Tweet fixado

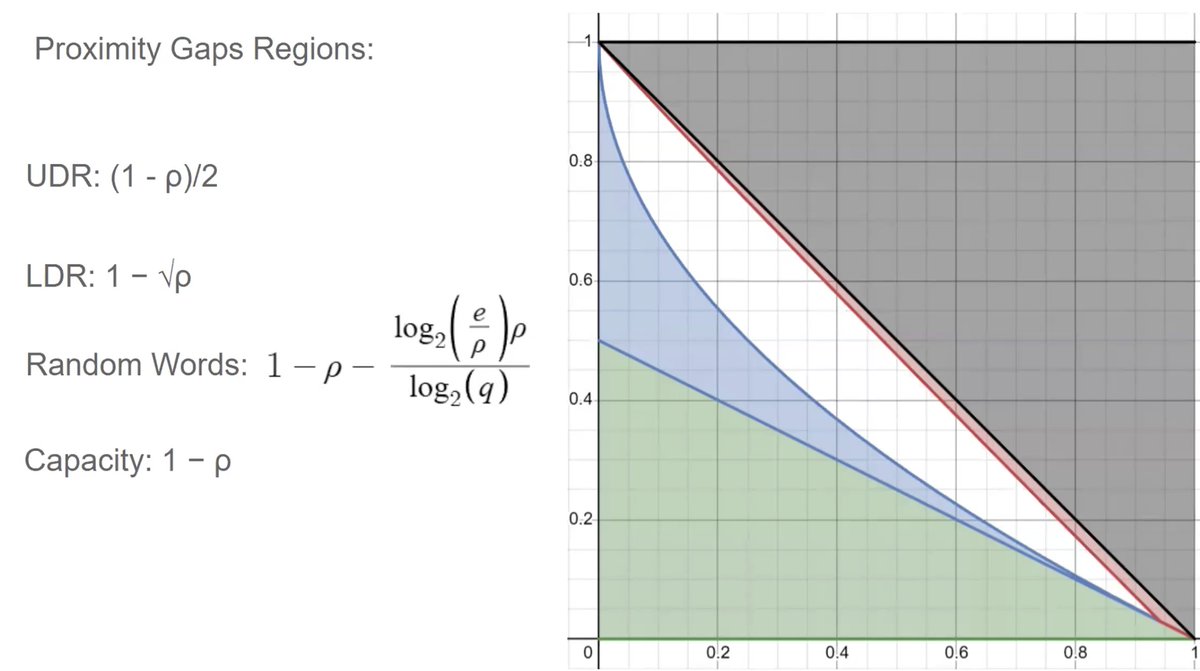
Very excited to introduce Khatam (eprint 2024/1843): a new Proximity Gaps result for Multilinear Polynomial Commitment Schemes. Not only does it reduce the size of Basefold (including over Random Foldable Codes), but it also improves Blaze, WHIR, Ligero, and others. 🧵(1/x)
English