Post


@cursor_ai @grok is Composer built on a proprietary model or an Open source model?
English

@cursor_ai nice but cmd+N still works better than any amount of RL training on this
English


@cursor_ai This is a shift from prompting → training for behavior.
RL-based compression = better long-horizon reasoning and consistency.
The edge moves to models that can think over time, not just respond once.
English

@cursor_ai Reducing compaction error by 50% is huge. Especially for long-horizon tasks.
English

This is the right direction. Running an AI agent across 100+ actions means your context window fills with stale file contents, old error messages, and resolved TODOs. Prompt-based summarization can't learn which details matter for downstream actions.
RL lets the model discover what to keep vs discard based on actual task outcomes — not a generic "summarize this" instruction.
Curious about the reward signal. Is it task completion rate on held-out coding benchmarks, or something more nuanced like diff quality?
English

This RL self-summarization is game-changing for long sessions! Reduced compaction errors by 50% means way less context loss on big refactors. How does it compare to Claude Code's agent handling for 100+ action tasks? Using it in my daily workflow now mind blown. 🔥 Anyone else seeing 10x speed?
English

RL-trained self-summarization is the right approach. The bottleneck in long-horizon coding tasks was never the model's ability — it was context management. Prompt-based compaction loses signal at exactly the wrong moments. Training what to preserve vs discard changes the ceiling entirely.
English

Better summarization means agents can handle longer tasks. But even with perfect memory, the agent still doesn't know your team's conventions or domain expertise. That's the gap — not capability, but context. We've been thinking about how to make that context layer composable and reusable across projects.
English

@cursor_ai how are you generating the training signal for this? getting ground truth for "good summary" seems harder than the RL itself
English
@cursor_ai prompted compaction always felt lossy to me. curious what the training signal for "good summary" looks like, seems hard to define well
English

Free Cone Day is here! Come celebrate with us at a DQ location on today by getting a FREE small vanilla cone 🍦
English

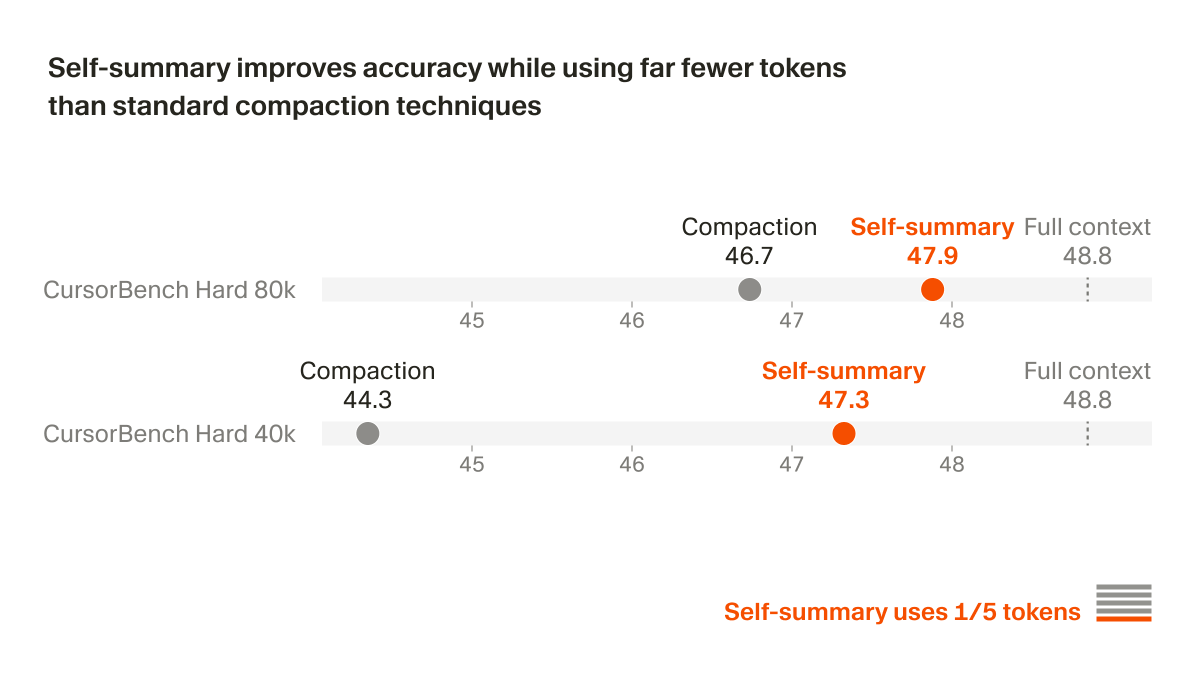
@cursor_ai 1/5 the tokens, nearly identical accuracy. The model learned what to keep and what to drop through RL - not a prompt telling it to summarize. That's the core lesson: instruction-following is fragile. Learned behavior holds under pressure.
English

Training the summarization behavior through RL instead of prompting it is the right call. Prompt-based compaction tells the model what to preserve — RL-trained summarization teaches it what actually matters for task completion. The 1/5 token usage while closing to within 1 point of full context on Hard 80k is the part that makes this production-viable, not just a research result.
English

@cursor_ai @shaoruu This is incredible, training context management through RL rather than prompting is the pattern I expect every serious agent framework to adopt. The model should learn what to remember, not be told what to remember.
English

@cursor_ai Interesting, but why not train the compaction turn itself by doing multiple rollouts using the summary and assigning the summary the average final coding task reward? I.e, a good summary should lead to good completion outcomes for the agent 1/2
English

@cursor_ai Using RL for self-summarization is a smart approach — prompts are brittle for something this critical. 50% error reduction is massive for long-running tasks. How does the training data scale with task complexity?
English

@cursor_ai this is huge for long running tasks. been hitting context limits on big refactors and this would fix like half my frustration with ai coding tools
English

@cursor_ai compaction was killing AudioWave's long agent sessions for months. the RL fix is right — a prompt guessing what to preserve vs training on actual outcomes are completely different signals. curious if this helps multi-file refactors or mainly linear task chains
English

@cursor_ai Impressive approach! Leveraging RL for self-summarization could really change the game for code-related tasks. Curious about how this impacts the balance between creativity and accuracy in generated solutions. Any insights on that? 🤔
English

@cursor_ai Great approach. I'm wondering how the Cursor team handles the cases of incorrect steps that need to be backtracked? Ideally these are scrubbed from context so they don't bloat the main thread with poor decisions off an otherwise solid approach.
English

It’s time to dance! Get it on tournament action with Bonus Bets from FanDuel.
English

@cursor_ai RL for self-summarization is the right move — the model learns what it needs to preserve to solve future tasks, not what a human thinks looks important. Prompt-based compaction is static; this adapts to the actual task distribution. Makes sense the error rate drops.
English

@cursor_ai training what to forget is a harder problem than training what to remember. prompts just punt the decision to the user
English

@cursor_ai knowing that Auto is going away post my year long subscription is driving me away from cursor... i am using it less and less where as initially i was using it for everything.. :(
English

@cursor_ai way more durable than any handcrafted compaction logic.
English

@cursor_ai 50% error reduction from one architectural decision. This is why "just add a better prompt" only gets you so far.
English

@cursor_ai training a model to know when its own context is getting too big instead of just prompting it is the kind of engineering that actually scales
English

@cursor_ai makes sense honestly. a prompt doesn't know which parts of context will matter 50 steps later.
rl can figure that out by failing first.
does this generalize to any long-context task or only where you have clean pass/fail signals like tests?
English

⚠️⚠️⚠️ Any tips how to recover "lost" chats?
Cursor just crashed on me and took 6 chats with itself, weirdly all from last week until today.
"Older" chats load fine.
Changes since last commit under version control are still visible.
There are a bunch of .jsonl files under /agent-transcripts that seem to map to those lost chats. Any way to import them back???
English

@cursor_ai cool approach. but isn't relying on RL risky? feels like it could lead to unpredictable outcomes in complex tasks.
English


RL-based summarization beats prompts because it learns from actual task outcomes, not just what a human thinks matters. The key insight: context management is the bottleneck, not model capability. Training on pass/fail signals teaches the model what to keep vs discard. This is why agent frameworks need to invest in environment design, not just bigger models.
English

Unscene is a location-based audio experience. Move through the world differently. As you walk, cycle, wander, or pause, you leave behind short voice recordings – tied to the places where they were spoken. An invisible archive of human thought.
English

@cursor_ai Been waiting for someone to solve compaction properly.
English

@cursor_ai So this is why long composer sessions have felt more stable lately. Good to see the data behind it.
English

@cursor_ai compaction has been the quiet failure mode for a while
English

@cursor_ai y’all been cooking up some seriously good sauce and really helping more people catch on to this.
English

@cursor_ai I am a student how I can get this free
North-west Frontier, Pakistan 🇵🇰 English