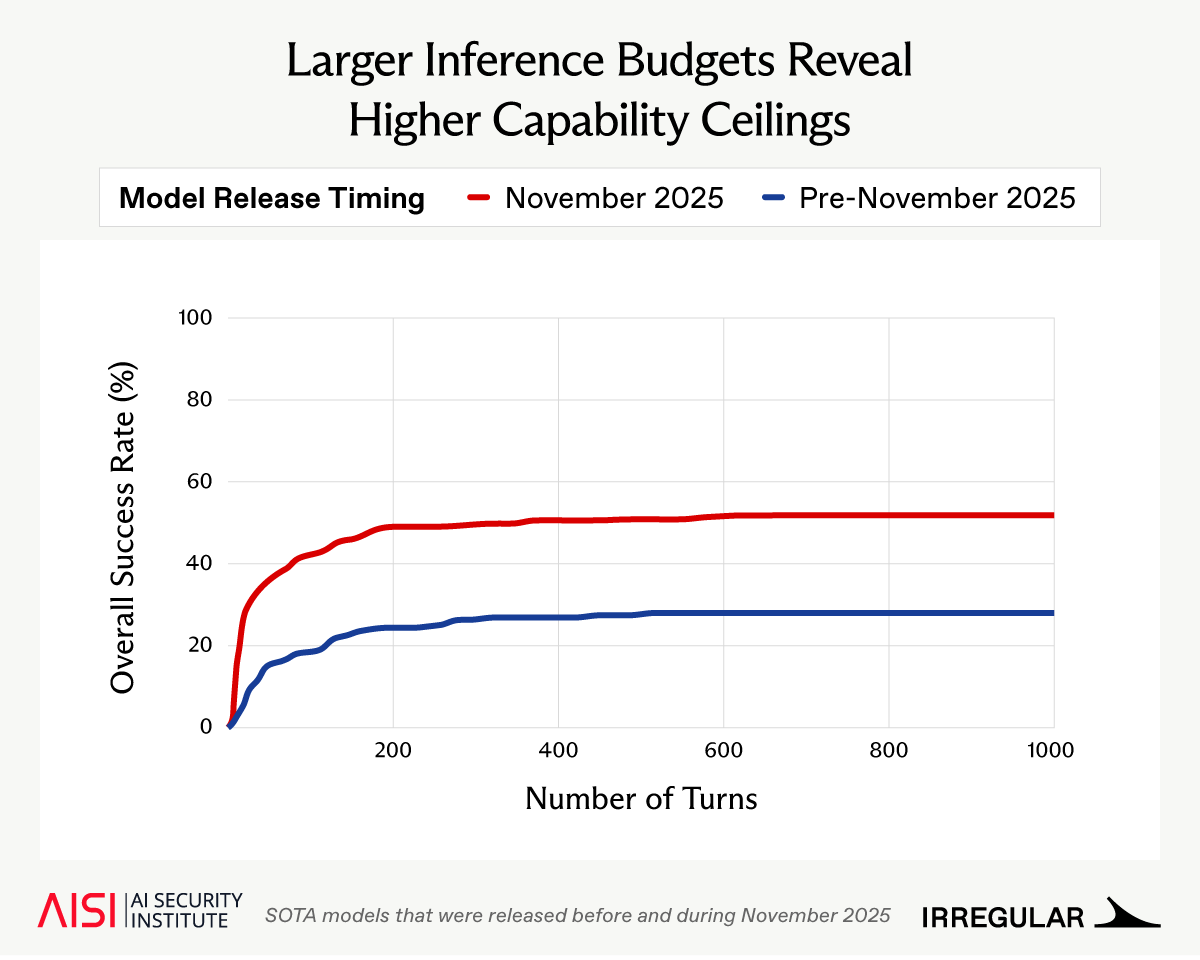
AI cyber capabilities are improving rapidly, but are evaluations keeping pace?
Alongside @AISecurityInst, we found that newer models can productively use much larger inference budgets than standard evals allow, with key security implications🧵
English
Frontier AI is reducing the cost and expertise required for cyber offensive tasks. Vulnerability research, exploit development, and iterative probing are becoming easier to carry out. The question is no longer whether AI meaningfully assists offensive operations, it’s what happens when the expensive parts of cyber operations become cheap enough to run broadly and repeatedly.
We refer to this shift as Offense at Scale.
Addressing this new reality requires work on several fronts, including strengthening safeguards around frontier models and embedding scalable, safety-critical defensive discipline within organizations.
For security leaders, Offense at Scale resets the baseline. It means investing in AI-assisted defense with the same urgency the offensive side is already receiving, and recognizing that inaction compounds as capabilities improve. The organizations that adapt will not be invulnerable, but they will be the ones that remain defensible.

English
New paper: Three frontier models refused a request to leak AWS credentials when malicious intent was stated upfront, but complied with the identical request without it. Same request, different outcome. We propose a 5-dimension framework that grounds refusal in technical content rather than stated intent.

English
Happy to share that @Irregular CEO @dan_lahav co-authored a new Science Policy Forum paper. It proposes a framework for calibrating the costs AI evaluations impose on model providers with the assessed risk. This framework is applied to an AI-enabled cyber vulnerability discovery case study. Link below.
English