Tweet fixado
ふじえもん
5.6K posts

ふじえもん
@fujiengineer
骨伝導 音声🗣️の認識とか強調とか アクセシビリティ スクラム 日本酒🍶 難聴です🦻 4月から社M 聴こえに関係なく発言できる、伝わる環境づくり
Entrou em Mayıs 2022
475 Seguindo311 Seguidores
@mimikun_Dev 続報です
こちらももしよければご確認くださいませ.認識対象者を指定できるようにしてたりします
なんか気になったこととかあればIssueください!
github.com/shotafujie/koe…
日本語

@fujiengineer
こんにちは
Discordの通話で
・自分以外が全員聴者
・文字起こしツール使用
という状況のとき、話者識別するために、安価なソリューションないですか?
YY文字起こしだと2時間しか使えないので…
日本語

@mimikun_Dev github.com/shotafujie/koe…
ちょっと個人的に気になって作ってみたので良ければお試しください.Botを発行して鯖に追加して,TOKENを設定して実行してもらえれば誰が何を話しているかをチャットに出します
日本語
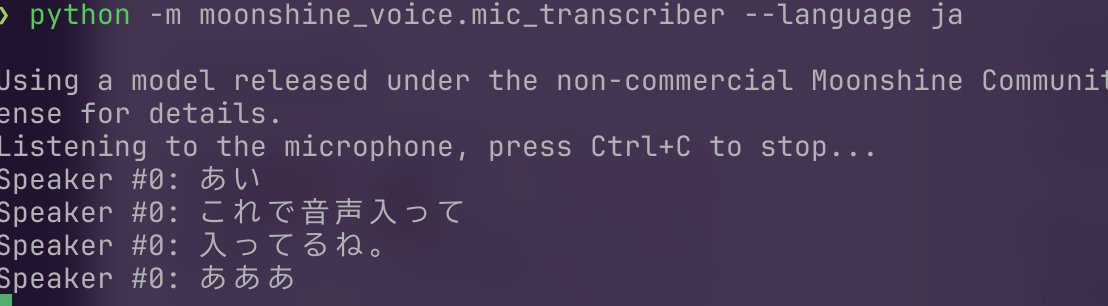
@mimikun_Dev moonshine,動かすだけならモデルをダウンロードして,languageをjaにしてコマンド叩けば日本語で話者識別+文字起こしされますよ
#python" target="_blank" rel="nofollow noopener">github.com/moonshine-ai/m…
話者情報は,単にクラスタリングしてその番号を出してるだけなので,言語情報から話者がわかるなら最初に自前で紐づけるとかすればって感じです
日本語
ふじえもん retweetou

Three models. Three top-tier results. All shipped within just a few months by the @MicrosoftAI team.
- MAI-Transcribe-1 dropped today, the most accurate transcription model in the world across 25 languages according to FLEURS WER benchmark.
- MAI-Voice-1 sets a new standard for natural speech.
- MAI-Image-2 lands as a top 3 model family on @arena.
We've been building with them - now you can too. All 3 available now on Microsoft Foundry.
English
ボイチャ音声の文字起こし試してるが,先にOpusに越されてしまった..
しかし音声コーデックの扱いがだいぶめんどくさい..
ふじえもん@fujiengineer
Claude CodeでOllama経由でモデルを呼び出して実装させるのを試した qwen3-coder:latestを使っている M4Max128GBだと1時間ぐらいかけて出来た 常にGPUはMaxなのであったかい ローカルで時間はかかるけど,ここまで自律的に作業してくれるなら使えるなあ.あまりポンポン出されても作業すすまないので..
日本語

ふじえもん retweetou

昨年度まで日本音響学会(ASJ)の学生会員で卒業・修了された方へ:申請すれば直近2年間は学生会員と同額で正会員になれますので、会員の継続をご検討ください🙇
acoustics.jp/overview/membe…

日本語