Bottom line: @lancedb's JSONB gives AI builders the same storage efficiency as Variant, with more flexibility, and no vendor lock-in.
3/3
Read the full blog post for details 👇🏽
lancedb.com/blog/lance-jso…
Agent data (tool calls, chain-of-thought traces, RAG context) is 𝘁𝗲𝘅𝘁-𝗵𝗲𝗮𝘃𝘆, 𝗱𝗲𝗲𝗽𝗹𝘆 𝗻𝗲𝘀𝘁𝗲𝗱, and distinct between rows. It's not structured metadata. That's exactly where @lancedb's JSONB matches Variant in storage size, while offering more flexibility.
2/3
𝘿𝙤 𝙮𝙤𝙪 𝙧𝙚𝙖𝙡𝙡𝙮 𝙣𝙚𝙚𝙙 𝙑𝙖𝙧𝙞𝙖𝙣𝙩 𝙛𝙤𝙧 𝙮𝙤𝙪𝙧 𝘼𝙄 𝙙𝙖𝙩𝙖?
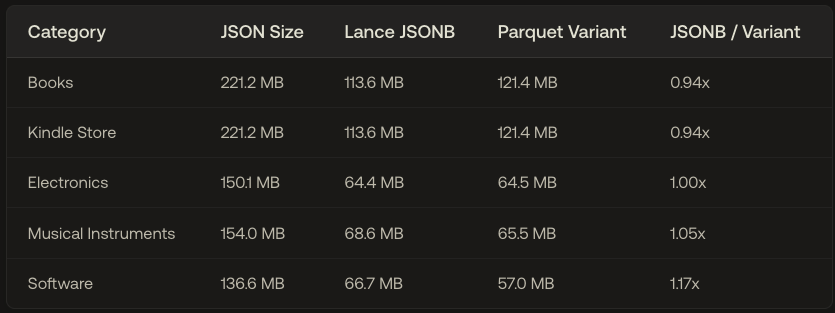
We benchmarked Lance JSONB vs Parquet Variant on real-world JSON workloads.
On text-heavy data with mixed schemas Variant and @lancedb's JSONB are within 𝟬-𝟴% of one another — essentially equal. Variant's 𝟮-𝟰x storage advantage only appears when documents share the same structure with short, repetitive fields
1/3
@LlamaIndex@itsclelia 3/4 This avoids splitting modalities across systems and losing context between stages.
The agent can retrieve what it needs, in the form it needs.
On our eval dataset, this setup reaches near-perfect accuracy on complex QA.
Full breakdown:
lancedb.com/blog/smart-par…
1/4 If your agent fails on PDFs with tables or charts, it’s usually not the model.
It’s the data pipeline. 🧵
We worked with @LlamaIndex and @itsclelia to build a structure-aware QA pipeline using LiteParse.
lancedb.com/blog/smart-par…
3/3 Compression is applied without breaking the access path.
Less data read → faster batch fetch → higher GPU utilization.
Benchmarks: lancedb.com/blog/lance-for…
2/3 With Lance format v2.2:
- ~50% smaller than Parquet on text-heavy data
- ~75x faster random blob reads (image/video fetch)
- Sampling + filtering performance stays flat
- No changes to application code
1/3 If your dataset doubles, your storage cost shouldn’t.
And your GPUs shouldn’t slow down reading it.
Most formats force a tradeoff between compression and access speed. Lance format v2.2 doesn’t.
3/3 Because Lance integrates both the file format and table format, fragment metadata tracks which blob objects are referenced by each dataset version.
That enables version-aware garbage collection and compaction without rewriting large blobs.
Full design: lancedb.com/blog/lance-blo…
2/3 Every blob is encoded as the same on-disk Arrow struct: (kind, position, size, blob_id, blob_uri)
The kind field identifies how the blob is stored, but the logical column type stays the same.
This lets the system route reads without changing schemas or APIs.
1/3 Rewriting multi-GB blobs during compaction or schema evolution is one of the worst failure modes in multimodal datasets.
Lance Blob V2 avoids this by defining blob storage directly in the **format design**.
🧵👇