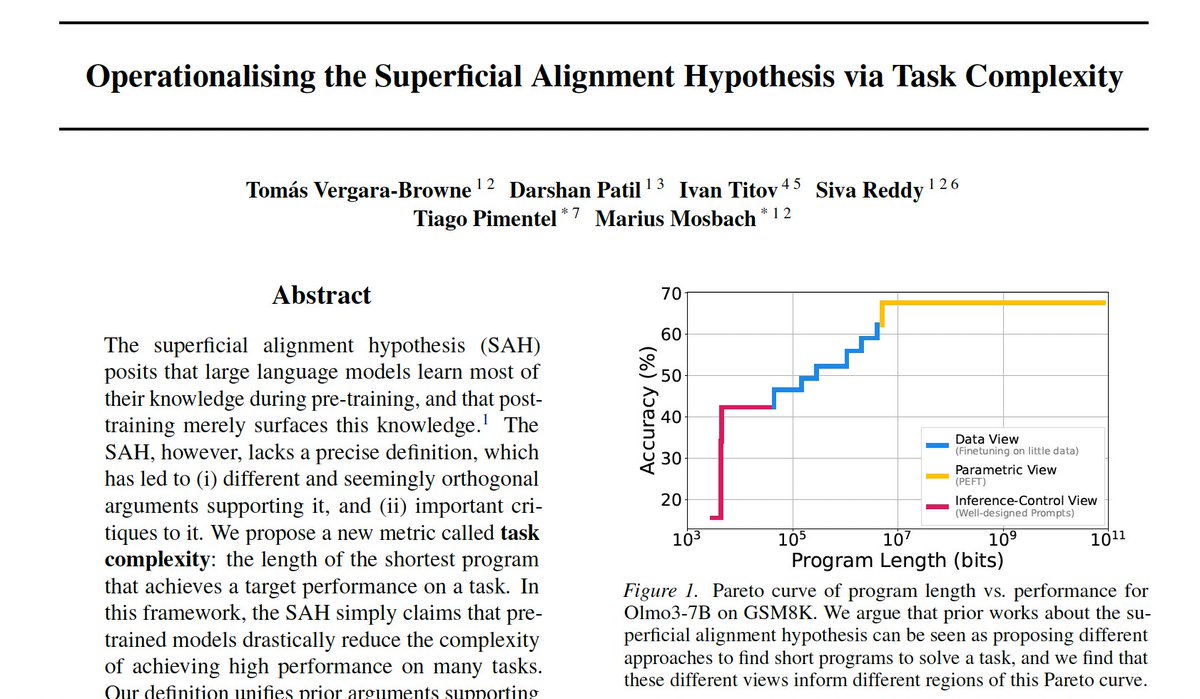
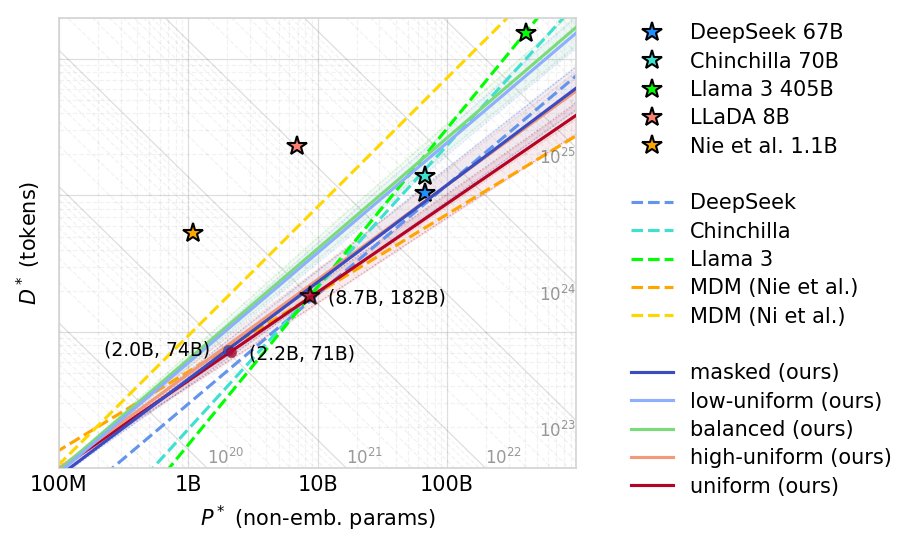
Tweet fixado

Tokenisers are a vital part of LLMs, but how hard is it to find an optimal one? 🤔 Considering arbitrarily large alphabets, prior work showed this is NP-hard. But what if we use bytes instead? Or strings like a, aa, aaa, ...? In our new paper, we show this is still hard, NP-hard!

English