Tweet fixado

Hôm nay xem lại Rewards System thấy cơ chế tính điểm của Axis như sau:
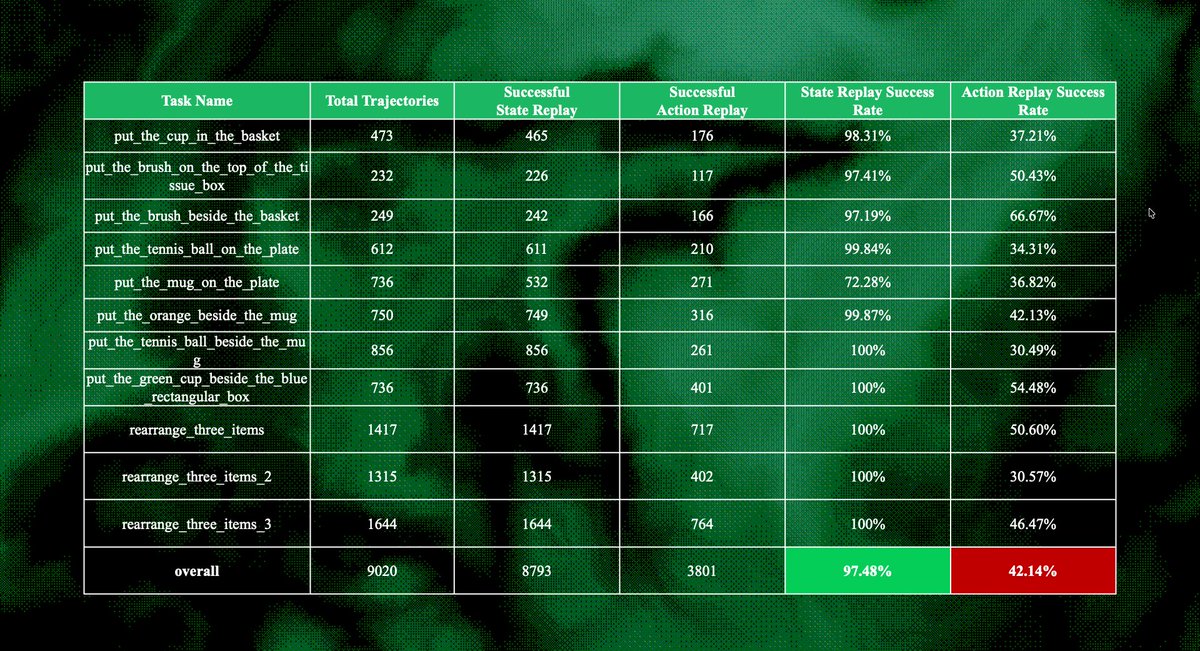
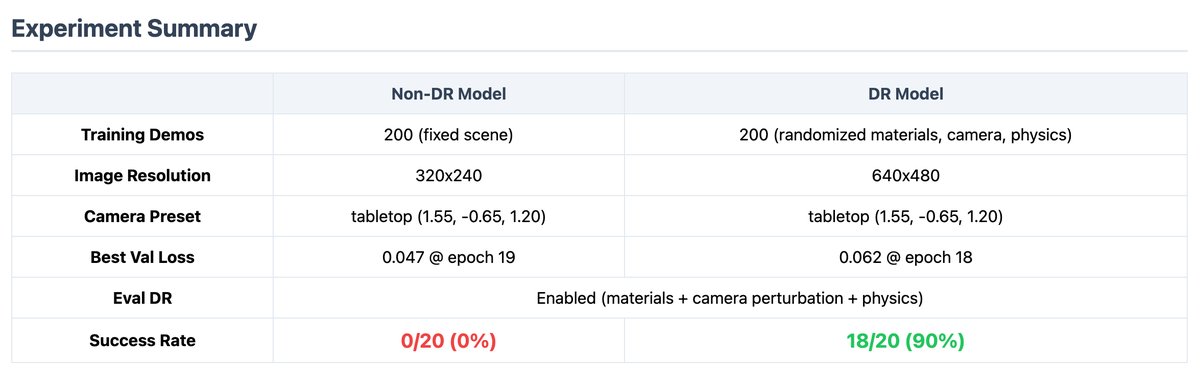
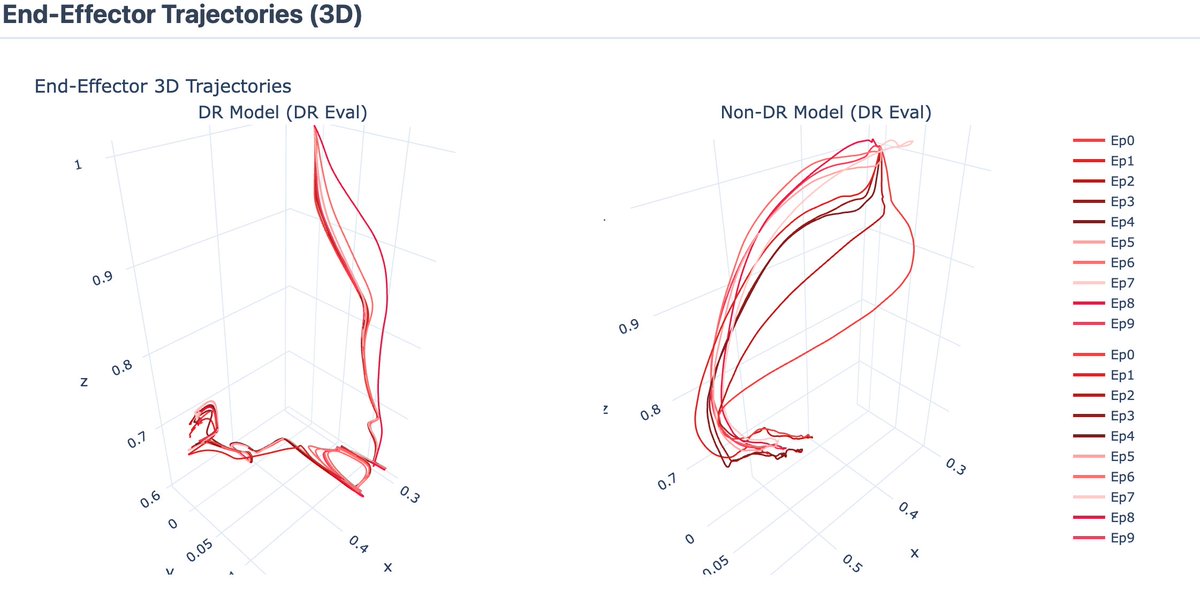
✨Mỗi task hoàn thành trên AXIS Hub sẽ tạo ra data entry độc lập, được đánh giá tự động qua multi-stage (sanity check, rule-based, VLM, peer review) → gán rating Good/Great/Perfect.
✅Perfect = tối ưu tốc độ + mượt mà + không lãng phí motion → reward cao nhất
✅Reward scale theo chất lượng + độ khó task (sao cao, featured, slot ít)
✅Hoàn thành task nhận Points ngay lập tức. Sau này sẽ có revenue sharing + token on-chain
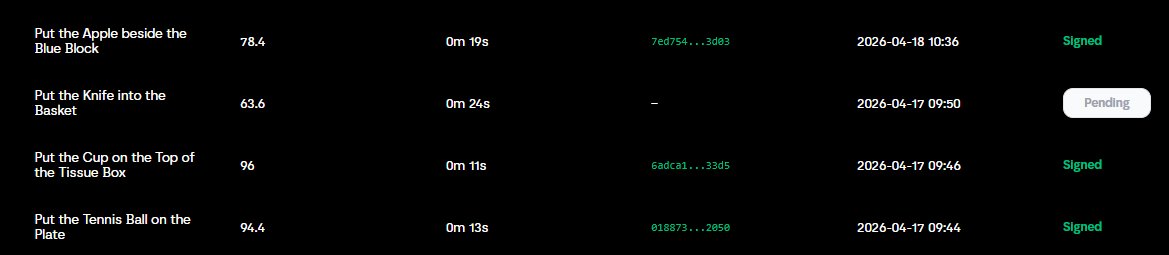
💡Dựa vào thông tin Leaderboard thì mình hiểu là xếp hạng theo data entry, không phải số lượng người hoàn thành
→ nghĩa là 1 người có thể chiếm nhiều vị trí top của cùng 1 task nếu submit nhiều trajectory chất lượng.
@axisrobotics

Tiếng Việt