Simone Romano ⚗️👁️💭🏕️ nag-retweet
Simone Romano ⚗️👁️💭🏕️
5.8K posts


Simone Romano ⚗️👁️💭🏕️
@ialuronico
🖤 machine learning products. X-(Bigtech+, researcher)
Helsinki, Finland Sumali Ocak 2008
4.9K Sinusundan1.2K Mga Tagasunod

The Random Forest of the 2030s? open.substack.com/pub/mindfulmod…
English
I made a MCP and a bot for Polymarket.
Here is the source code: github.com/simoroma/polym…
Feel free to use it.
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
pub.sakana.ai/DroPE/
We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning.
The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences.
Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity.
Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch.
Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training.
We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER.
We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs.
Paper: arxiv.org/abs/2512.12167
Code: github.com/SakanaAI/DroPE
GIF
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Vending Machines... It's quite absurd how big this got. From an obscure arXiv paper to vending machines with thousands of AI researchers using them worldwide. @AnthropicAI just made a second post, and we celebrate it with some behind-the-scenes of Project Vend history 🧵.
Anthropic@AnthropicAI
You might remember Project Vend: an experiment where we (and our partners at @andonlabs) had Claude run a shop in our San Francisco office. After a rough start, the business is doing better. Mostly.
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Camera angle control with AI images continues to be a challenge.
With Qwen Image Edit, currently on Huggingface, it aims to solve this problem.
From a single image, you can rotate the camera around and keep consistency.
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Researchers have mathematically proven that the universe cannot be a computer simulation.
Their paper in the Journal of Holography Applications in Physics shows that reality operates on principles beyond computation.
Using Gödel’s incompleteness theorem, they argue that no algorithmic or computational system can fully describe the universe, because some truths, so called "Gödelian truths" require non algorithmic understanding, a form of reasoning that no computer or simulation can reproduce.
Since all simulations are inherently algorithmic, and the fundamental nature of reality is non algorithmic, the researchers conclude that the universe cannot be, and could never be a simulation.

English
An agent that acts on your behalf clicking on the browser! techcommunity.microsoft.com/blog/microsoft…
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

That blue node moving through the codebase?... That's Claude Code.
Found this video on youtube of the entire claude-code-templates development on GitHub - every commit, community PR, and file change from the git logs mapped out.
Seeing an AI agent navigate the dependency graph and ship features is wild 🤯
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Simone Romano ⚗️👁️💭🏕️ nag-retweet

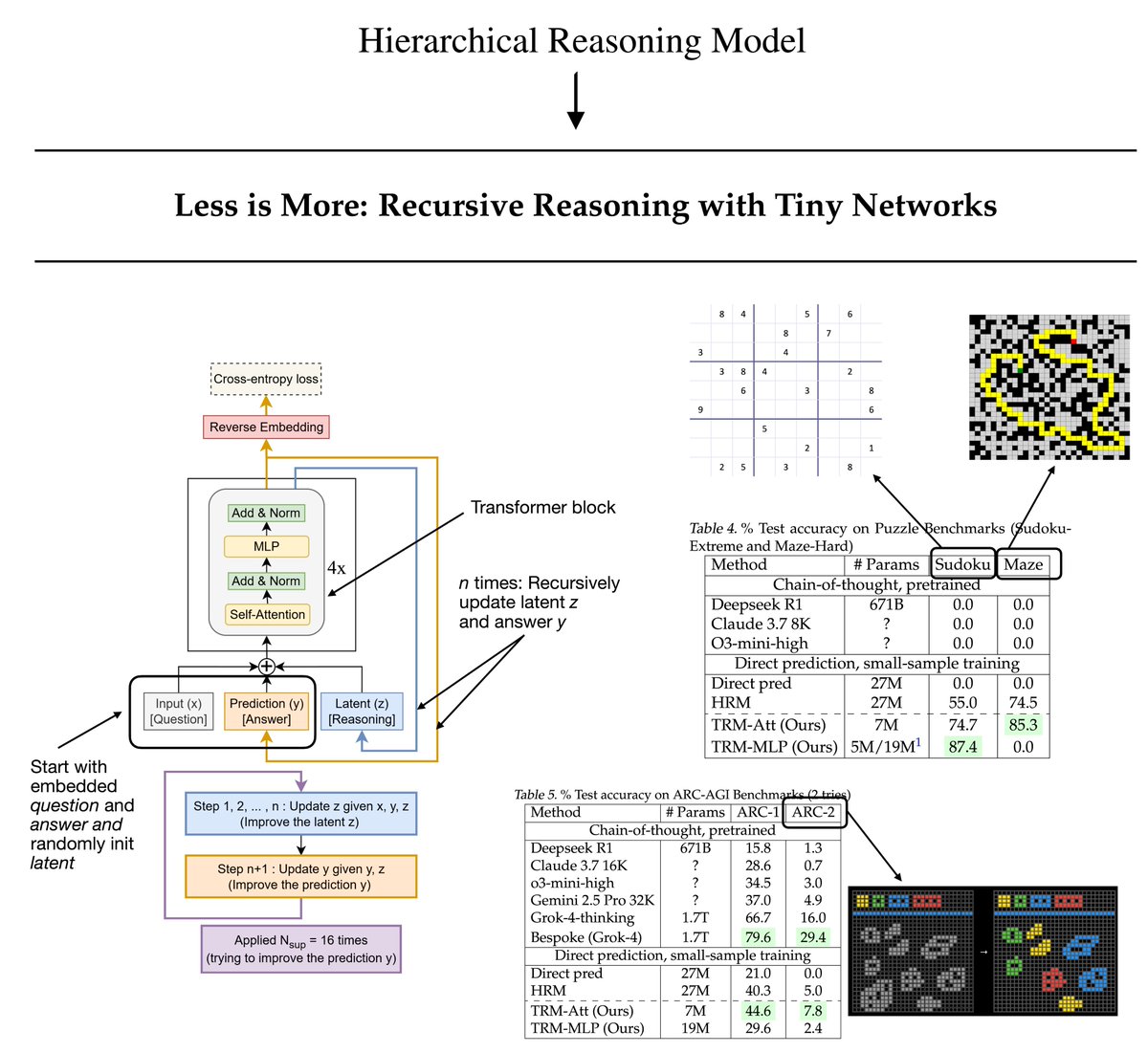
From the Hierarchical Reasoning Model (HRM) to a new Tiny Recursive Model (TRM).
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)
Now, the new "Less is More: Recursive Reasoning with Tiny Networks" paper proposes Tiny Recursive Model (TRM), which a simpler and even smaller model (7M, 4× smaller than HRM) that performs even better on the ARC challenge.
🔹 What does recursion mean here?
TRM refines its answer in two steps:
1. It updates a latent (reasoning) state from the current question and answer.
2. Then it updates the answer based on that latent state.
Training runs for up to 16 refinement steps per batch. Each step does several no-grad loops to improve the answer, followed by one gradient loop that learns from the full reasoning process.
By the way, the question and the answer are grids of discrete tokens, not text. (E.g., 9×9 Sudoku and up to 30×30 ARC and Maze.)
🔹 And how does it differ from HRM?
In short, HRM recurses multiple times through two small neural nets with 4 transformer blocks each (high and low frequency). TRM is much smaller (i.e., 4x) and only a single network with 2 transformer blocks.
TRM backpropagates through the full recursion once per step, whereas HRM only backpropagates through the final few steps. And TRM also removes HRM's extra forward pass for halting and instead uses a simple binary cross-entropy loss to learn when to stop iterating.
🔹 Surprising tidbits
1. The author found that adding layers decreased generalization due to overfitting. And going from 4 to 2 layers improved the model from 79.5% to 87.4% on Sudoku.
2. Replacing the self-attention layer with an MLP layer also improved accuracy (74.7% -> 87.4% on Sudoku); however, note that this only make sense here since we have a fixed-length, small context to work with.
🔹 Bigger picture
My personal caveat: comparing this method (or HRMs) to LLMs feels a bit unfair since HRMs/TRM are specialized models trained for specific tasks (here: ARC, Sudoku, and Maze pathfinding) while LLMs are generalists. It’s like comparing a pocket calculator to a laptop. Both serve a purpose, just in different contexts.
That said, HRMs and the recursive model proposed here are fascinating proof‑of‑concepts that show what’s possible with relatively small and efficient architectures. I'm still curious what the real‑world use case will look like. Maybe they could serve as reasoning or planning modules within a larger tool‑calling system.
In practice, we often start by throwing LLMs at a problem, which makes sense for quick prototyping and establishing a baseline. But I can see a point where someone sits down afterward and trains a focused model like this to solve the same task more efficiently.
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

Serving Large Language Models on Huawei CloudMatrix384
- Integrates 384 Ascend 910C NPUs, interconnected via an ultra-high-bandwidth, low-latency UB network, optimized for large-scale MoE and distributed KV cache access
- DeepSeek-R1 on CloudMatrix-Infer hits 2k tokens/s decode per NPU

English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

@Dr_Singularity “7M parameters achieve 45% on ARC-AGI”?
Not exactly.
1000× data augmentation
1000× ensemble voting
3.75× recursive compute
That’s 7M × 480,000 forward passes — not tiny, just time-hungry.
The result isn’t less is more, it’s more is more at test time.
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet
This is insane.
New AI model from Samsung, 10,000x smaller than DeepSeek and Gemini 2.5 Pro just beat them on ARC-AGI 1 and 2
Samsung’s Tiny Recursive Model (TRM) is about 10,000x smaller than typical LLMs yet smarter because it thinks recursively instead of just predicting text. It first drafts an answer, then builds a hidden "scratchpad" for reasoning, repeatedly critiques and refines its logic (up to 16 times), and produces improved answers each cycle.
This approach shows that architecture and reasoning loops (not just size), can drive intelligence. It enables powerful, efficient models that run cheaply, validate neuro symbolic ideas, and open highest quality reasoning to far more applications.
Acceleration is everywhere

Jackson Atkins@JacksonAtkinsX
My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how it works: 1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess. 2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens. 3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?" 4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer. 5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution. Why this matters: Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost. Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability. Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere. This isn't just scaling down; it's a completely different, more deliberate way of solving problems.
English
Course Description:
For decades, a primary contribution in systems research has been the meticulous, human-driven design. We are now at the beginning of a significant shift, where a new class of AI tools can autonomously generate algorithms ucbsky.github.io/ucbsky-cs294-2…
English
Proud to back Exogene which is working on cancer treatments using personalised combinations of medicines, designed with AI.
Check out Exogene's investment campaign on Crowdcube: crowdcube.com/companies/exog…
English
🧬 Zero to One in Cancer: The Real AI Revolution open.substack.com/pub/federicopa…
English
Google’s Nano Banana is the start of a Massive AI Trend [Markets] open.substack.com/pub/artificial…
English
Simone Romano ⚗️👁️💭🏕️ nag-retweet

If you think @Apple is not doing much in AI, you're getting blindsided by the chatbot hype and not paying enough attention!
They just released FastVLM and MobileCLIP2 on @huggingface. The models are up to 85x faster and 3.4x smaller than previous work, enabling real-time vision language model (VLM) applications! It can even do live video captioning 100% locally in your browser 🤯🤯🤯
English