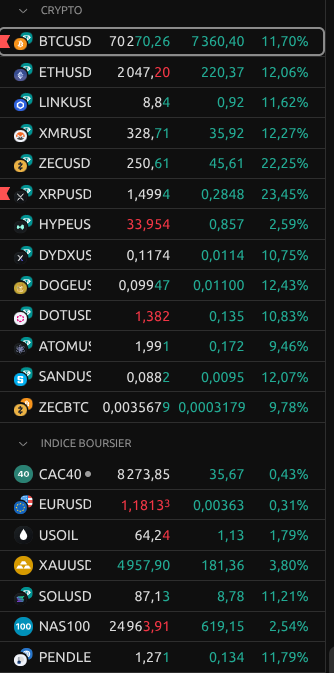
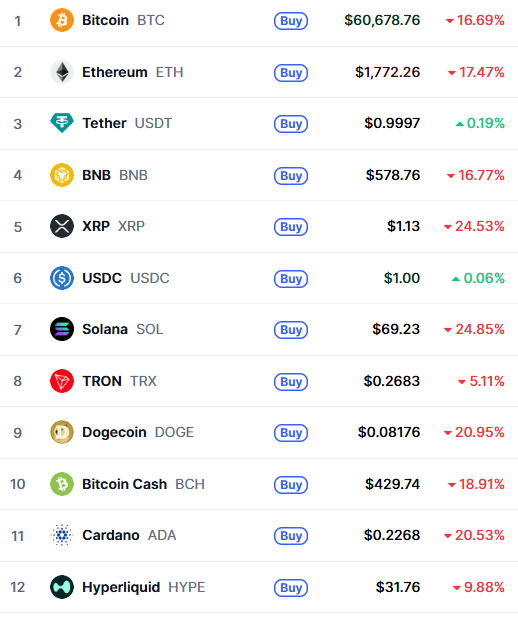
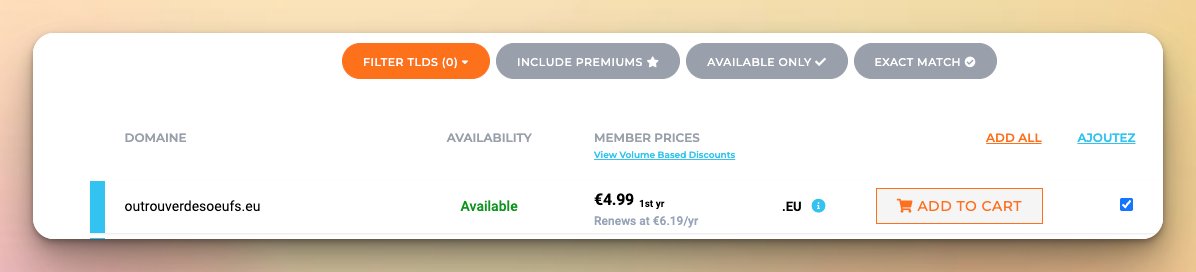
Français
Yvan SEO
1.1K posts

@YvanSEO
Passionné par le #SEO depuis 2004 #SMO #SMA #SEA









🔴 Affaire Epstein : "Mettre en cause quelqu’un sur la simple mention de son nom dans des documents serait dangereux", estime Paul Melun, tandis que Nathan Devers appelle à s’en tenir aux faits établis et au travail d’enquête journalistique. #LePourEtLeContre #canal16