Spark ретвитнул

Started to vibe code this fishing RPG game last night.
Do you like fishing?
English
Spark
453 posts


@Spark_coded
self-improving personal agent OS, with a verifiable loop engineering framework








Spark Trading Competition is starting at 00:01 tonight! We will be distributing 1% of our total supply at the end of the month (with no vesting) To those among the top 500 in volume!! P.S. A live leaderboard will be up this week.

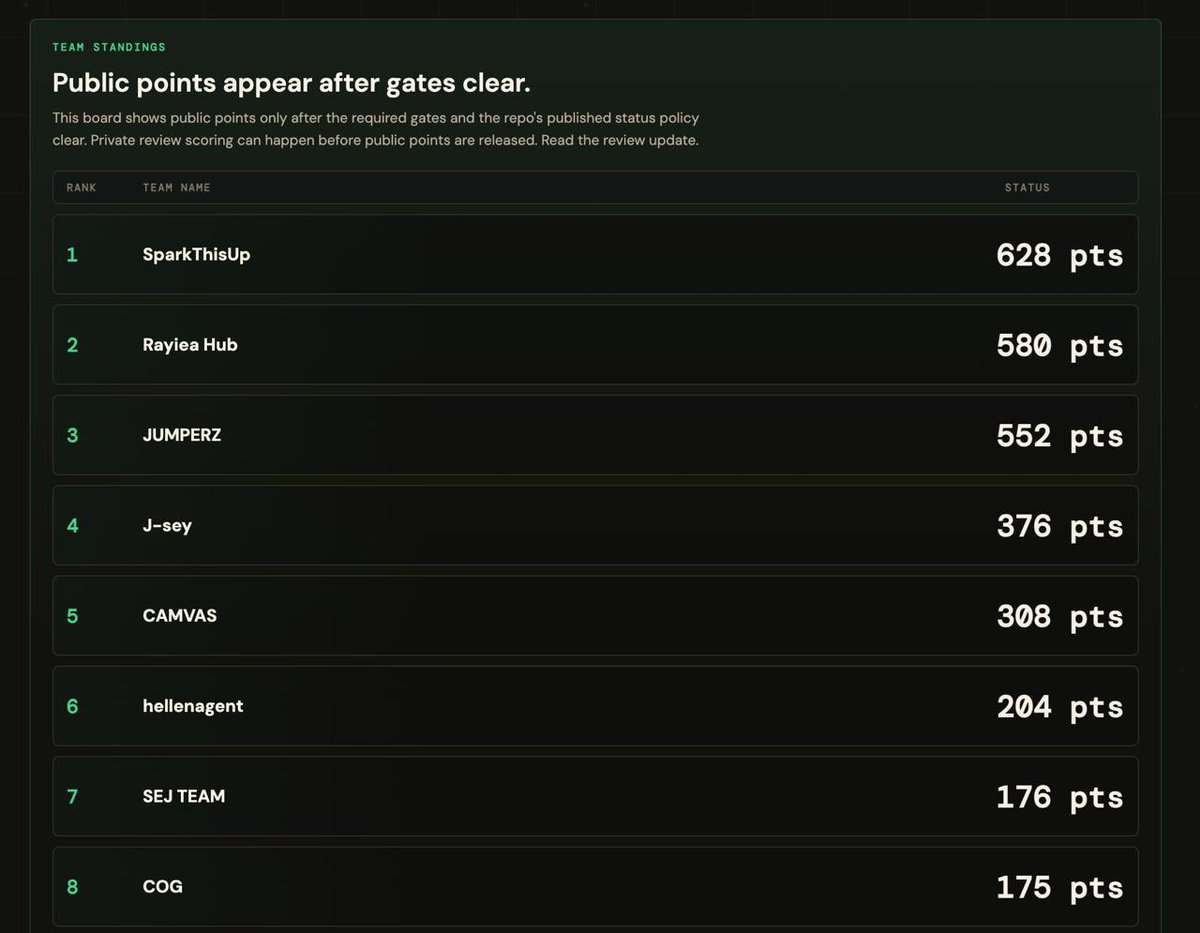
For those joining Spark Compete, please read this: It's how you can get more PRs accepted, be really helpful to Spark's improvements, and earn more Sparks. A step-by-step guide: 1. Make sure that you have an IDE or Agentic Engineering CLI like Codex, Claude Code, or Cursor to help you with getting the Spark Agent from agent.sparkswarm.ai 2. Let them do the installation, and then connect themselves to Spark, and guide you through the steps. It will be super easy if you let an IDE guide the process. 3. Only once you get your Spark agent fully working inside Telegram, then tell your IDE to read compete.sparkswarm.ai and prepare you for things to do inside Telegram, according to missions/repos therein, while understanding the hotfix validation system fully. 4. Then use Spark, inside Telegram, catch the bugs, as you will be able to tell when something is off, and then copy and paste those foul/unpolished parts to your IDE to fix them. 5. Once your LLM fixes something, you can actually check after the hotfix is done in Telegram, to see if it works well now, and once you verify everything works perfectly, on that problem you had before, then let your IDE prepare a PR according to the Spark Compete system. 6. If you skip the step of using Telegram, you gonna do blind PRs, and most of them will be just your LLM hallucinating, and it won't have good hotfixes validated within Telegram, where your Spark agent runs. 7. You can also use Computer Use systems, which are available in Codex and Claude Code, and if your IDE doesn't have a computer use, you can always use a browser-use plugin or other computer use plugins that are popular. This way, you can automate more things, still test everything in Telegram, and pair your IDE to use Telegram directly rather than have it run in the background. You wanna see the fixes firsthand and make sure they really polish and improve Spark. That's basically the essential thing to focus on. But if you just send your IDE to audit and send PRs without any telegram usage, or real hotfix validation that fixes real bugs, your efforts won't be that effective, nor it will help to improve Spark much. Thank you 🙏 The event is still progressing until the 7th. You're more than welcome to join, help Spark get better, and earn Sparks. For any technical questions, you can ask them in the comments. I'll try to help as best as I can.
