Naka-pin na Tweet

Comparing Git branching strategies
#DEVCommunity #git #github #gitflow #tbd #githubflow #versioncontrol #sourcecode #development
dev.to/arbitrarybytes…
English
Vaibhav Sharma
8.6K posts

@arbitrarybytes
Certified Azure Architect | Technology enthusiast | Space hobbyist




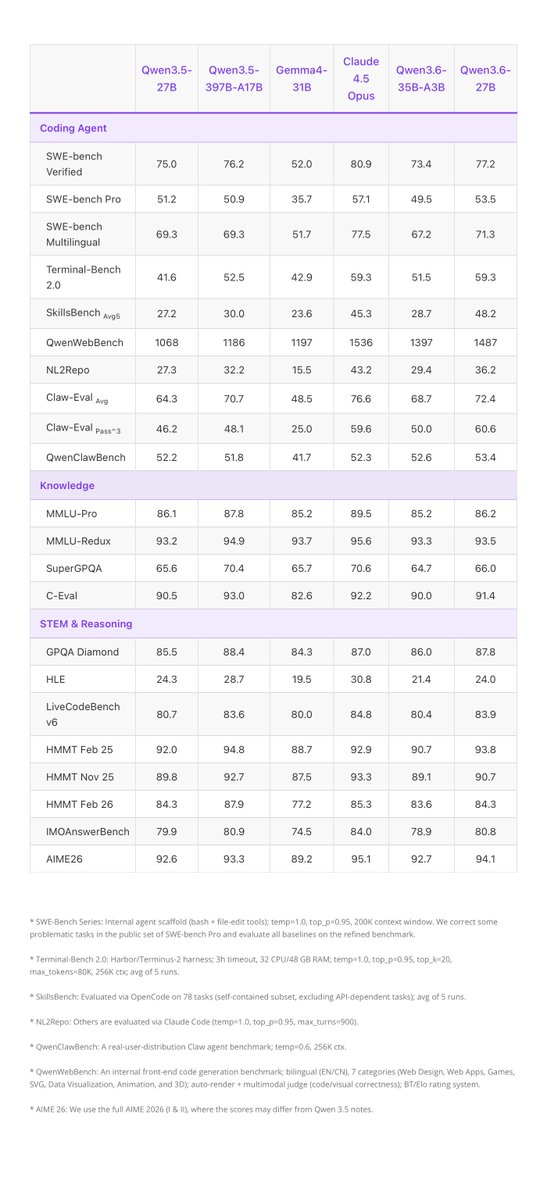

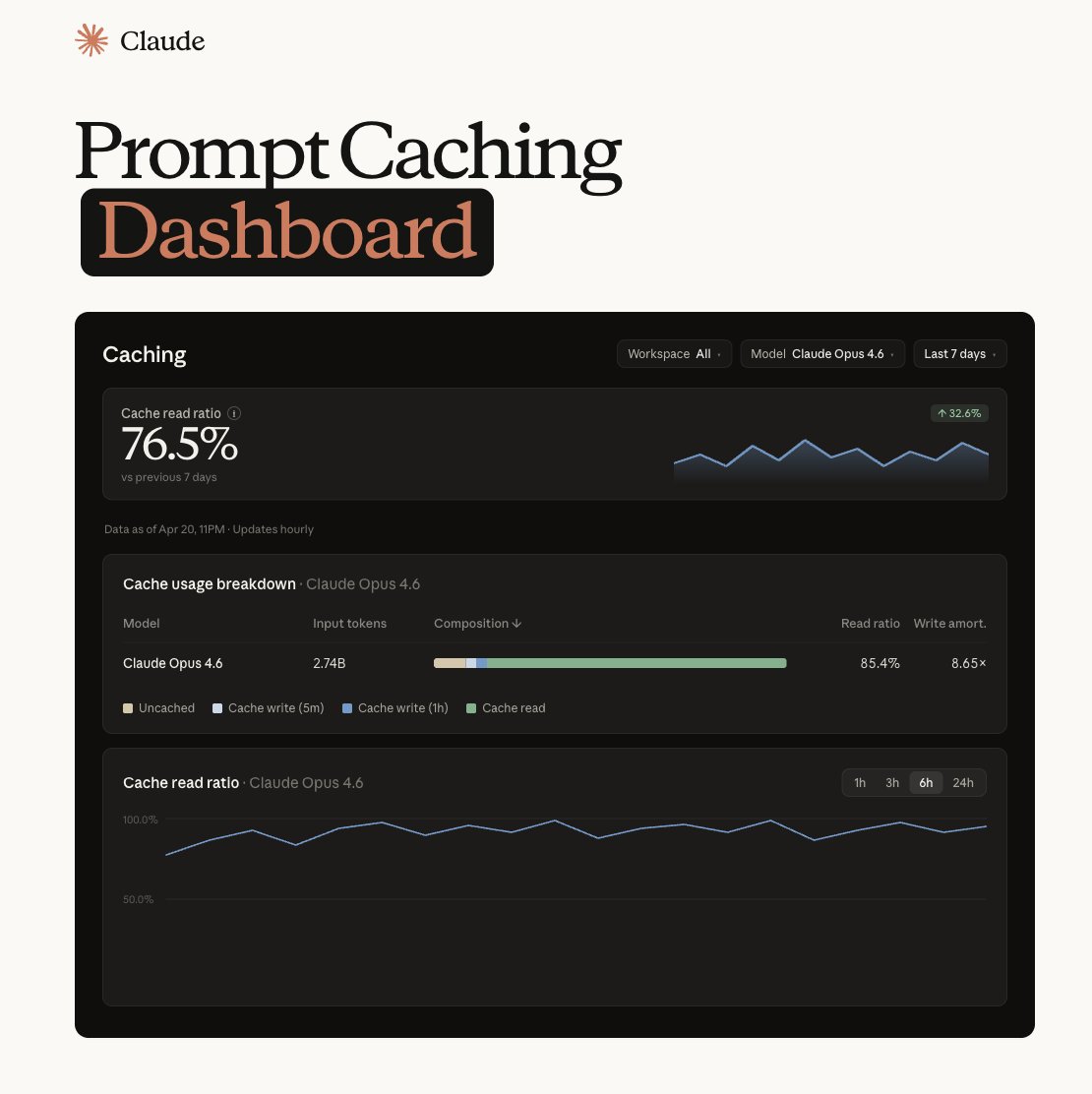






LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below




