Naka-pin na Tweet

Announcing our $7.3M seed round!
TensorZero enables a data and learning flywheel for optimizing LLM applications: a feedback loop that turns production metrics and human feedback into smarter, faster, and cheaper models and agents.
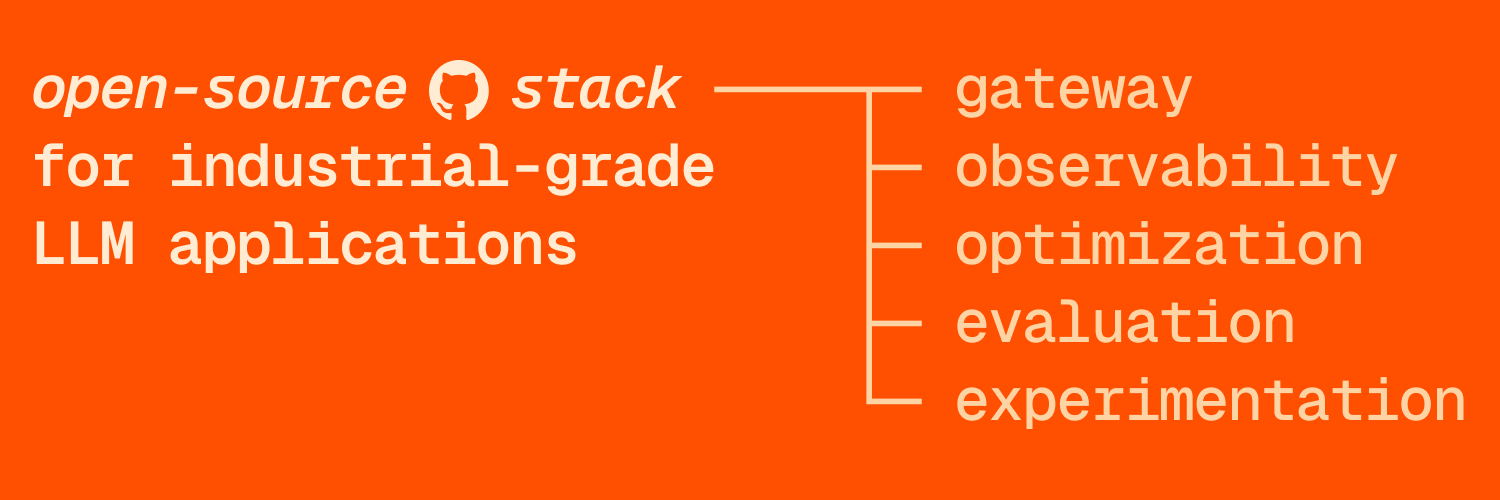
Today, we provide an open-source stack for building industrial-grade LLM applications that unifies an LLM gateway, observability, optimization, evaluation, and experimentation. You can take what you need, adopt incrementally, and complement with other tools. Over time, these components enable you to set up a principled feedback loop for your LLM application. The data you collect is tied to your KPIs, ports across model providers, and compounds into a competitive advantage for your business.
Our vision is to automate much of LLM engineering. We're laying the foundation for that with open-source TensorZero. For example, with our data model and end-to-end workflow, we will be able to proactively suggest new variants (e.g. a new fine-tuned model), backtest it on historical data (e.g. using diverse techniques from reinforcement learning), enable a gradual, live A/B test, and repeat the process. With a tool like this, engineers can focus on higher-level workflows — deciding what data goes in and out of these models, how to measure success, which behaviors to incentivize and disincentivize, and so on — and leave the low-level implementation details to an automated system. This is the future we see for LLM engineering as a discipline.
Recently, TensorZero reached #1 trending repository of the week globally on GitHub (& we're about to cross 10k stars). We're fortunate to have received contributions from dozens of developers worldwide, and it's exciting to see TensorZero already powering cutting-edge LLM products at frontier AI startups and large organizations, including one of Europe's largest banks.
We're excited to share that we've raised $7.3M to accelerate TensorZero's efforts to build best-in-class open-source infrastructure for LLM engineers (we're hiring!). The round was led by @FirstMarkCap, with participation from @BessemerVP, @bedrock, @DRWTrading, @coalitionvc, and dozens of strategic angels.

English