
🔗 Gateways
🌐 Web: sjtu-deng-lab.github.io/LightningRL
📄 Paper: sjtu-deng-lab.github.io/LightningRL/pa… (arXiv soon)
💻 Code: github.com/SJTU-DENG-Lab/…
🤗 Models: huggingface.co/collections/SJ…
English
DENG Lab @ SJTU
73 posts

@SJTUDengLab
https://t.co/kWvEXvQgXu
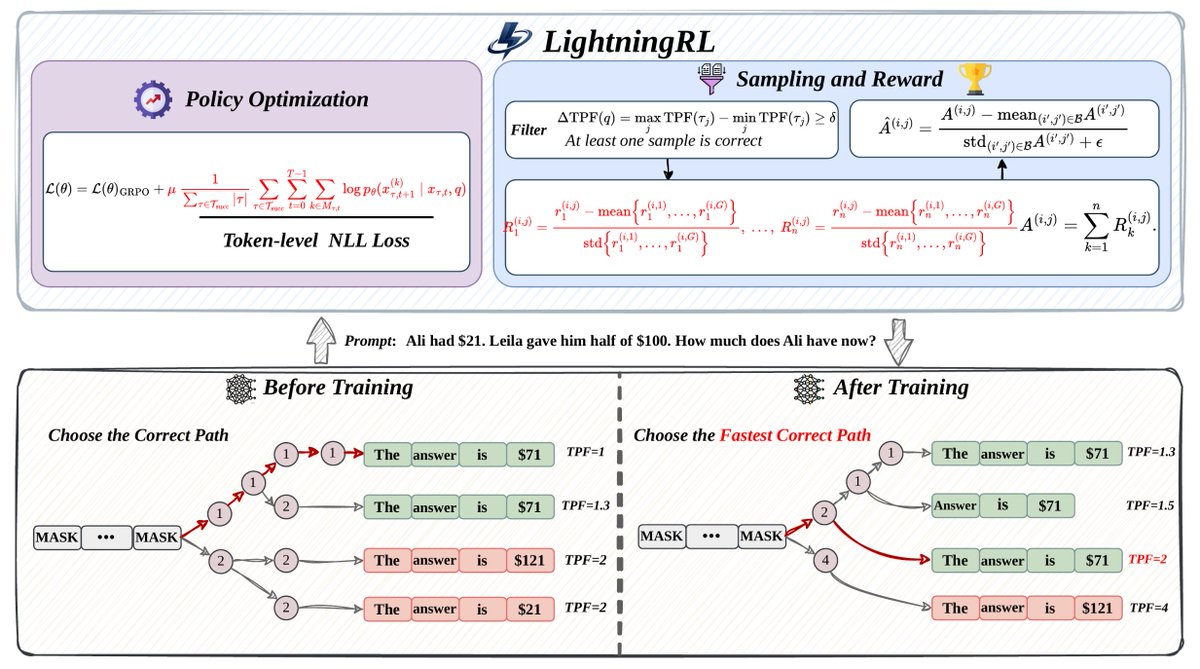
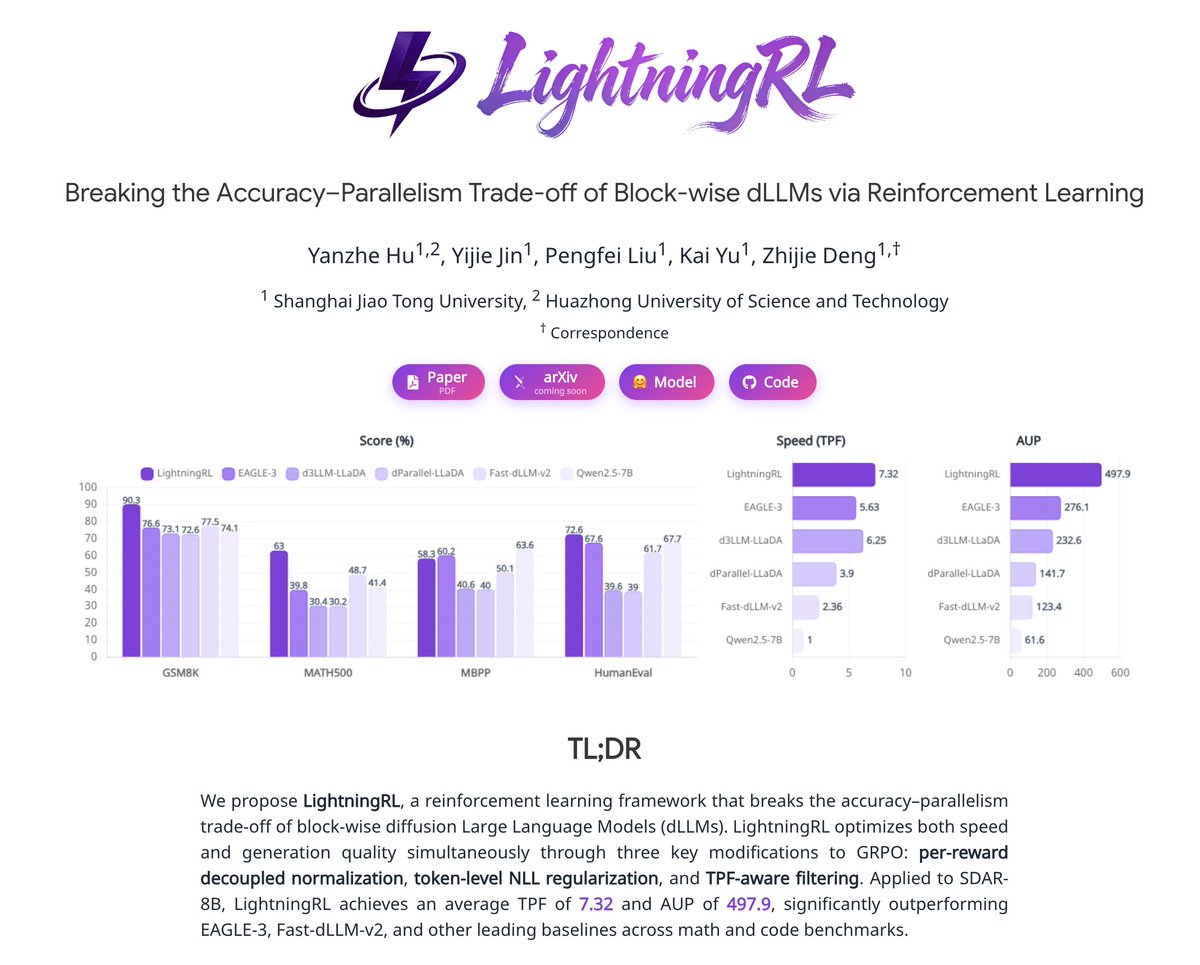








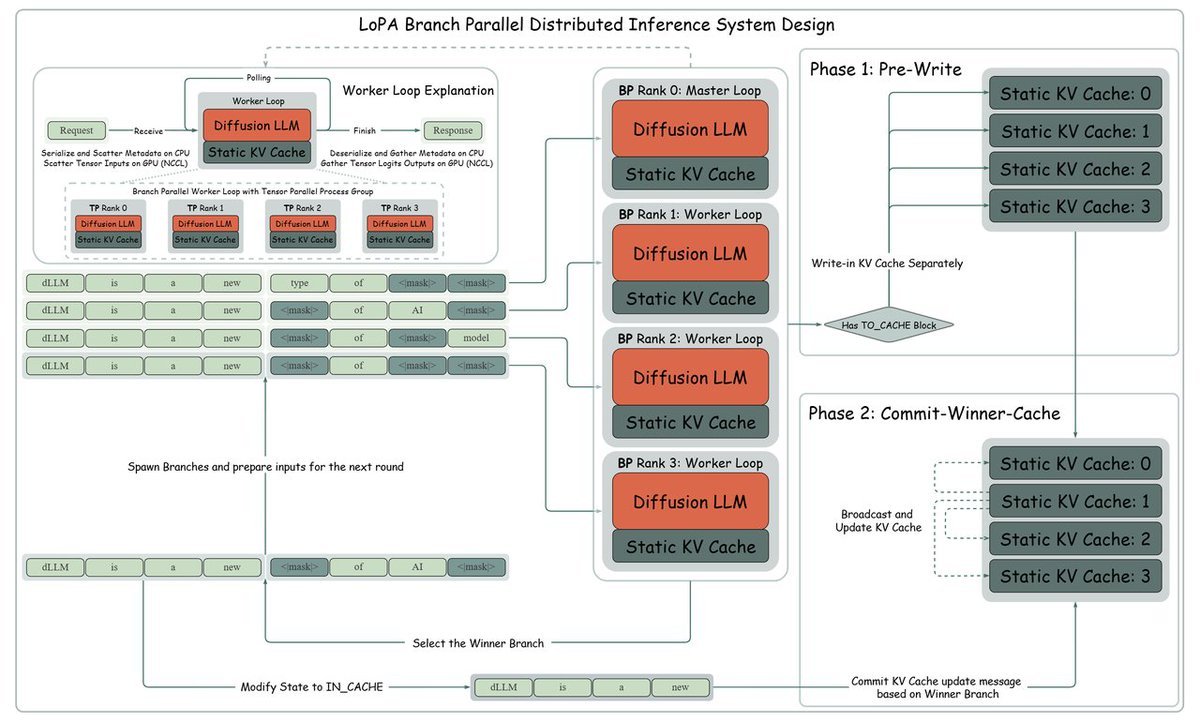



Jacobi Forcing: training AR models as diffusion-style parallel decoders with 4x speedup while staying causal and maintaining high generation quality. 🚀🎯 Autoregressive (AR) LLM and diffusion LLMs each have their own strengths. We analyze each method's pros and cons and ask the question: can we get the best of both worlds by turning an AR model into a causal, native parallel decoder? Our answer is YES. 👉 Read the full story here: hao-ai-lab.github.io/blogs/jacobi-f…

Jacobi Forcing: training AR models as diffusion-style parallel decoders with 4x speedup while staying causal and maintaining high generation quality. 🚀🎯 Autoregressive (AR) LLM and diffusion LLMs each have their own strengths. We analyze each method's pros and cons and ask the question: can we get the best of both worlds by turning an AR model into a causal, native parallel decoder? Our answer is YES. 👉 Read the full story here: hao-ai-lab.github.io/blogs/jacobi-f…