Закреплённый твит

🔥 Meet Quanton — the new query execution engine from Onehouse.
👍 Same Spark & SQL.
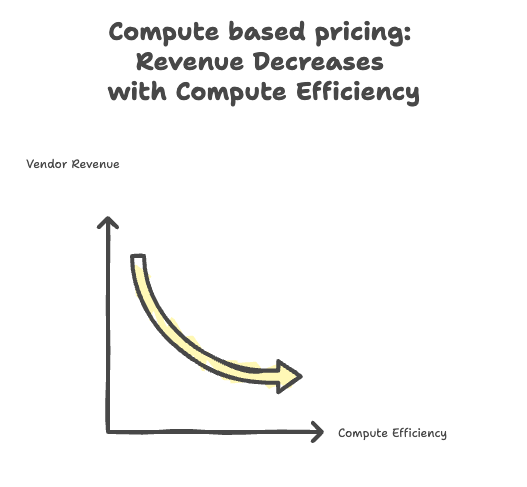
📉 At least half the cost.
📈 1.6x-3.6x better ETL price-performance
📊 2.2x-6.5x better Ingest price-performance
👉 Read the full blog here:
onehouse.ai/blog/announcin…
⬇️ Download our free Spark cost analyzer tool: onehouse.ai/spark-analysis…
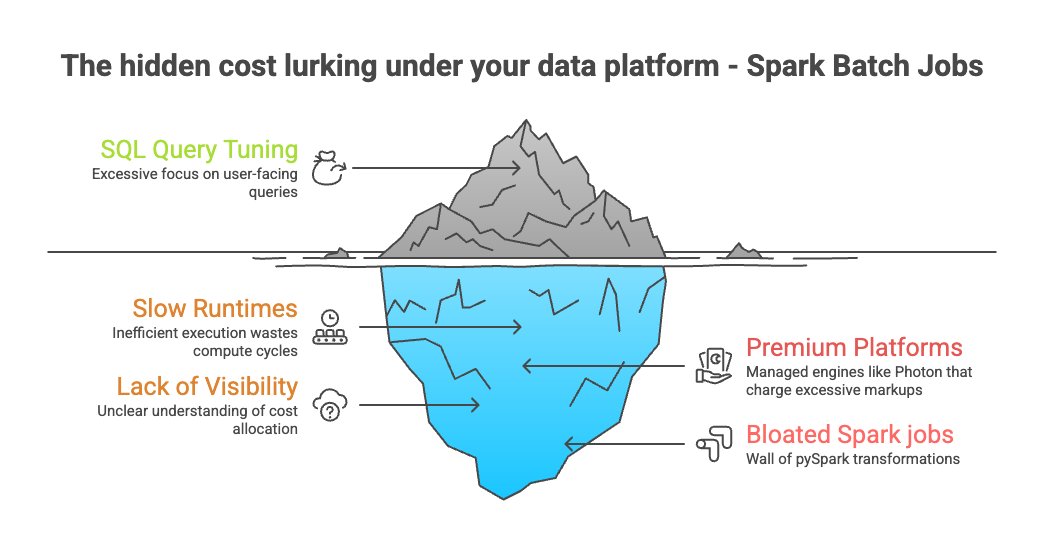
⁉️ How? Quanton processes only what’s actually needed. Most engines only try to go fast. Quanton goes smart.
✔️ Drop-in replacement for Hudi + Spark jobs
✔️ Compatible with Iceberg, Delta, SQL, dbt
✔️ Benchmarked thoroughly against top cloud runtimes
✔️ No rewrites. No lock-in. Just plug in & save.
For Hudi users hitting support walls with your Spark provider or rising infra bills, it’s time to switch. We've got you even if you’re writing to Iceberg or Delta. Quanton boosts every open table format to its potential. Onehouse is now the most open, most cost-efficient platform for ETL.
Proudly built by a small, gritty team of Davids in a sea of Goliaths. Quanton is here. It’s open. It’s fast. It’s efficient.
We are actively building towards unlocking the next 30-80% efficiency gains by the end of the year.
#ApacheHudi #Spark #SQL #Lakehouse #ETL #OpenData #DataEngineering #Onehouse #Quanton #DataPlatform #Infra #DataOps #CloudData #Efficiency #ApacheIceberg #DataWarehouse #DeltaLake
English