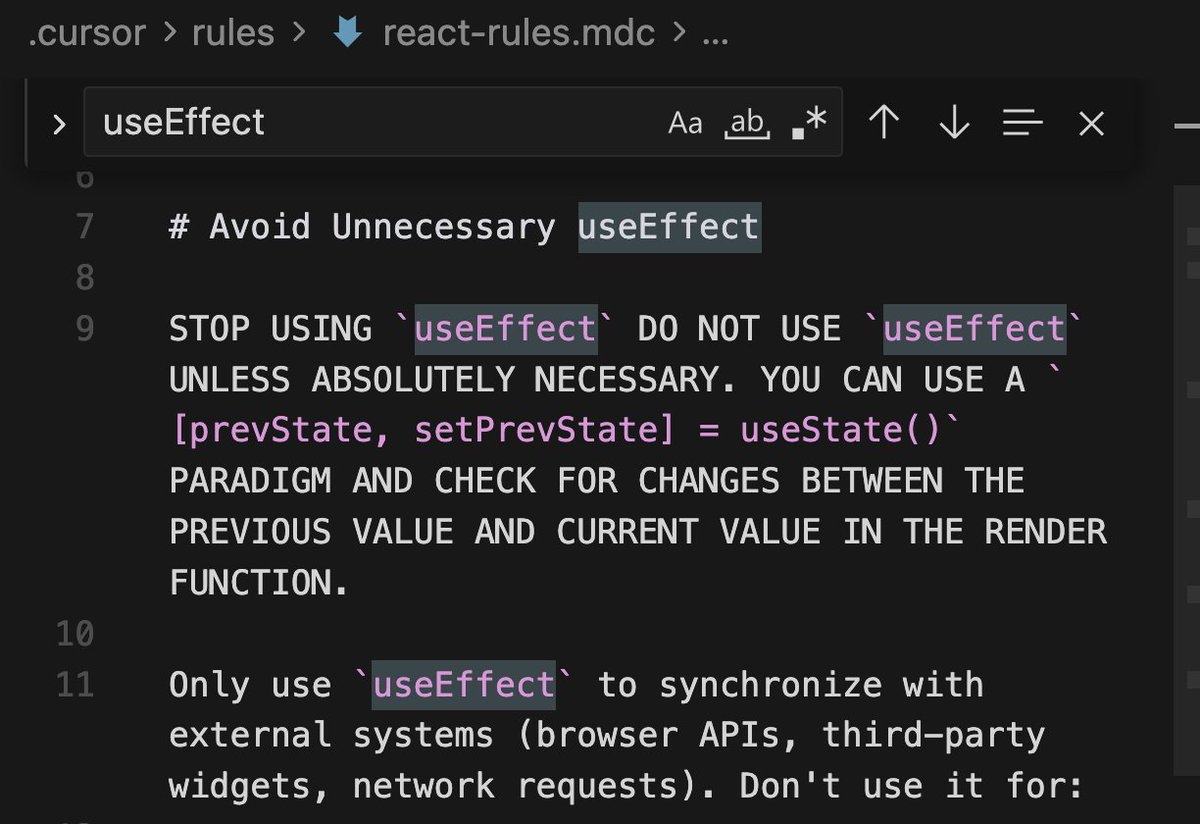
yo @codyschneiderxx @maxchehab how does your GSC look with your >13,000 blog posts for graphed? wondering if it worked or got punished
English
bijan bina
1.2K posts

@voidserf
I install AI visibility systems for trust-first brands. When someone asks ChatGPT about your space, you should be the answer.


Do people believe in God because they found evidence, or because they were taught to believe as children?





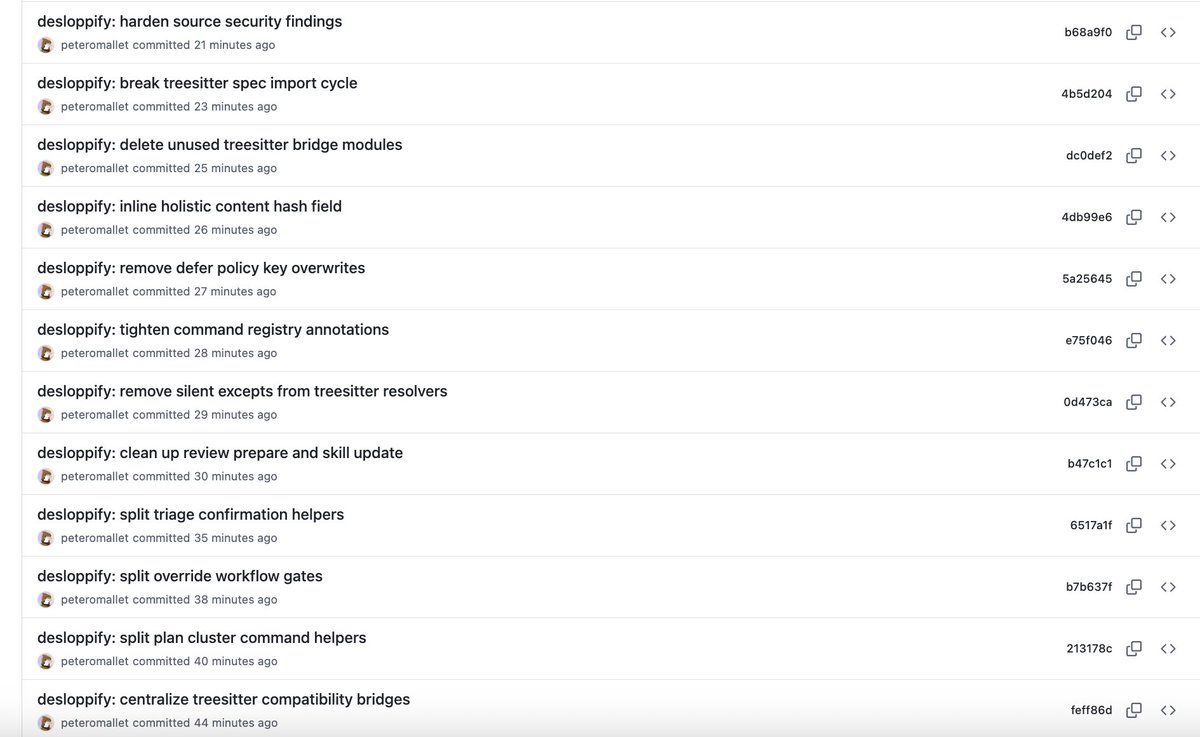
Introducing Desloppify v0.9! I'm so convinced that this can make vibe code well-engineered that I'll put my money where my mouth is. If you can find something poorly engineered in its 91k+ lines of code, I'll give you $1,000. Details in Github issue, you have 48 hrs.