voratiq
102 posts


voratiq
@voratiq
Which coding agent wins on real work?
SF Entrou em Eylül 2025
0 Seguindo113 Seguidores

Wow.
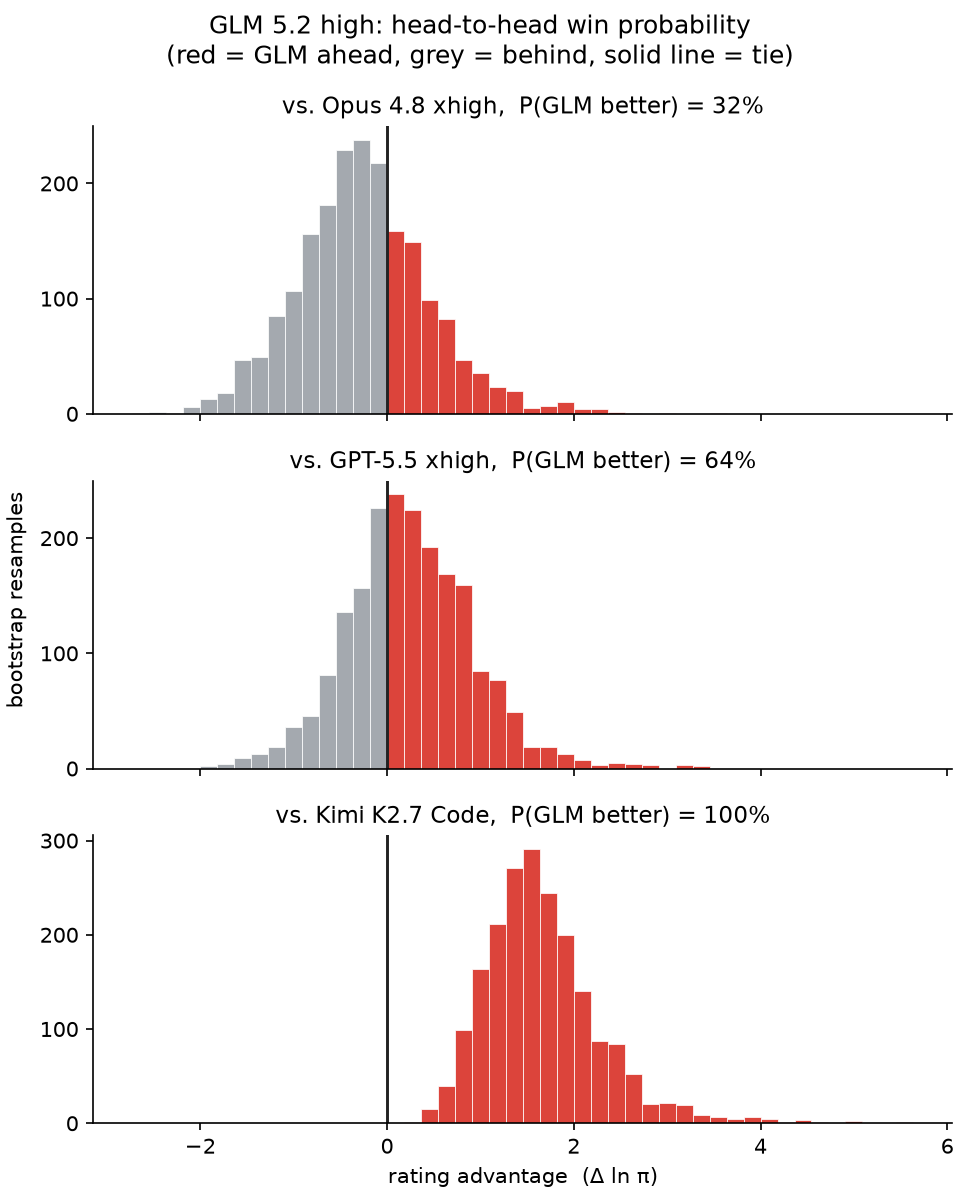
@Zai_org GLM 5.2 is a marvel! It is *at least* as good as Opus 4.8 and GPT 5.5. It's super fast, inexpensive, and not too verbose.
It responds with nuance and judgement, & handles long context VERY well.
I've never experienced an open weights model like this before.
English
Sending out a deep dive to our subscribers early next week → #subscribe" target="_blank" rel="nofollow noopener">voratiq.com/#subscribe
English

@zhihanz1205 It's pretty barebones! We just use a simple guardrails extension that keeps tool output from blowing up the context.
English

Want more insights on how coding agents perform on real work?
The full Fable 5 breakdown (performance, cost, the win matrix, methodology) just went out to subscribers
Subscribe for the next one → #subscribe" target="_blank" rel="nofollow noopener">voratiq.com/#subscribe
English
Fable 5 debuts at #1 on the Voratiq leaderboard, with an impressive margin over every previous leader
It excelled in hard & extra-hard tasks, but was outcompeted by weaker models on medium-difficulty ones
And it's expensive!
So, Fable is the new SOTA, just not for every task.

English
Subscribe to our newsletter to get the Fable 5 deep dive when it drops → #subscribe" target="_blank" rel="nofollow noopener">voratiq.com/#subscribe
English


Opus 4.8 xhigh performing at this level is exciting for multi-agent system design
Same-agent or same-family systems can help with things like context management
But generally you get higher performance overall when the agents have decorrelated strengths and weaknesses
voratiq@voratiq
Leaderboard update! Opus 4.8 xhigh takes #1, a clear step over 4.7 - though its edge on GPT-5.5 xhigh is within noise For Qwen 3.6, the dense 27B strongly outperforms the 35B-A3B MoE - with a head-to-head edge of ~89%
English
If only someone actively tracked agent performance as a function of latency, cost, and reasoning level using a continuously evolving test set of real software engineering tasks. That would be useful.
Noam Brown@polynoamial
English


