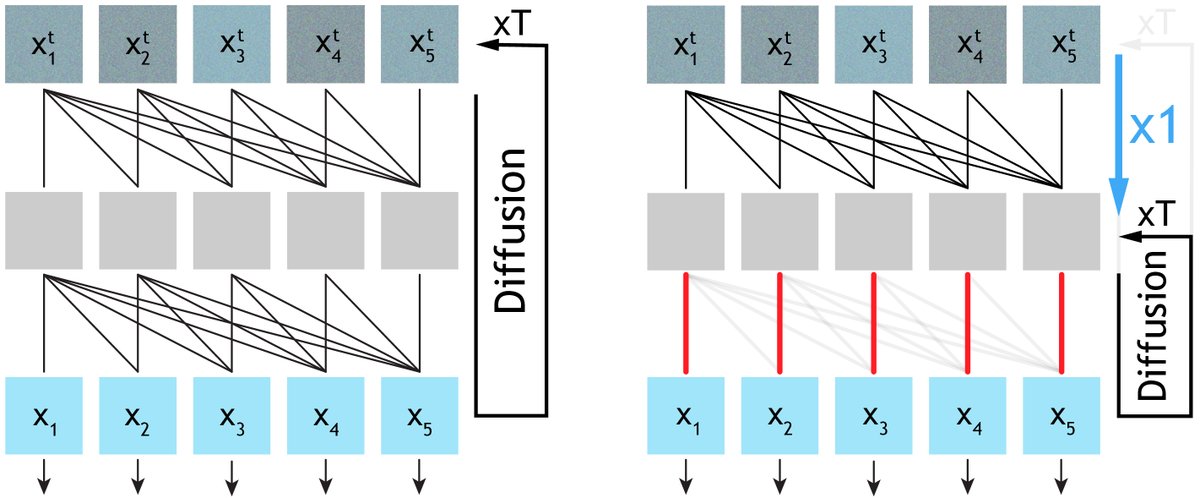
In our formulation, image tokenization and latent generation become two sides of the same coin. One model, one stage, from scratch—no pretrained encoders needed.
Especially excited about applying UNITE to modalities like molecules and crystals, where a pretrained DINO simply doesn't exist.
Very unforgettable collaboration with @ShivamDuggal4 and our amazing team at Adobe Research!
Shivam Duggal@ShivamDuggal4
Tokenization & Generation power Large Models. But are they really separate? Tokenization=Generation under strong observability UNITE: An end-to-end training framework where one shared Generative Encoder (GE) performs both token. & latent denoising Paper: arxiv.org/abs/2603.22283
English