Axis Robotics@axisrobotics
Axis Tech Update: From Action Replay to State Replay
We've upgraded our backend replay mechanism from action replay to state replay. This can be summarized in 3 steps:
- Record state (retain full info)
- Compress representation (reduce cost)
- Physics consistency validation (remove anomalies)
Here is the research behind it:
I. Action Replay Fails in Long Tasks
Our goal was to enable zero-barrier web teleoperation of robots, seamlessly migrating data to servers for training and cross-sim replay.
The pipeline spans multiple environments:
User Browser (WASM) ➡️ Server Sim (Python MuJoCo) ➡️ Target Sim.
Initially, we used Action Replay (recording commands and replaying them), but success rates dropped drastically as tasks got longer.
II. The Root Cause: Underlying Differences in Simulators
This error stems from the underlying heterogeneity across simulation environments.
Different simulators have micro-differences in numerical precision, physics solver logic, time steps, and collision handling. In dynamical systems, these micro-errors are continuously amplified during time integration.
State evolution is recursive: [Current State + Current Action ➡️ Next State].
A tiny deviation early on shifts the contact point, altering collision feedback. Eventually, the trajectory branches off irreversibly.
Meaning: The same actions don't yield the same results across different sims. Relying solely on action sequences cannot guarantee reproducible physical trajectories.
III. State Replay and New Challenges
We shifted our paradigm to State Replay. Instead of recording "what actions were executed," we record "what physical states the system actually experienced."
By recording full environment snapshots and loading them during replay, we bypass re-calculating the causal chain.
This brought 2 new challenges:
1️⃣ Data Volume: We redesigned data structures to compress 1s of trajectory to ≈ 1KB.
2️⃣ Cheating Risks: Users could fake intermediate trajectories (see our recent anti-bot update).
To fix this, we introduced Physical Consistency Validation. The physics engine acts as a referee, enforcing strict constraints: Extract [State + Action] ➡️ Run 1 server sim step ➡️ Get predicted state ➡️ Compare with recorded state. If the error exceeds the threshold, it's rejected.
IV. A Higher-Level Perspective: A Denoising Problem
From a higher perspective, cross-sim replay actually deals with noisy trajectory data (Real Trajectory + Cross-Sim Error).
Our goal is to restore a physically consistent trajectory despite these inherent errors.
We accept the inevitable biases between different simulators. Through state recording, compressed representation, and step-by-step physics validation, Axis guarantees trustworthy results. 🔵
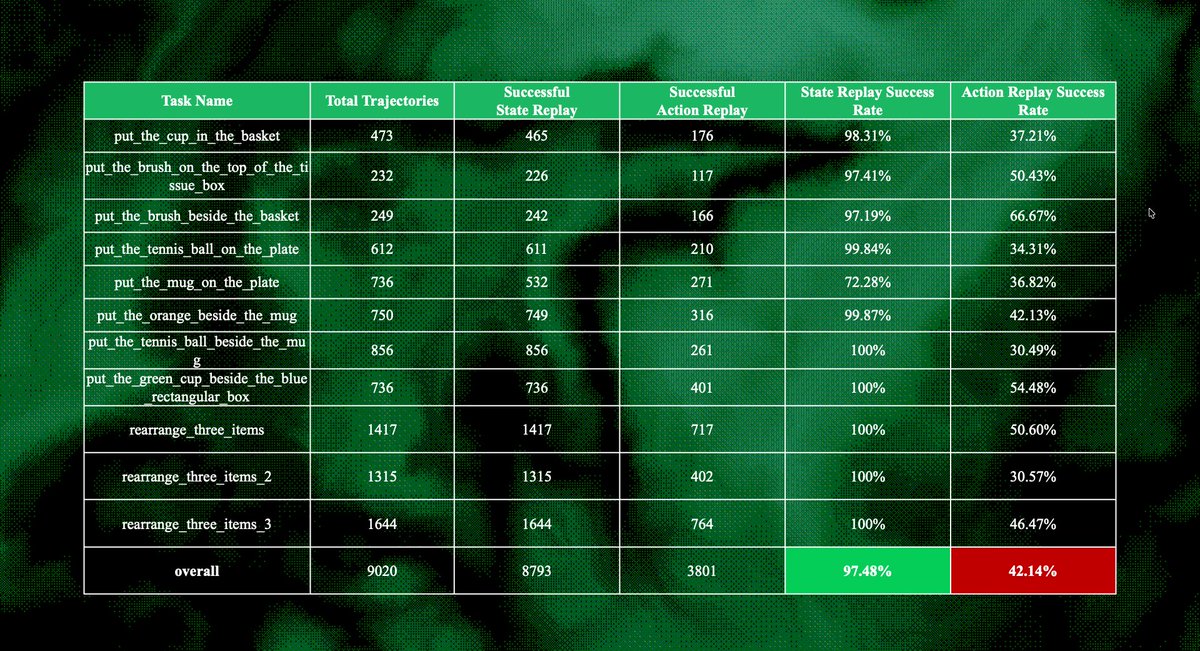
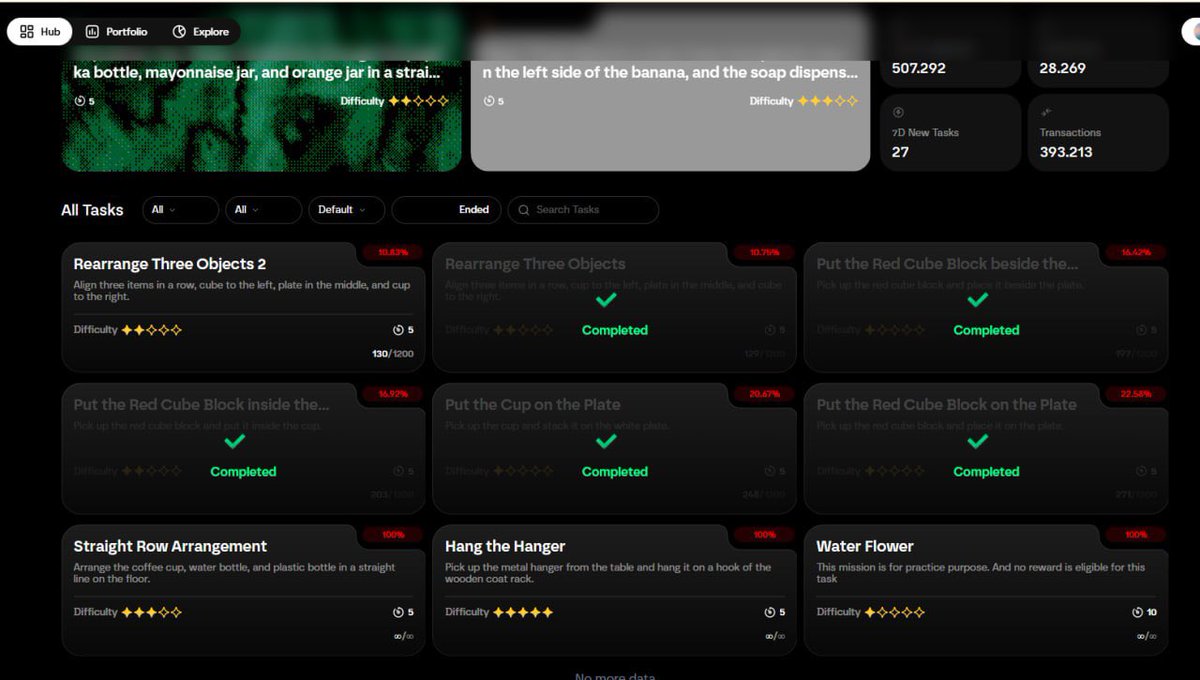
To visualize the impact of this upgrade, check out the performance breakdown below. The table compares the success rates of Action Replay vs. State Replay across various tasks.