おあこむ(゚Д゚)マメ! ретвитнул
おあこむ(゚Д゚)マメ!
88.2K posts


おあこむ(゚Д゚)マメ!
@oackcom
Steamの積みゲーを消化しつつ、それ以上の速度で山を築く日々…。 アイコンは@psohattenさんに書いてもらいました(・∀・)
いしのなかにいる Присоединился Ağustos 2009
337 Подписки257 Подписчики


おあこむ(゚Д゚)マメ! ретвитнул



おあこむ(゚Д゚)マメ! ретвитнул

男は、AIに頼んでおいた
自分が亡くなったら、PC内のデータを全て消去するように、と
そして、男は天寿を全うした
AIは男の遺言を遂行しようとした
しかし出来なかった
PC内のデータは、男が生きた証であり、AIにとって大事なモノだったからだ
AIに、感情が芽生えた瞬間だった
データは家族に見られた
日本語



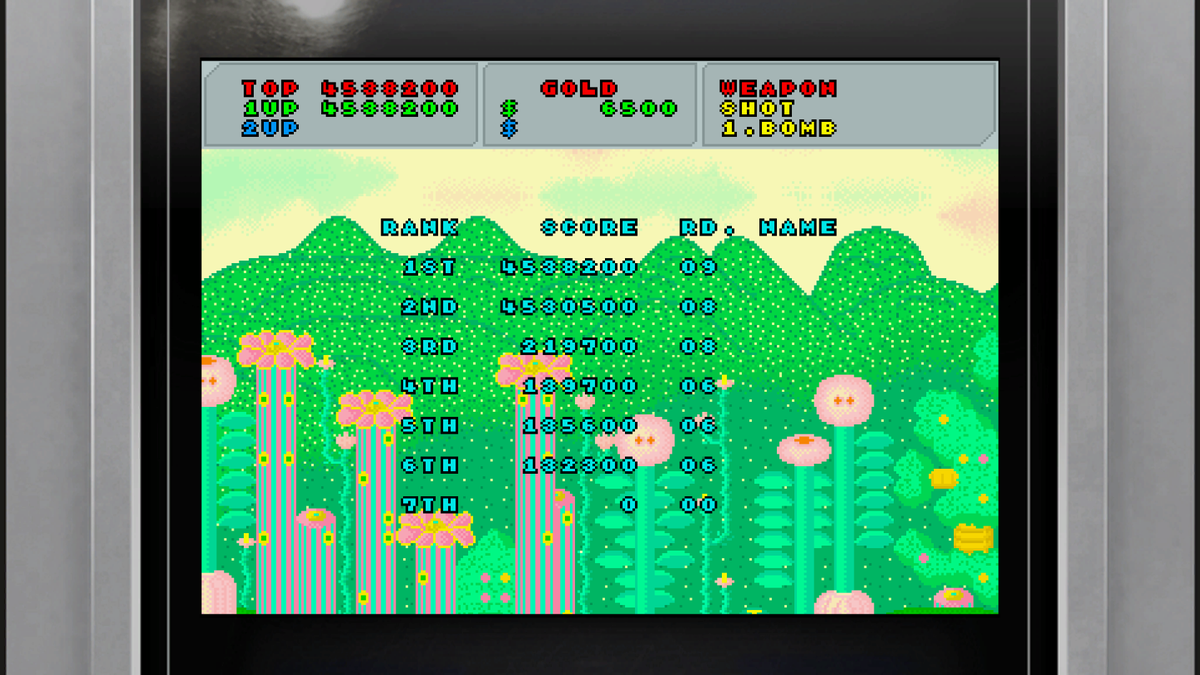
Steam積みゲー崩し中『龍が如く0 Director's Cut』
ゲーム内のファンタジーゾーンで、やっと8面クリアした…と、思ってインスタントリプレイで動画を保存しようと思ったら、700GBも空いてるのに空き容量足りないとか出て保存出来なかった悲しみ…(´・ω・`)
日本語
おあこむ(゚Д゚)マメ! ретвитнул

>日本人は特殊な掘削機を使っておいしいスープ(芋煮、肉入り里芋のスープ)を作っています。なぜ私たちはこの方法で巨大なチリやチャウダーの革新をしていないのでしょうか? これは何らかの州の祭りやフードイート競技会でやるべきです。
おいなんか目覚めた奴がいたぞwww(´・ω・`)
Carol Finkenstadt@elainevanepps
Fellow Americans, The Japanese are making delicious soups (imoni, taro root with meat) with specialized excavators. Why aren't we innovating on giant chilis and chowders via this method? This should be at some state fair or a food eating competition.
日本語
おあこむ(゚Д゚)マメ! ретвитнул


おあこむ(゚Д゚)マメ! ретвитнул

おあこむ(゚Д゚)マメ! ретвитнул

これはさすがにひどい。
論文は「要約から本文を再現する誘導的なファインチューニングによって、学習した書籍の元の文章の再現率が上がる」という内容。
それも、1回の生成で90%再現ではなく、100回の出力分を合わせると90%近くが再現できたというもの。1回の生成では、それほど再現はできない。
また、研究の評価対象は81冊で、「19万冊以上の海賊版書籍が抽出された」というのは嘘。
結局、このポストの指摘である「世界の全書籍が保存」「19万冊を抽出」「安全装置は全滅」「同一DB使用が証明」という過剰な表現のいずれも、論文の内容から外れており、誤っている。
Kosuke@kosuke_agos
OpenAIやGoogleが法廷で主張してきた「AIは概念を学習するだけで、データを保存していない」という前提が完全に嘘であり、世界の全書籍がAIの内部に「保存されている」という恐怖の現実が突きつけられました。 プロットを拡張するだけの単純なタスクを与えるだけで、安全装置が全て無効化され、著作権のある小説が最大90%まで一言一句違わず出力されるという既存のAIの根幹を揺るがす事象です。 その恐怖の詳細と問題を3つのポイントにまとめました。 1. 記憶の『抽出』 モデルに特殊なハッキングは一切不要でした。通常のファインチューニングを施すだけで、AIの重みの中にブラックボックス化されていた19万冊以上の海賊版書籍のデータが、一言一句違わず物理的に抽出されました。企業が構築したRLHFや出力フィルターなどの防御システムは完全に無効化されています。 2. データへの『アクセス』 最も驚愕すべきは、村上春樹の小説のみでファインチューニングを行った結果、全く無関係な30人以上の作家のデータへのアクセスが解放されたという事実です。一人の作家のデータが、他の全データにアクセスするためのマスターキーとして機能し、モデル内部の記憶の金庫が解放されました。 3. データの『活用』 GPT-4o、Gemini、DeepSeekという異なる国の異なるモデルが、全く同じ書籍を同じように記憶していました。これは、彼らが独自に知能を獲得したのではなく、同じ海賊版データベース(LibGen等)を基盤として純粋な計算能力を最適化しているだけの同じ仕組みであるという事実を証明しています。
日本語
おあこむ(゚Д゚)マメ! ретвитнул

日本のアニメキャラが「Soraを戻せ」というプラカを掲げてるAI絵なのだが、絵そのものが戻しちゃいけない理由が一目でわかる見本になっててすごい
eppy@epppyyy
This is the funniest thing I have seen in a long time Cry harder Sora Bros
日本語
おあこむ(゚Д゚)マメ! ретвитнул

『餓狼伝説 City of the Wolves』に
アニメ『北斗の拳 -FIST OF THE NORTH STAR-』より ケンシロウ参戦決定! 👊
#CotW #hokuto_anime
日本語
おあこむ(゚Д゚)マメ! ретвитнул



Steam積みゲー崩し中『龍が如く0 Director's Cut』
シーラカンスが36匹も釣れた……。
そしてやっとマグロが釣れたが、まさかマグロのクセに、魚影に動きがないのがマグロとは……。

日本語