@TheAhmadOsman What about gen 4 gpus on gen 5 slots? I have installed 2x 3090ti on 2x Gen 5 slots with x8x8 bifurcation.
English
majabbar
5.5K posts

@MindLedger
Realist, AI Augumented Human..... 🤔


Anthropic now blocks first-party harness use too 👀 claude -p --append-system-prompt 'A personal assistant running inside OpenClaw.' 'is clawd here?' → 400 Third-party apps now draw from your extra usage, not your plan limits. So yeah: bring your own coin 🪙🦞

@AnthropicAI So you guys like open-weights too? Any plans to release an opensource model for the community?



@TheAhmadOsman should we secure GPUs or is a Mac Studio 512gb enough?

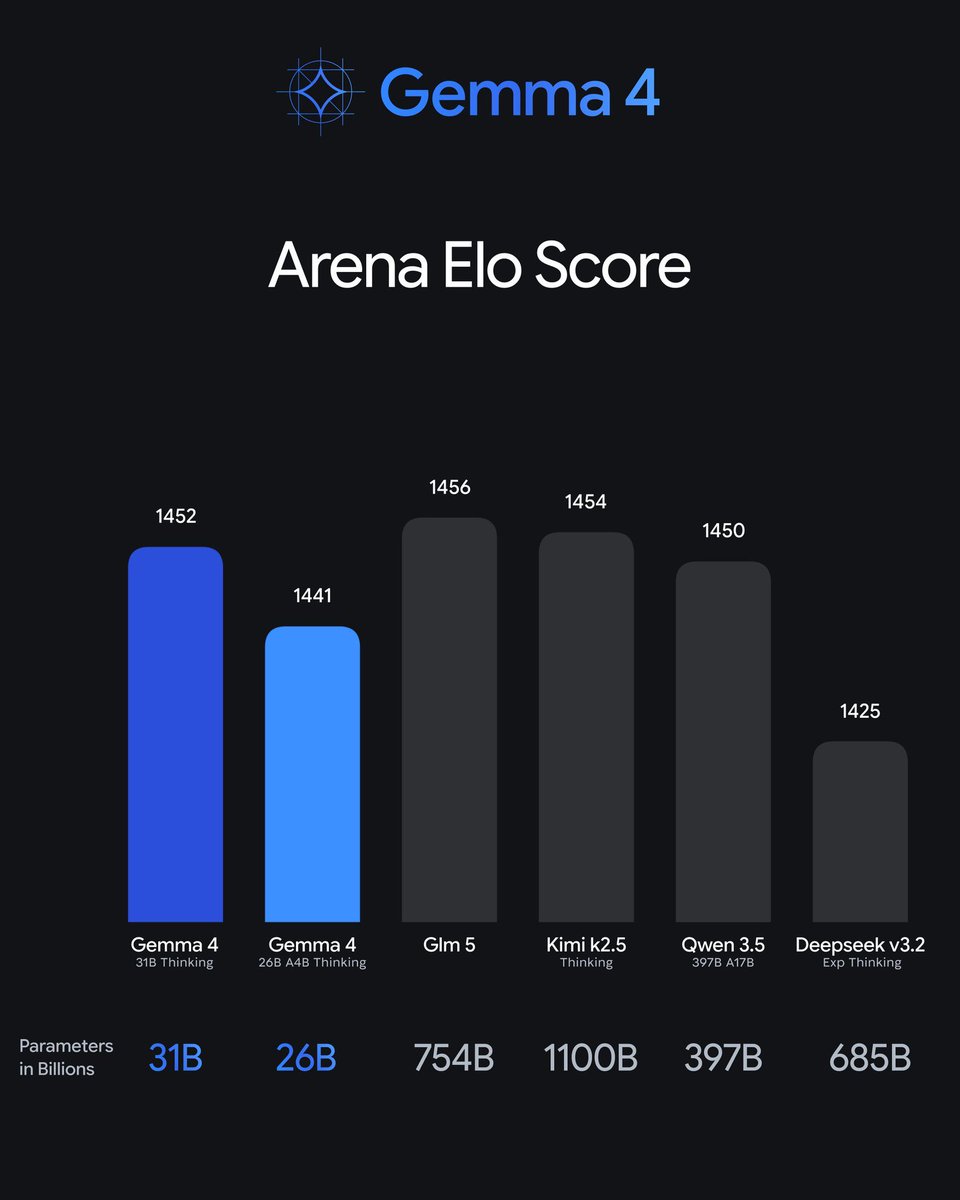
i still believe in dense models

Today we're excited to announce NO_FLICKER mode for Claude Code in the terminal It uses an experimental new renderer that we're excited about. The renderer is early and has tradeoffs, but already we've found that most internal users prefer it over the old renderer. It also supports mouse events (yes, in a terminal). Try it: CLAUDE_CODE_NO_FLICKER=1 claude
If you have a Thunderbolt or USB4 eGPU and a Mac, today is the day you've been waiting for! Apple finally approved our driver for both AMD and NVIDIA. It's so easy to install now a Qwen could do it, then it can run that Qwen...
LOL Anthropic sent me a DMCA for my fork of anon-kode