Закреплённый твит

How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards?
In our work, we:
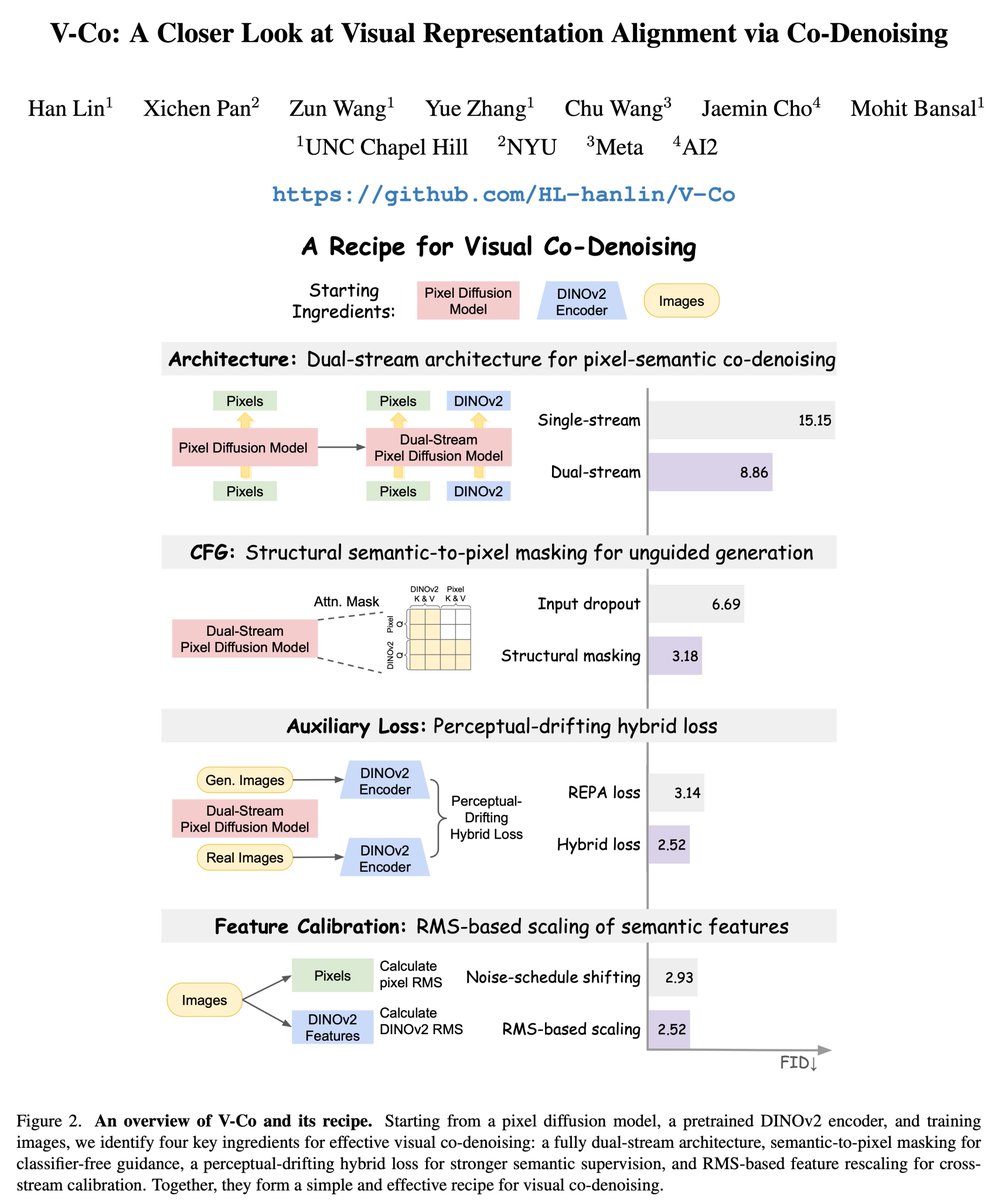
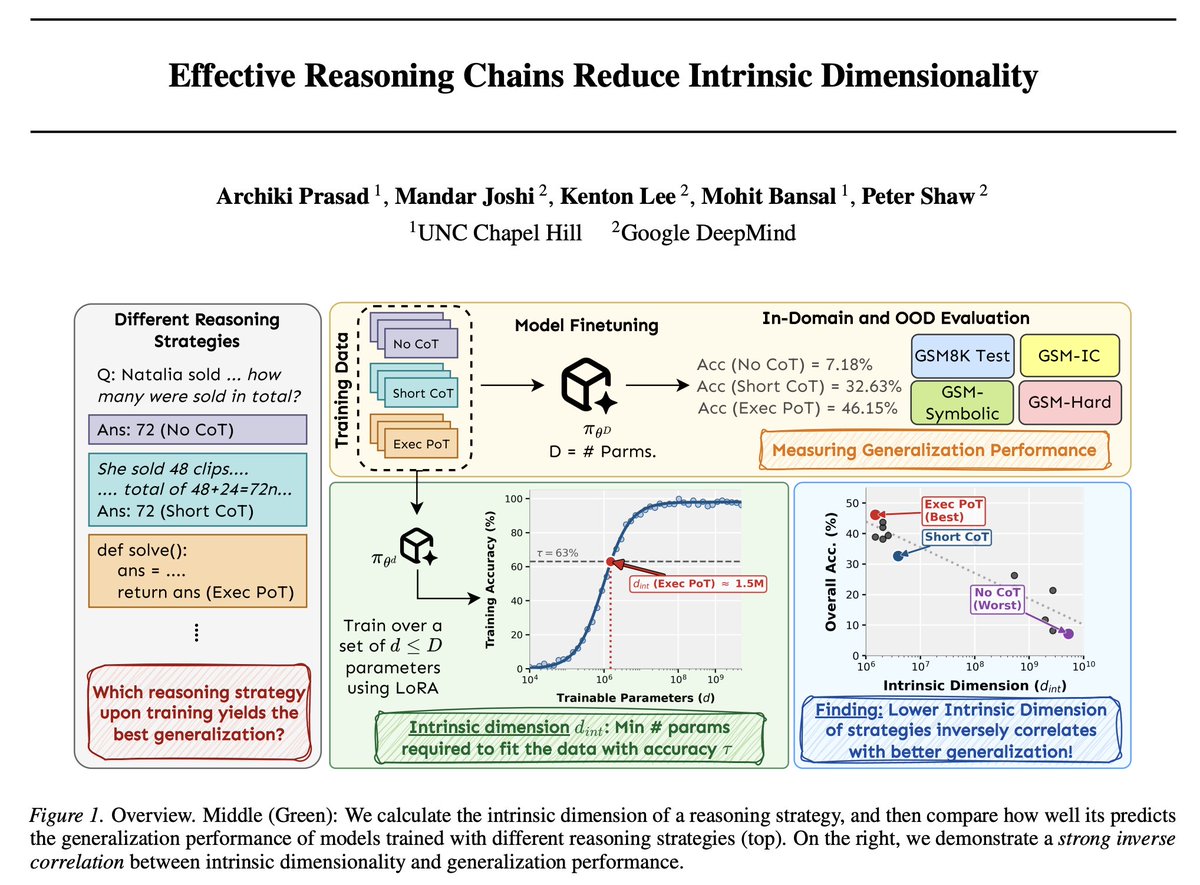
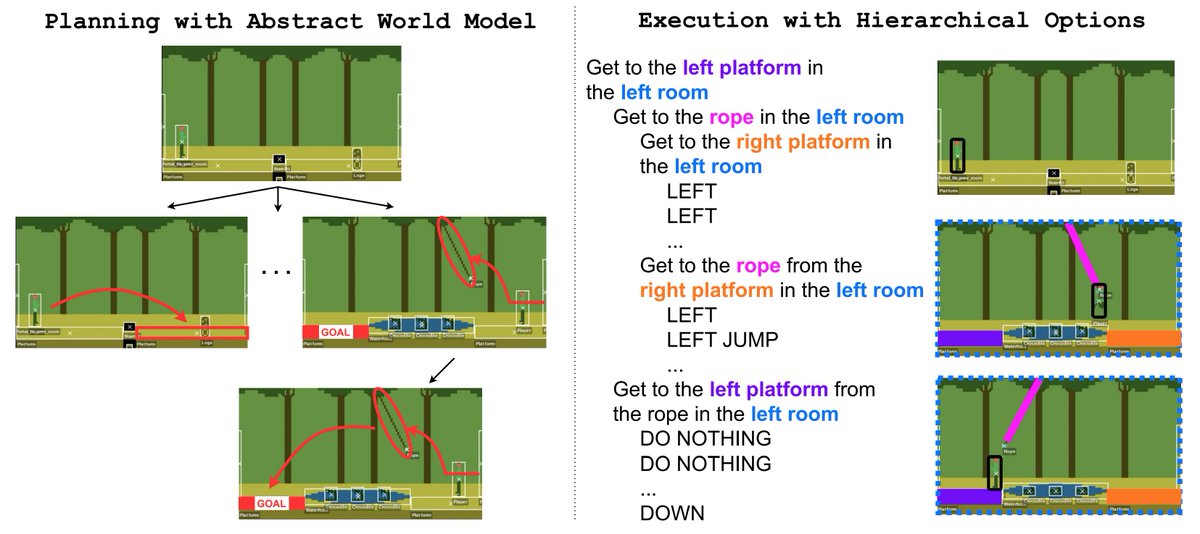
1️⃣ infer an executable symbolic world model (a probabilistic program capturing environment dynamics) offline from one life (1 episode), with dynamic graph routing for credit assignment.
2️⃣ develop Crafter-OO, our reimplementation of the Crafter environment that exposes a structured, object-oriented symbolic state and a pure transition function that operates on that state.
3️⃣ implement 20+ executable scenarios to test knowledge of core mechanics + mutators that generate illegal distractor states to probe world model understanding.
4️⃣ introduce an evaluation protocol that measures the ability to distinguish plausible future states from implausible ones + the ability to generate future states that closely resemble reality.
5️⃣ show that the inferred world model can be used as a simulator for planning.
Thread 🧵👇
GIF
English